
LAMP:开创少样本视频生成新纪元
在人工智能和计算机视觉领域,视频生成一直是一个充满挑战但又极具前景的研究方向。近日,来自中国的研究团队提出了一种名为LAMP(Learn A Motion Pattern)的创新方法,为少样本视频生成开辟了新的可能性。本文将深入介绍LAMP的核心理念、技术特点以及潜在应用,带领读者一探这项革命性技术的魅力。
LAMP的核心思想
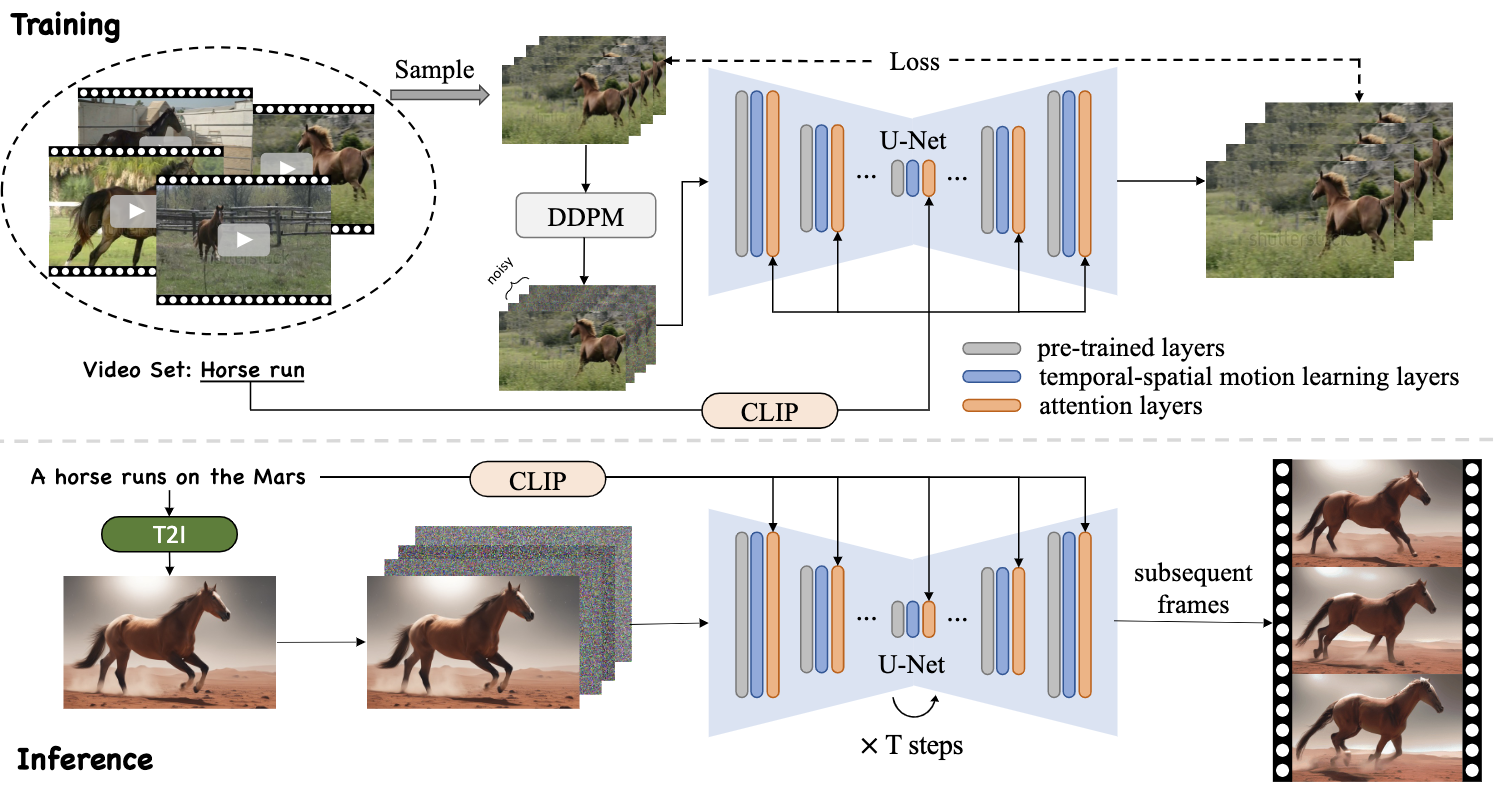
LAMP的全称是"Learn A Motion Pattern for Few-Shot Video Generation",即"学习运动模式的少样本视频生成"。顾名思义,这种方法的核心在于从少量样本视频中提取并学习运动模式,然后将这些模式应用于新的视频生成任务中。
与传统的视频生成方法相比,LAMP最大的优势在于其"少样本"的特性。通常情况下,训练一个高质量的视频生成模型需要大量的视频数据和计算资源。而LAMP只需要8-16个视频样本和一个GPU(显存大于15GB)就能完成训练,大大降低了门槛,使得个人开发者和小型研究团队也能轻松尝试视频生成技术。
LAMP的技术特点
- 基于文本的视频生成
LAMP采用了文本到视频(Text-to-Video)的生成模式。用户只需输入一段描述性文本,系统就能生成与之相匹配的视频内容。这种方式极大地提高了视频生成的灵活性和可控性。
- 运动模式学习
LAMP的核心在于其独特的运动模式学习机制。系统能够从少量的样本视频中提取出关键的运动特征,并将这些特征泛化应用到新的场景中。这使得生成的视频能够保持连贯的动作和自然的运动效果。
- 与预训练模型的结合
LAMP巧妙地利用了现有的预训练模型,如Stable Diffusion v1.4。这种结合既保证了生成视频的质量,又大大减少了训练所需的时间和资源。
- 多样化的应用场景
从实验结果来看,LAMP在多种运动模式的学习和生成上都表现出色,包括但不限于:
- 马匹奔跑
- 烟花绽放
- 吉他演奏
- 鸟类飞行
- 人物舞蹈
这种多样性为LAMP在不同领域的应用奠定了基础。
LAMP的使用方法
对于想要尝试LAMP的研究者和开发者,以下是一个简要的使用指南:
-
环境准备
- Ubuntu 18.04+
- CUDA 11.3
- Python 3.8
-
安装依赖
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113 pip install -r requirements.txt pip install xformers==0.0.13 -
数据准备
- 下载预训练的Stable Diffusion v1.4模型
- 准备8-16个用于学习运动模式的视频样本
-
训练
CUDA_VISIBLE_DEVICES=X accelerate launch train_lamp.py config="configs/horse-run.yaml" -
推理
