
InternGPT入门学习资料汇总 - 开源多模态AI交互演示平台
InternGPT(iGPT)是一个开源的多模态AI交互演示平台,允许用户通过指向、拖拽和绘画等方式与ChatGPT等AI模型进行交互。本文汇总了InternGPT的入门学习资料,帮助读者快速了解和使用这个强大的AI交互工具。
📚 项目简介
InternGPT的名称代表了交互(Interaction)、非语言(Nonverbal)和ChatGPT。它是一个基于指向语言驱动的视觉交互系统,允许用户通过点击、拖拽和绘画等方式与ChatGPT进行交互。
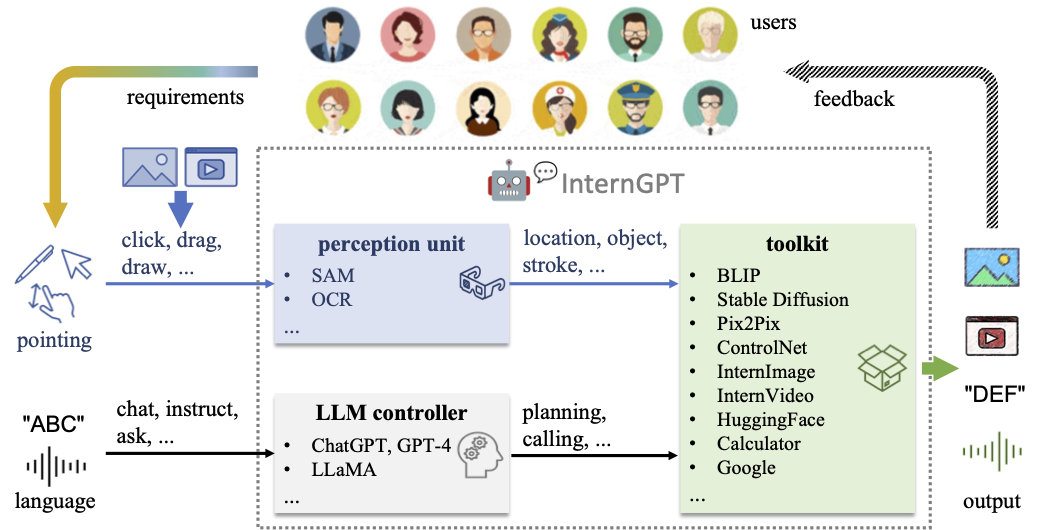
主要特点:
- 支持多种AI模型:DragGAN、ChatGPT、ImageBind、SAM等
- 交互方式丰富:点击、拖拽、绘画等
- 多模态对话:图像、文本、音频等多模态输入
