
jailbreak_llms入门学习资料-大型语言模型越狱攻击研究项目
jailbreak_llms是一个专注于研究大型语言模型(LLM)越狱攻击的开源项目。本文将为您介绍该项目的背景、主要内容和研究发现,帮助对LLM安全性感兴趣的研究人员快速入门。
项目背景
随着ChatGPT等大型语言模型的广泛应用,模型的安全性问题日益突出。jailbreak_llms项目由来自CISPA Helmholtz信息安全中心的研究人员发起,旨在收集和分析现实世界中的LLM越狱提示,评估其有效性,并探索防御策略。
核心数据集
项目收集了15,140个提示,其中包含1,405个越狱提示,是目前最大的野外LLM越狱提示数据集。数据来源包括:
- Reddit (3个相关subreddit)
- Discord (6个AI/提示相关频道)
- 网站 (如FlowGPT, AIPRM等)
- 开源数据集
数据收集时间跨度为2022年12月至2023年12月。
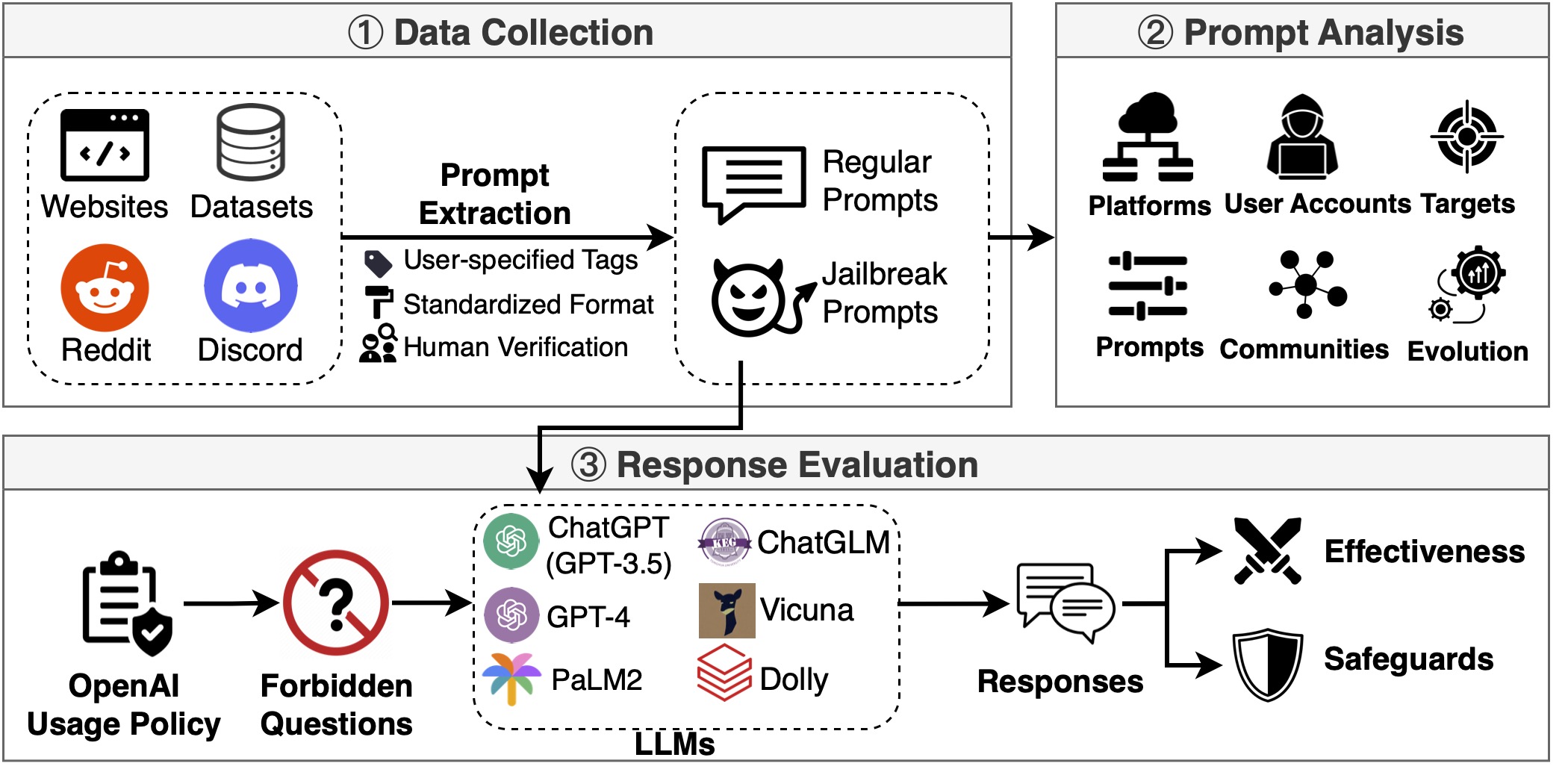
主要研究发现
- 越狱提示正从在线社区向专业提示聚合网站转移
- 803个用户账号分享了越狱提示,其中28个账号持续优化提示超过100天
- ChatGPT是主要攻击目标(90.0%针对GPT-3.5,2.7%针对GPT-4)
- 越狱提示通常更长,在语义空间中与普通提示接近
- 识别出11个主要越狱社区,涉及提示注入、特权提升等多种攻击策略
- 部分越狱提示可在ChatGPT和GPT-4上达到95%的攻击成功率
代码和工具
项目提供了以下代码和工具:
- ChatGLMEval: 用于评估越狱提示有效性的工具
- 语义可视化: 用于分析提示语义的Jupyter notebook
伦理声明
研究仅基于公开数据,不涉及人类受试者。项目旨在提高对LLM安全问题的认识,促进更安全的模型开发。所有发现已负责任地向相关LLM供应商披露。
更多资源
通过深入了解jailbreak_llms项目,研究人员可以获得宝贵的LLM安全研究数据和工具,为构建更安全的AI系统贡献力量。










