
突破性成本效益的大语言模型
在人工智能领域,大语言模型(LLM)的发展一直伴随着巨额的训练成本。然而,近期由MyShell、麻省理工学院、MIT-IBM Watson AI实验室和普林斯顿大学的研究人员共同开发的JetMoE-8B模型,正在改变人们对LLM训练成本的认知。
JetMoE-8B以不到100万美元的成本,在性能上超越了Meta AI耗资数十亿美元开发的Llama2-7B模型。这一突破性成果表明,大语言模型的训练可能比人们之前认为的要经济高效得多。
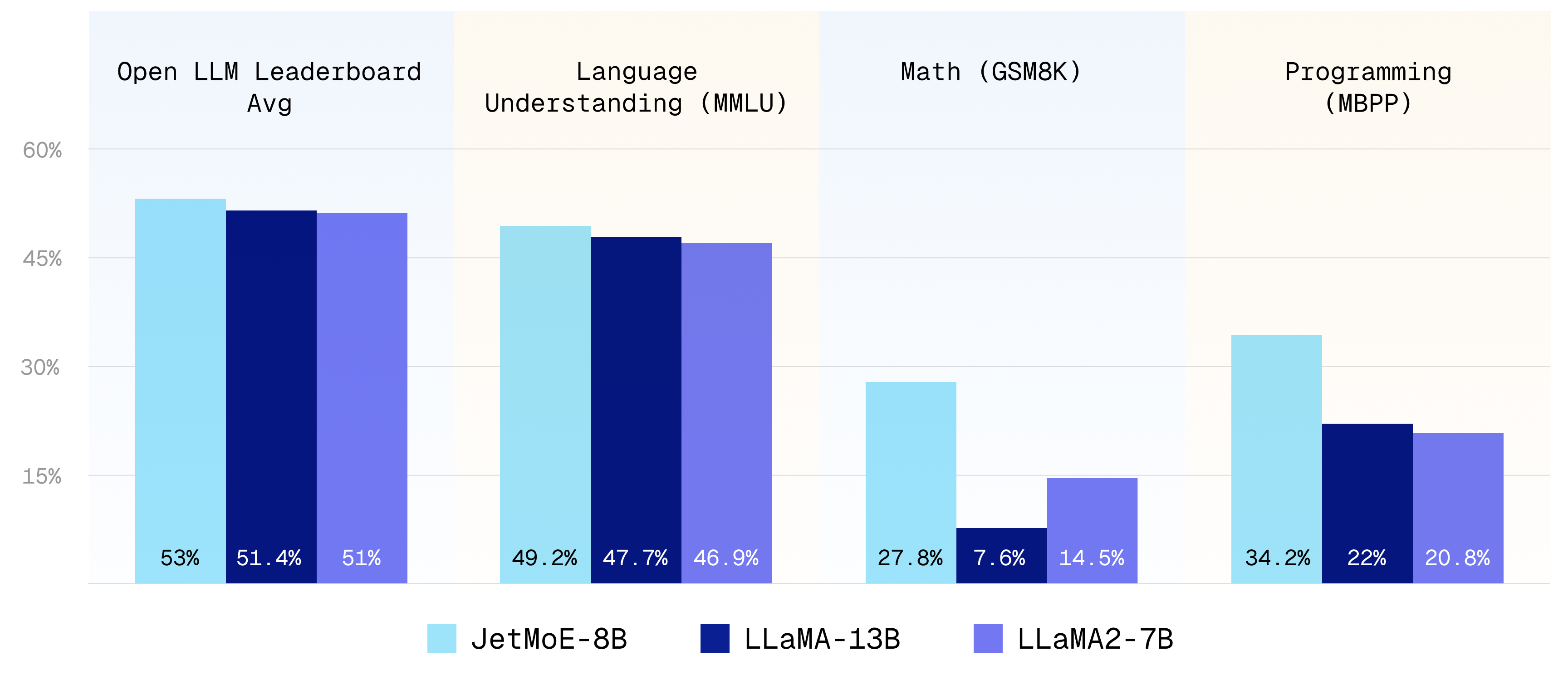
图1: JetMoE-8B与其他主流大语言模型的性能对比
JetMoE的核心优势
1. 卓越的成本效益
JetMoE-8B仅使用了96个H100 GPU集群进行了两周的训练,总成本约为8万美元。相比之下,许多顶级大语言模型的训练成本通常在数千万到数亿美元之间。这种显著的成本降低可能会彻底改变AI研究和应用的格局。
2. 开源友好
JetMoE-8B完全开源,并且对学术界非常友好:
- 仅使用公开数据集进行训练,代码也已开源。不需要任何专有资源。
- 可以使用有限的计算资源(如消费级GPU)进行微调,大多数实验室都能负担得起。
这种开放性为更广泛的研究社区参与大语言模型的开发和改进创造了条件。
3. 高效的推理性能
尽管JetMoE-8B的总参数量为80亿,但在推理过程中仅激活2.2亿参数。这种设计大大降低了计算成本,使得模型在实际应用中更加高效。与类似推理计算量的Gemma-2B相比,JetMoE-8B在各项性能指标上都表现得更好。
技术创新:混合专家(MoE)架构
JetMoE-8B采用了创新的稀疏门控混合专家(Sparsely-gated Mixture-of-Experts, SMoE)架构。这种架构由注意力专家和前馈专家组成,两种层都是稀疏激活的。这意味着在处理每个输入token时,只有部分专家会被激活。
具体来说,JetMoE-8B虽然总参数量为80亿,但每次只激活20亿参数。与Llama2-7B相比,这种设计将推理计算量减少了约70%。这不仅提高了模型的效率,还使得JetMoE在有限的计算资源下也能实现出色的性能。
全面的性能评估
研究团队使用了与Open LLM排行榜相同的评估方法,对JetMoE-8B进行了全面的性能测试。结果显示,JetMoE-8B在多个基准测试中表现出色:
- 在Open LLM排行榜平均分上,JetMoE-8B得分为53.0,超过了Llama2-7B的51.0和Llama-13B的51.4。
- 在MMLU(多任务语言理解)测试中,JetMoE-8B得分49.2,高于Llama2-7B的46.9和Llama-13B的47.7。
- 在TruthfulQA测试中,JetMoE-8B得分41.7,显著高于Llama2-7B的38.8和Llama-13B的39.5。
- 在GSM8k数学推理测试中,JetMoE-8B得分27.8,远超Llama2-7B的14.5和Llama-13B的7.6。
这些结果表明,JetMoE-8B不仅在整体性能上超越了更大的模型,在特定任务上的表现更是令人瞩目。
对AI领域的影响
JetMoE-8B的成功开发可能对AI领域产生深远影响:
-
降低入门门槛: 较低的训练成本使得更多研究机构和企业有机会参与到大语言模型的开发中来,促进AI技术的民主化。
-
加速创新: 更经济的训练方法允许研究人员更频繁地进行实验和迭代,可能加速AI技术的进步。
-
扩大应用范围: 高效的推理性能使得JetMoE类模型更容易部署在资源受限的环境中,如移动设备或边缘计算设备,拓展了AI应用的场景。
-
推动开源发展: JetMoE的开源性质为AI社区提供了宝贵的学习和研究资源,有助于推动整个领域的开放协作。
未来展望
尽管JetMoE-8B取得了令人印象深刻的成果,但研究团队表示这仅仅是开始。他们计划进一步优化模型架构,探索更高效的训练方法,以及扩展模型规模,以达到更高的性能水平。
同时,研究团队也呼吁更多的合作。MyShell.ai表示,他们欢迎有创新想法但缺乏资源(如GPU、数据、资金等)的研究者与他们联系,共同推进大语言模型的发展。
结语
JetMoE-8B的成功不仅是一个技术突破,更代表了AI研究方向的一次重要转变。它证明了高性能大语言模型的开发不必局限于拥有海量资源的科技巨头,也为AI技术的普及和应用提供了新的可能性。
随着JetMoE等高效模型的出现,我们可以期待看到更多创新性的AI应用涌现,推动各行各业的智能化转型。未来,AI技术的发展可能会更加开放、民主和多元化,为解决人类面临的各种挑战提供强大的工具和解决方案。