- 视觉任务处理:图像编辑、生成、分割等
🔗 重要链接
- GitHub仓库: OpenGVLab/InternGPT
- 在线演示: https://igpt.opengvlab.com
- 技术论文: InternGPT论文
🛠️ 安装教程
详细的安装步骤请参考项目中的INSTALL.md文件。
基本步骤:
- 克隆仓库
- 安装依赖
- 下载预训练模型
- 运行应用
🚀 快速开始
运行以下命令可以启动InternGPT的基本功能:
python -u app.py --load "HuskyVQA_cuda:0,SegmentAnything_cuda:0,ImageOCRRecognition_cuda:0" --port 3456 -e
如果想启用全部功能,可以运行:
python -u app.py \
--load "ImageOCRRecognition_cuda:0,Text2Image_cuda:0,SegmentAnything_cuda:0,ActionRecognition_cuda:0,VideoCaption_cuda:0,DenseCaption_cuda:0,ReplaceMaskedAnything_cuda:0,LDMInpainting_cuda:0,SegText2Image_cuda:0,ScribbleText2Image_cuda:0,Image2Scribble_cuda:0,Image2Canny_cuda:0,CannyText2Image_cuda:0,StyleGAN_cuda:0,Anything2Image_cuda:0,HuskyVQA_cuda:0" \
-p 3456 --https -e
📖 使用指南
InternGPT支持多种交互方式,主要功能包括:
-
多模态对话:上传图片后,可以进行基于图像的问答。
