
Lightning Thunder:为PyTorch注入闪电般速度的编译器
在深度学习领域,模型训练速度一直是研究人员和工程师们关注的焦点。如何在有限的硬件资源下实现更快的训练速度,成为了一个亟待解决的问题。而今,Lightning AI 团队推出的 Lightning Thunder 项目为这个问题带来了突破性的解决方案。
Thunder简介:让PyTorch如雷霆般迅猛
Lightning Thunder 是一款为 PyTorch 量身打造的源到源编译器。它的核心目标是通过结合并使用多种硬件执行器,大幅提升 PyTorch 程序的运行速度。Thunder 支持单GPU和多GPU配置,旨在成为一个易用、可理解且可扩展的编译工具。
值得注意的是,Thunder 目前仍处于 alpha 阶段。尽管如此,它已经展现出了令人瞩目的性能提升,为 PyTorch 用户带来了新的可能性。
单GPU性能:显著提升训练吞吐量
Thunder 通过多重优化和使用顶级执行器,实现了相较于标准非编译 PyTorch 代码(即"PyTorch eager")的显著加速。以 LitGPT 中实现的 Llama 2 7B 模型为例,其预训练吞吐量有了明显提升。
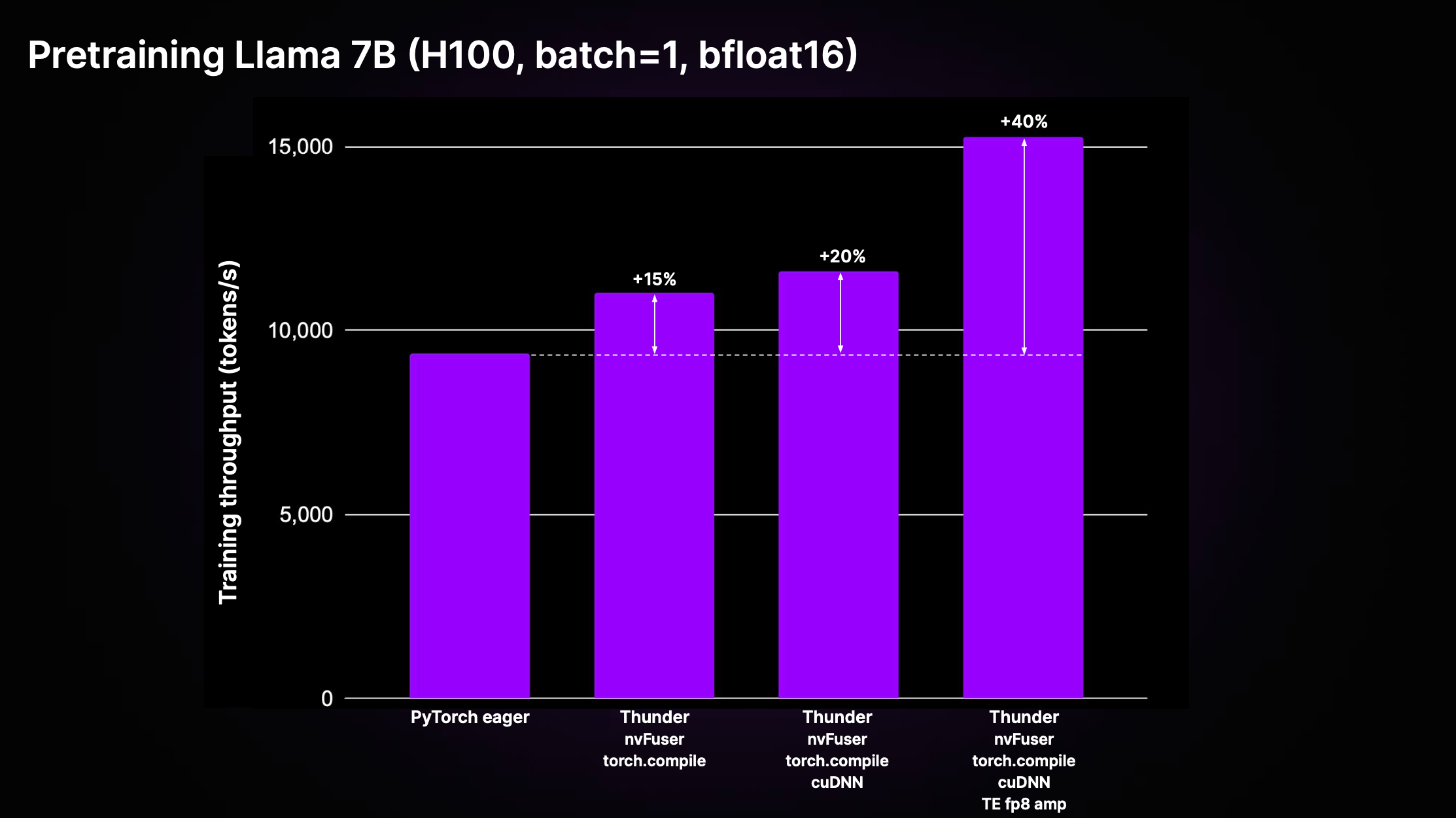
如上图所示,在 H100 GPU 上,Thunder 通过结合使用 nvFuser、torch.compile、cuDNN 和 TransformerEngine FP8 等执行器,实现了相比 eager 模式高达 40% 的训练吞吐量提升。这一成果充分展示了 Thunder 在单 GPU 场景下的强大性能优势。
多GPU性能:分布式训练的效率之选
除了单 GPU 场景,Thunder 还支持 DDP 和 FSDP 等分布式策略,使其能够在多 GPU 环境下训练模型。以下是 Llama 2 7B 模型(不使用 FP8 混合精度)的归一化吞吐量测试结果:
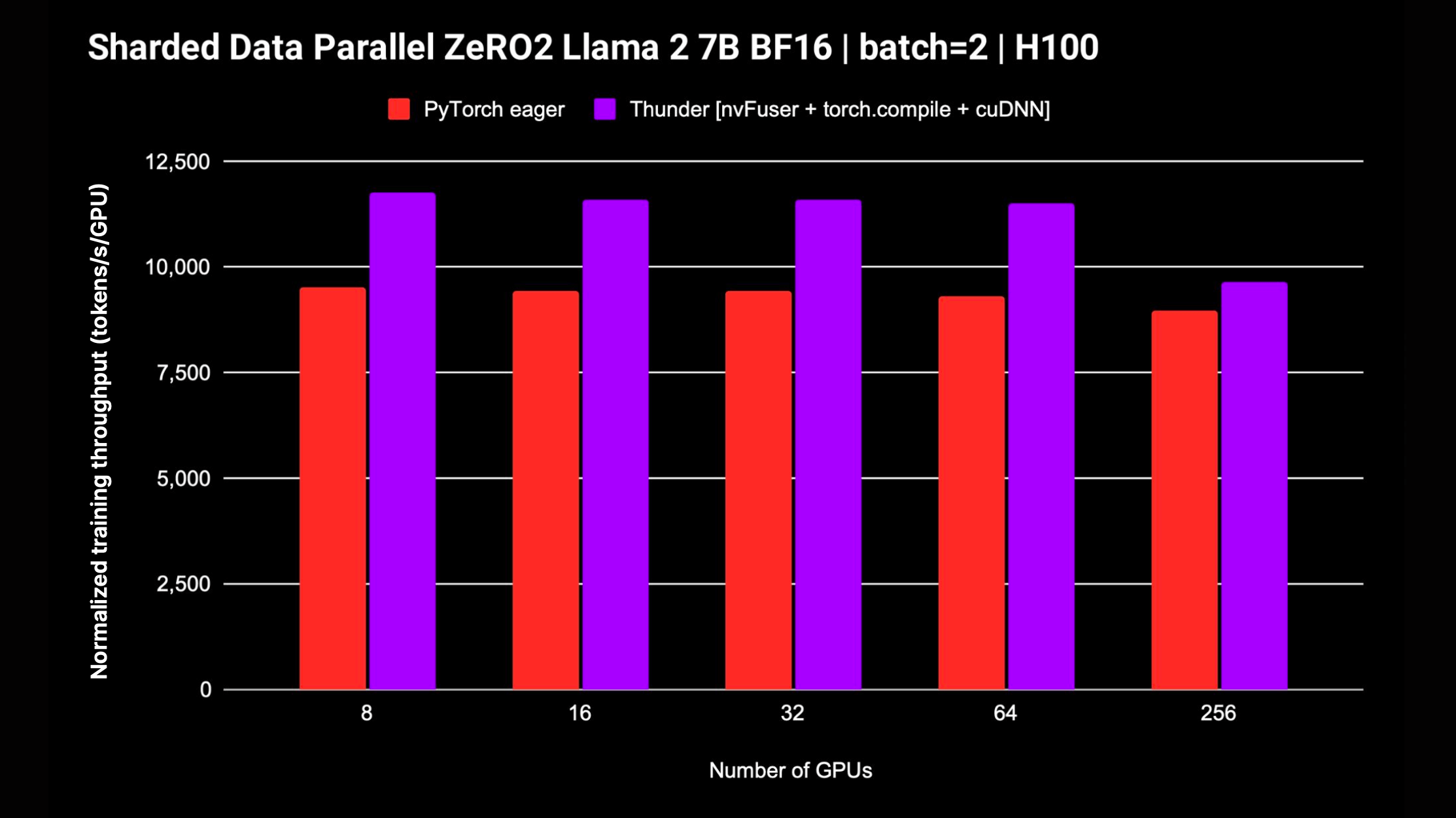
从图中可以看出,Thunder 在多 GPU 配置下依然保持了优秀的扩展性。值得一提的是,Thunder 团队正在积极开发 FSDP 的支持,未来有望带来更多性能提升。
快速上手 Thunder