python inference_script.py --weight ./my_weight/turn_to_smile/unet --pretrain_weight ./checkpoints/stable-diffusion-v1-4 --first_frame_path ./benchmark/turn_to_smile/head_photo_of_a_cute_girl,_comic_style.png --prompt "head photo of a cute girl, comic style, turns to smile"
LAMP的应用前景
LAMP的出现为视频生成领域带来了新的可能性,其潜在的应用场景包括但不限于:
-
创意内容制作 LAMP可以帮助创意工作者快速生成概念视频,为广告、电影等行业提供灵感和原型。
-
教育培训 通过生成各种场景的视频,LAMP可以为教育培训提供丰富的视觉材料,提升学习效果。
-
游戏开发 游戏开发者可以利用LAMP快速生成游戏中的动画场景,加速开发进程。
-
视觉效果(VFX) 电影和电视制作可以使用LAMP生成初步的视觉效果,为后期制作提供参考。
-
虚拟现实(VR)和增强现实(AR) LAMP生成的视频可以为VR和AR内容创作提供基础素材,丰富用户体验。
LAMP的局限性与未来发展
尽管LAMP在少样本视频生成方面取得了突破性进展,但它仍然存在一些局限性:
-
视频质量的进一步提升 虽然LAMP能生成连贯的视频,但在细节和真实感方面还有提升空间。
-
更复杂场景的处理 目前LAMP主要处理相对简单的运动模式,对于复杂的多物体交互场景还需要进一步研究。
-
计算资源的优化 尽管比传统方法更高效,LAMP仍需要较高的GPU配置,未来可以探索如何在更低配置的设备上运行。
-
与其他AI技术的结合 将LAMP与自然语言处理、计算机视觉等其他AI技术结合,可能会产生更强大的创作工具。
展望未来,LAMP的发展方向可能包括:
- 提高生成视频的分辨率和帧率
- 扩展支持的运动模式和场景类型
- 优化模型结构,减少计算资源需求
- 探索与其他生成模型(如GAN)的结合
- 开发更友好的用户界面,使非专业用户也能轻松使用
结语
LAMP的出现无疑为视频生成领域注入了新的活力。它不仅降低了视频生成的门槛,也为创意表达提供了新的可能性。随着技术的不断发展和完善,我们有理由相信,LAMP及其衍生技术将在未来的数字内容创作中发挥越来越重要的作用。
无论你是研究人员、开发者还是内容创作者,LAMP都值得你去探索和尝试。它可能会成为你创意工具箱中的一个强大武器,帮助你将脑海中的想象变为现实。
让我们共同期待LAMP技术的进一步发展,见证视频生成领域的新篇章! 🚀🎥✨
参考资源
- LAMP GitHub仓库: https://github.com/RQ-Wu/LAMP
- LAMP项目网页: https://rq-wu.github.io/projects/LAMP/index.html
- LAMP论文: https://arxiv.org/abs/2310.10769









