
LaTeX-OCR:让数学公式图像转代码变得简单
在数学、物理等领域的学术研究和教学工作中,LaTeX作为一种强大的排版系统被广泛使用。然而,将已有的数学公式图像转换为LaTeX代码一直是一个耗时且容易出错的过程。为了解决这个问题,GitHub上的开源项目LaTeX-OCR应运而生,它利用计算机视觉和深度学习技术,实现了数学公式图像到LaTeX代码的自动转换。
项目概述
LaTeX-OCR项目由Lukas Blecher开发并维护,其核心目标是创建一个基于学习的系统,能够接收数学公式的图像输入,并输出相应的LaTeX代码。该项目在GitHub上获得了超过11,700颗星,显示出其在学术和开发社区中的广泛关注度。

技术原理
LaTeX-OCR采用了先进的深度学习架构,主要包括:
- 编码器:使用Vision Transformer (ViT)结构,配合ResNet骨干网络,用于提取图像特征。
- 解码器:采用Transformer架构,将编码器提取的特征转换为LaTeX代码序列。
这种编码器-解码器结构能够有效地捕捉数学公式图像中的复杂结构和语义信息,从而生成准确的LaTeX代码。
使用方法
LaTeX-OCR提供了多种使用方式,以适应不同用户的需求:
-
命令行工具:通过
pix2tex命令可以直接处理本地图像或剪贴板中的图像。 -
图形界面:项目提供了一个用户友好的GUI界面,用户可以通过截图快速获取LaTeX代码,并使用MathJax实时渲染结果。
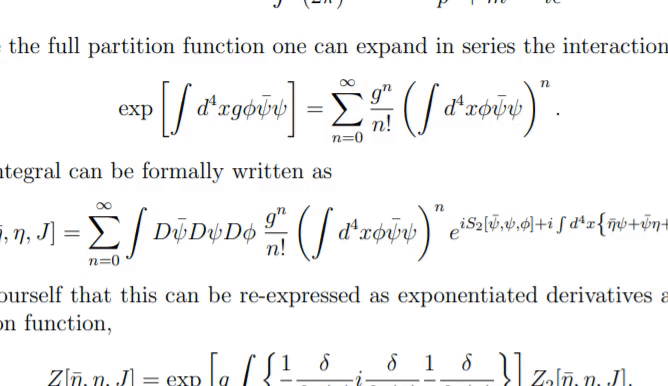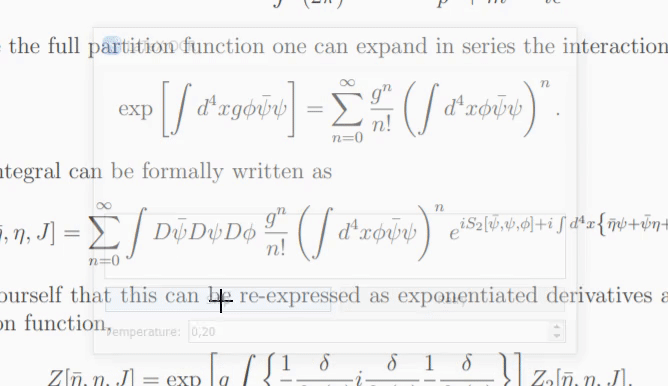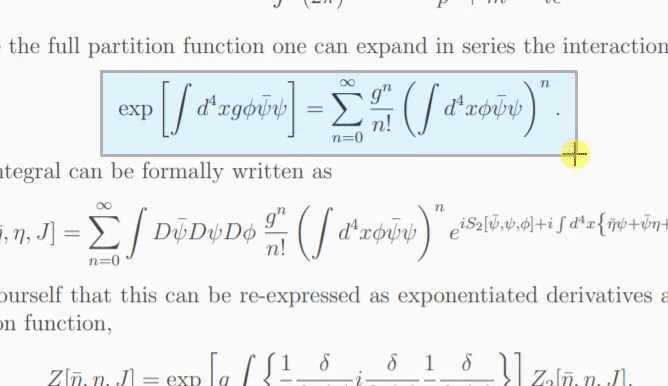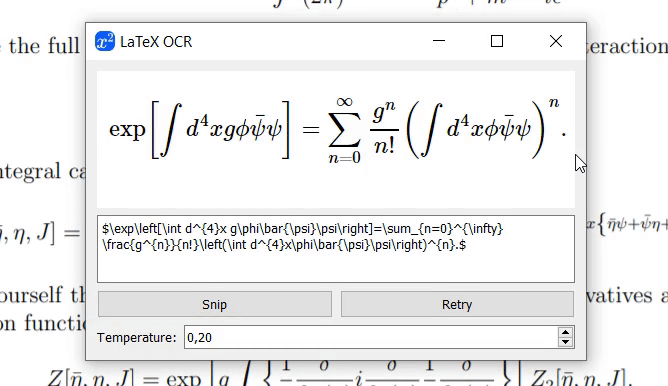
-
API服务:可以通过Docker容器部署API服务,方便集成到其他应用中。
-
Python包:可以在Python代码中直接调用LaTeX-OCR的功能。
from PIL import Image
from pix2tex.cli import LatexOCR
img = Image.open('path/to/image.png')
model = LatexOCR()
print(model(img))
性能与优化
LaTeX-OCR在公开数据集上展现出了优秀的性能:
- BLEU得分: 0.88
- 归一化编辑距离: 0.10
- 令牌准确率: 0.60
为了提高模型在实际应用中的表现,项目引入了一个预处理步骤,使用神经网络预测输入图像的最佳分辨率。这一步骤能够自动调整自定义图像的大小,使其更接近训练数据,从而提高模型在各种场景下的性能。
数据集与训练
LaTeX-OCR的训练数据来源广泛,包括维基百科、arXiv等网站上的LaTeX代码,以及im2latex-100k数据集。项目提供了详细的数据处理和模型训练指南,使得研究人员和开发者可以根据自己的需求定制和改进模型。
未来发展方向
LaTeX-OCR项目仍在积极发展中,未来计划包括:
- 添加更多评估指标
- 优化模型结构
- 支持手写公式识别
- 减小模型大小(通过知识蒸馏)
- 寻找最佳超参数
- 改进数据抓取和扩充数据集
结语
LaTeX-OCR为数学公式的数字化提供了一个强大而便捷的工具。无论是学生、研究人员还是教育工作者,都可以通过这个开源项目大大提高工作效率。随着项目的不断发展和社区的贡献,我们可以期待LaTeX-OCR在未来能够支持更多复杂场景,并在准确性和效率上取得进一步的突破。
对于那些经常需要处理数学公式的人来说,LaTeX-OCR无疑是一个值得关注和尝试的工具。它不仅能节省大量手动输入LaTeX代码的时间,还能减少人为错误,让使用者将更多精力集中在创造性的工作上。
如果您对LaTeX-OCR感兴趣,可以访问项目的GitHub页面了解更多信息,或者直接安装使用。同时,也欢迎有兴趣的开发者为这个开源项目做出贡献,共同推动数学公式识别技术的进步。