对于想要尝试 Thunder 的用户来说,最简单的方式是使用 Zero to Thunder Tutorial Studio。这个在线教程无需额外安装即可直接体验 Thunder 的强大功能。
对于希望在本地机器上使用 Thunder 的用户,可以按照以下步骤进行安装:
- 首先安装 nvFuser 和匹配的 PyTorch 稳定版:
pip install --pre nvfuser-cu121-torch24
- 安装 cuDNN:
pip install nvidia-cudnn-frontend
- 最后,安装 Thunder:
pip install lightning-thunder
对于希望使用最新版本或者想要参与 Thunder 开发的用户,项目还提供了从 GitHub 主分支安装的方法,以及可编辑模式的安装方式。这些高级安装选项为开发者提供了更大的灵活性。
Thunder 的"Hello World"
下面是一个简单的示例,展示了如何使用 Thunder 编译和运行 PyTorch 代码:
import torch
import thunder
def foo(a, b):
return a + b
jfoo = thunder.jit(foo)
a = torch.full((2, 2), 1)
b = torch.full((2, 2), 3)
result = jfoo(a, b)
print(result)
# 输出:
# tensor([[4, 4],
# [4, 4]])
这个例子清晰地展示了 Thunder 编译后的函数与原始 PyTorch 函数在使用上的一致性,使得 Thunder 编译的模块和函数可以无缝集成到更大的 PyTorch 程序中。
训练模型:LitGPT 的集成
尽管 Thunder 仍处于早期阶段,不建议用于生产环境,但它已经能够为 LitGPT 支持的 LLM 模型(如 Mistral、Llama 2、Gemma、Falcon 等)的预训练和微调提供出色的性能。有兴趣的用户可以查看 LitGPT 的 Thunder 集成 来了解如何同时运行 LitGPT 和 Thunder。
Thunder 的核心特性
Thunder 的强大之处不仅在于其性能提升,更在于其灵活而强大的内部架构。给定一个 Python 可调用对象或 PyTorch 模块,Thunder 能够生成一个优化后的程序,该程序可以:
- 计算前向和反向传播
- 将操作合并为高效的融合区域
- 将计算分派到优化的内核