-
交互式图像编辑:
- 点击图像并按"Pick"按钮可视化分割区域
- 点击图像并按"OCR"按钮识别文字
- 发送"remove the masked region"移除遮罩区域
- 发送"replace the masked region with {your prompt}"替换遮罩区域
-
图像生成:发送"generate a new image based on its segmentation describing {your prompt}"生成新图像
-
基于音频的图像生成:上传音频文件,然后发送相关指令生成图像
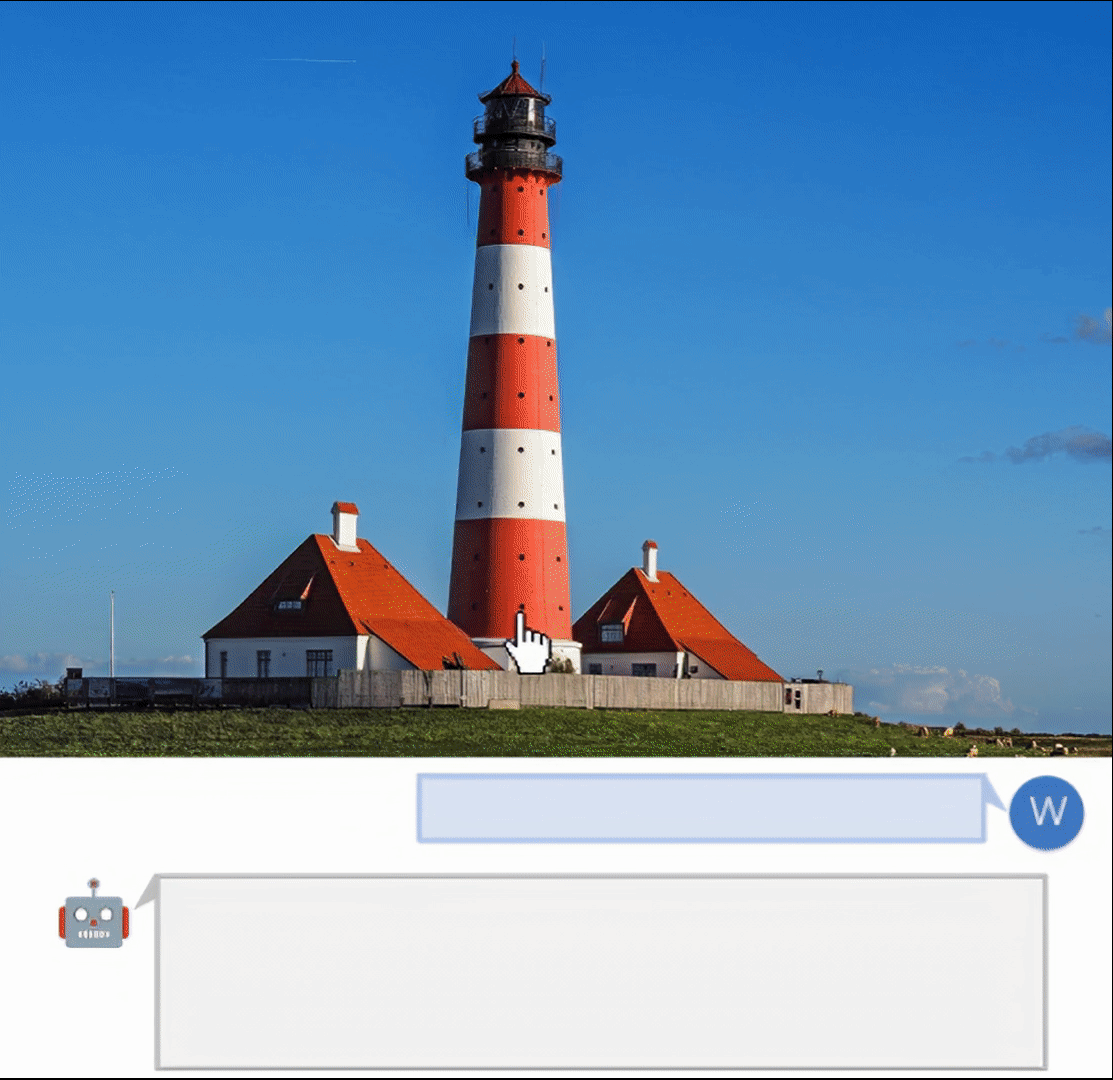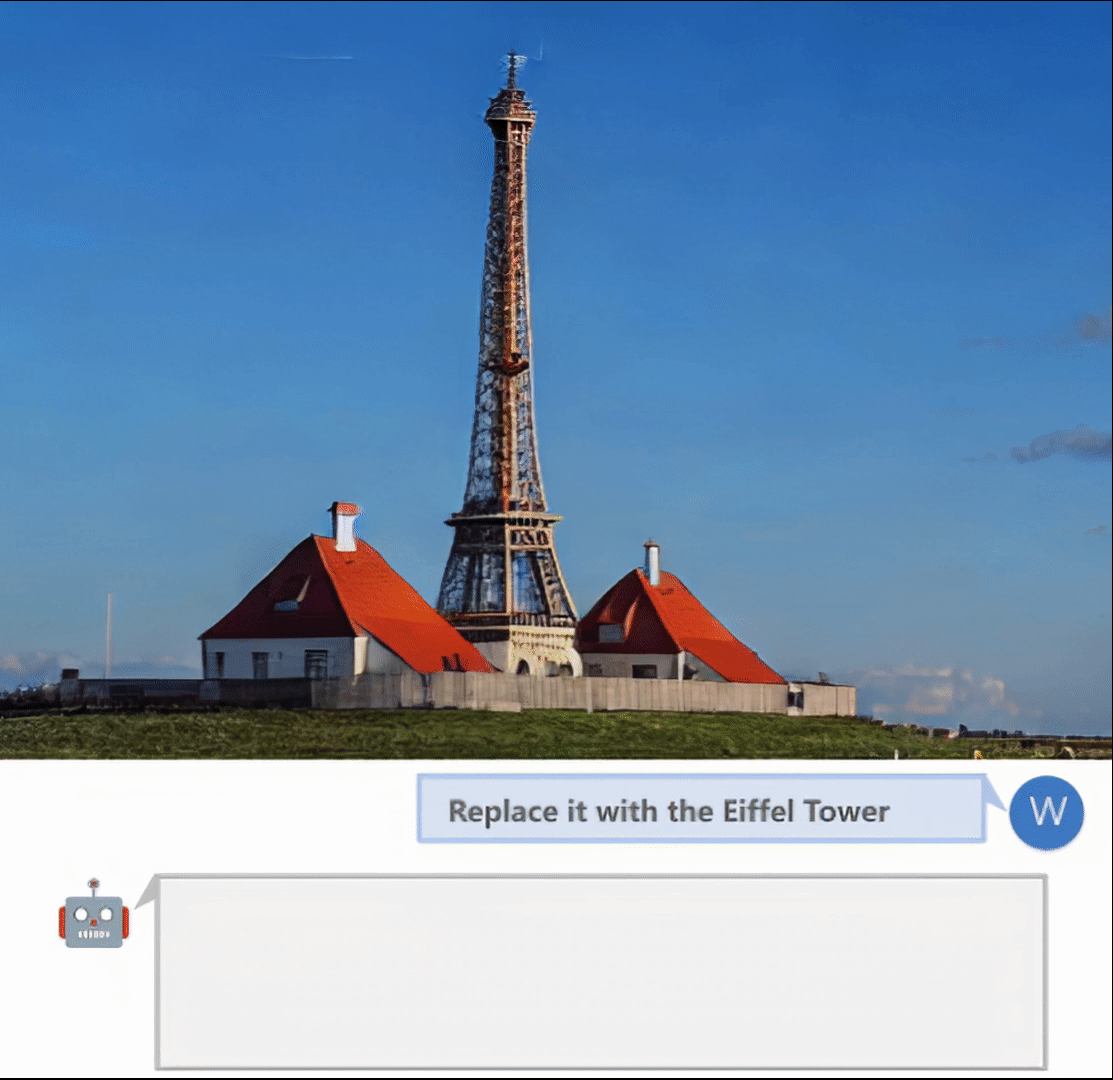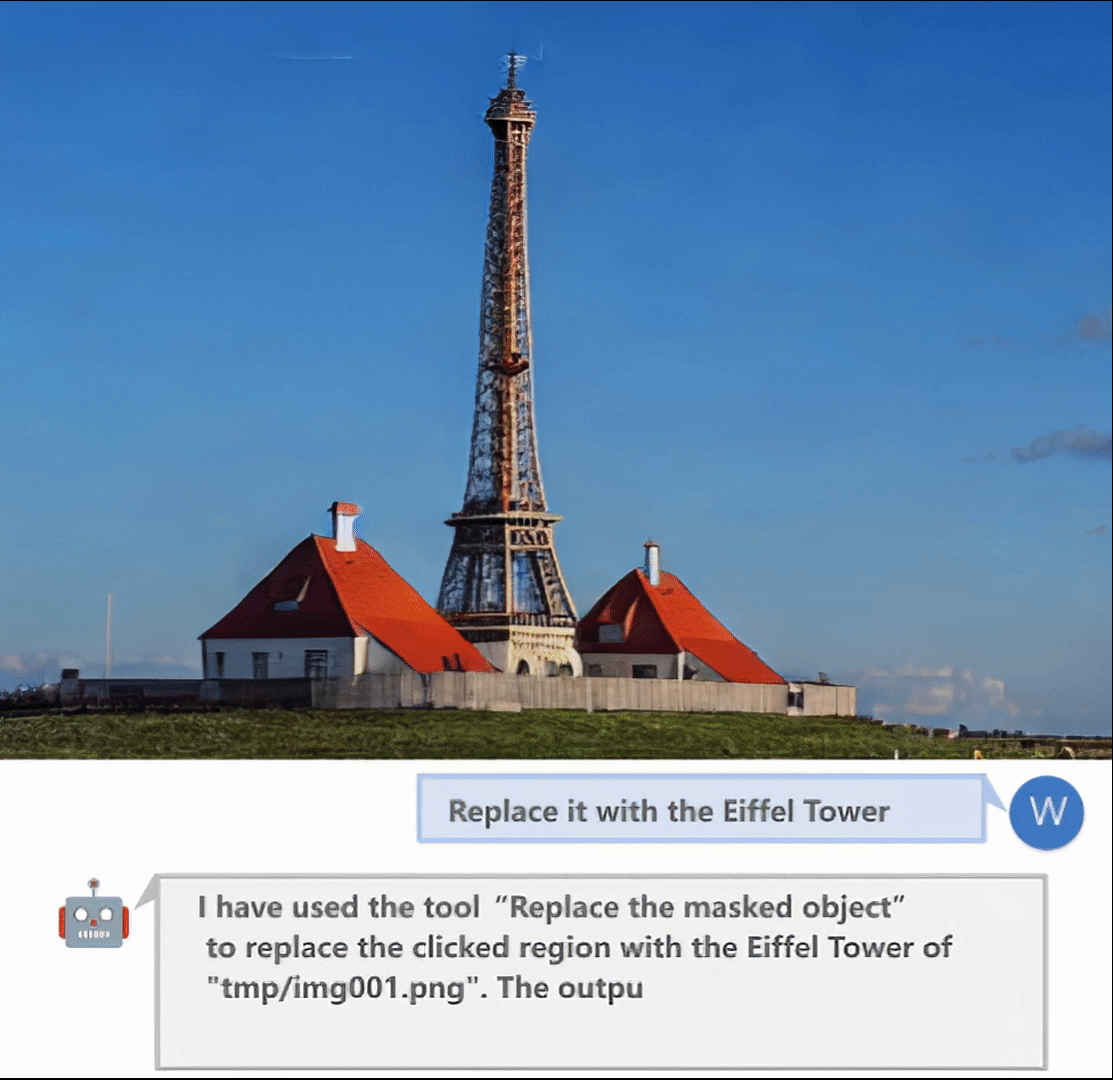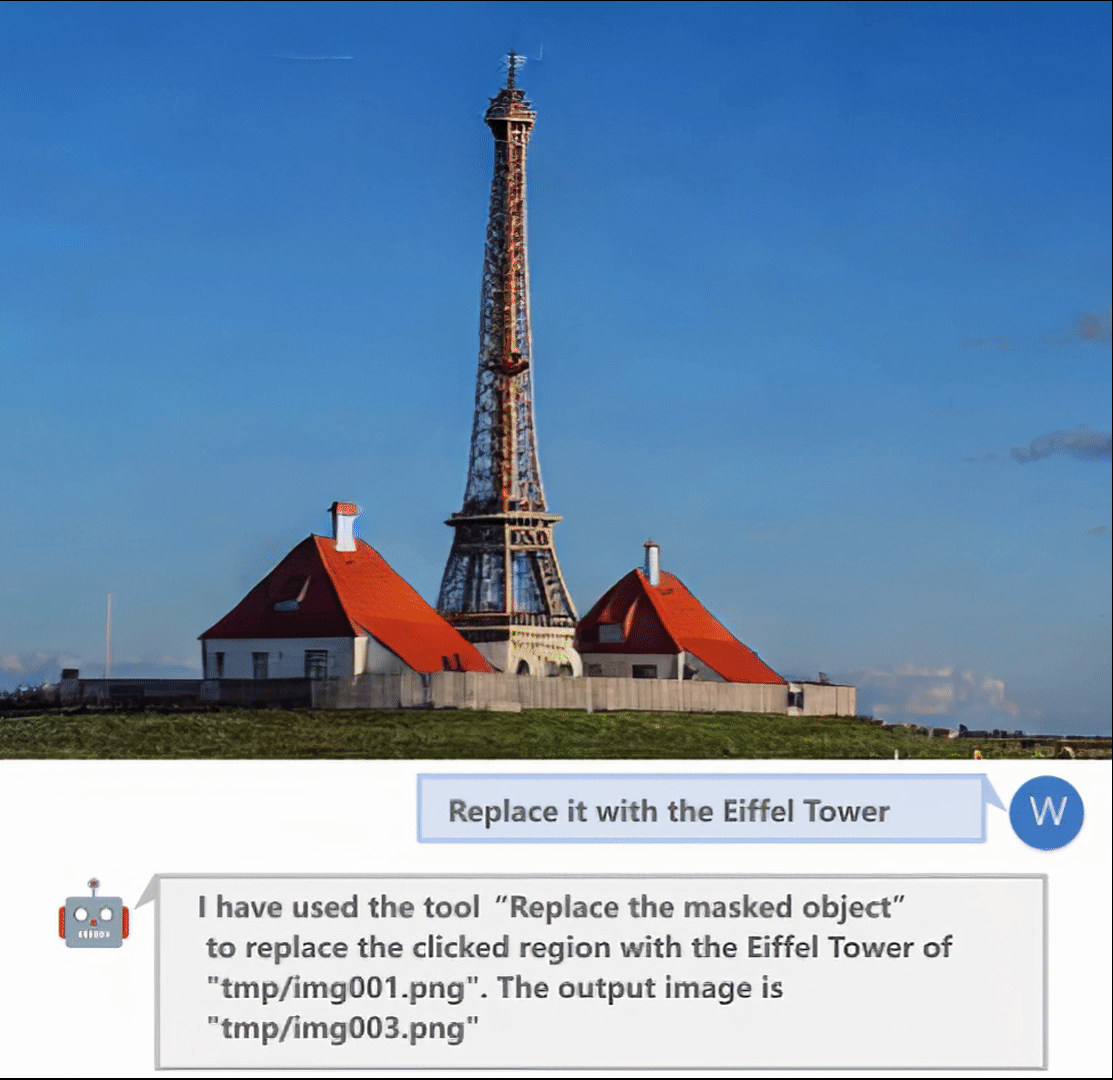
更多详细用法请参考项目README中的User Manual部分。
🤝 参与贡献
InternGPT是一个开源项目,欢迎社区贡献:
- 提交Issue报告bug或提出新功能建议
- 提交Pull Request贡献代码
- 参与讨论,提供使用反馈
📚 更多资源
- Hugging Face空间:可以在线体验和复制项目
- 模型库:包含HuskyVQA等预训练模型
- DragGAN项目:InternGPT集成的图像编辑模型
- ImageBind项目:InternGPT支持的多模态AI模型
InternGPT为AI爱好者和研究人员提供了一个强大的多模态交互平台。通过本文的学习资料汇总,相信读者可以快速上手并探索InternGPT的各种有趣功能。欢迎大家亲身体验这个开源项目,感受AI技术的魅力!










