
LaTeX-OCR项目概述
LaTeX-OCR是一个开源项目,目标是创建一个基于机器学习的系统,能够将数学公式的图片转换为对应的LaTeX代码。该项目由Lukas Blecher开发,目前在GitHub上已获得超过12k的star。
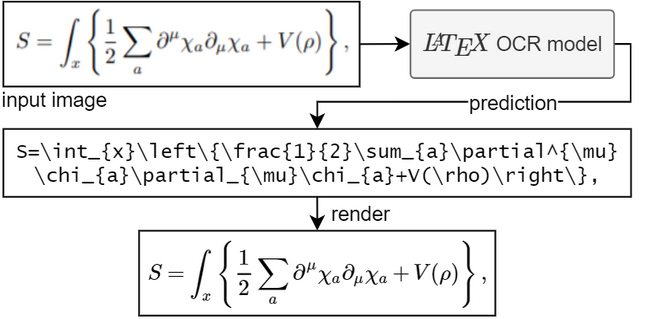
主要功能
- 将公式图片转换为LaTeX代码
- 支持命令行、GUI界面和API多种使用方式
- 可处理手写公式(训练模型后)
- 支持批量处理PDF文档
安装与使用
安装
LaTeX-OCR需要Python 3.7+环境。安装方法如下:
pip install "pix2tex[gui]"
使用方法
-
命令行方式:
pix2tex
2. GUI界面:
latexocr
3. Python代码中使用:
```python
from PIL import Image
from pix2tex.cli import LatexOCR
img = Image.open('path/to/image.png')
model = LatexOCR()
print(model(img))
模型训练
LaTeX-OCR使用了ViT(Vision Transformer)作为编码器,Transformer作为解码器。如果想自己训练模型,可以参考以下步骤:
-
安装训练依赖:
pip install "pix2tex[train]"
2. 准备数据集
3. 修改配置文件
4. 运行训练脚本:
python -m pix2tex.train --config path_to_config_file
详细的训练教程可以参考项目的[Colab notebook](https://colab.research.google.com/github/lukas-blecher/LaTeX-OCR/blob/main/notebooks/LaTeX_OCR_training.ipynb)。
## 相关资源
- [GitHub 仓库](https://github.com/lukas-blecher/LaTeX-OCR)
- [项目文档](https://pix2tex.readthedocs.io/)
- [在线Demo](https://huggingface.co/spaces/lukbl/LaTeX-OCR)
- [Docker镜像](https://hub.docker.com/r/lukasblecher/pix2tex)
## 未来计划
项目开发者计划在未来添加更多功能,包括:
- 添加更多评估指标
- 优化GUI界面
- 添加beam search功能
- 改进手写公式识别
- 缩小模型大小
- 优化模型结构
## 总结
LaTeX-OCR为数学公式的数字化提供了一个便捷的解决方案。无论是学生、研究人员还是开发者,都可以利用这个工具提高工作效率。随着项目的不断发展,相信未来会有更多强大的功能被加入,让数学公式的处理变得更加简单。
如果您对这个项目感兴趣,欢迎访问GitHub仓库了解更多信息,或者尝试使用在线Demo体验其功能。同时,项目也欢迎各种形式的贡献,帮助改进这个开源工具。