- 在多机之间优化分布计算
为了实现这些功能,Thunder 配备了以下核心组件:
- 一个 JIT 编译器,用于获取针对 PyTorch 和自定义操作的 Python 程序
- 多层中间表示(IR),用于将操作表示为简化操作集的跟踪
- 可扩展的计算图跟踪转换集,如梯度计算、融合、分布式策略(如 DDP、FSDP)、函数式转换(如 vmap、vjp、jvp)
- 将操作分派到可扩展的执行器集合的机制
Thunder 的一个独特之处在于,它完全用 Python 编写,甚至其跟踪在所有转换阶段都表示为有效的 Python。这种设计为用户提供了前所未有的洞察和扩展能力。
Thunder 并不直接为 GPU 等加速器生成代码,而是通过获取和转换用户程序,使得可以通过快速执行器(如 torch.compile、nvFuser、cuDNN、Apex、TransformerEngine 等)最优地选择或生成设备代码。此外,Thunder 还支持通过 PyCUDA、Numba、CuPy 等工具自定义 CUDA 内核,以及使用 OpenAI Triton 编写自定义内核。
值得一提的是,使用 Thunder 编译的模块和函数可以与原生 PyTorch 完全互操作,并支持 PyTorch 的自动微分功能。Thunder 还可以与 torch.compile 协同工作,充分利用后者的先进优化。
文档与社区参与
为了帮助用户更好地理解和使用 Thunder,项目提供了详细的在线文档。用户也可以在本地构建文档,以便离线查阅。
Thunder 项目欢迎各种形式的社区参与。无论是功能请求、问题反馈,还是代码贡献,都可以通过 GitHub Issue 进行。项目团队特别强调,他们欢迎所有个人贡献者,不论经验水平或硬件条件如何。这种开放和包容的态度为 Thunder 的持续发展提供了强大的动力。
结语
Lightning Thunder 作为一款强大的 PyTorch 编译器,不仅带来了显著的性能提升,还为 PyTorch 生态系统注入了新的活力。尽管目前仍处于 alpha 阶段,但其已展现出巨大的潜力。随着项目的不断发展和完善,相信 Thunder 将为更多深度学习研究者和工程师提供强大的工具支持,推动 PyTorch 生态系统向更高效、更灵活的方向发展。
对于有兴趣深入了解或参与 Thunder 项目的读者,不妨访问其 GitHub 仓库,亲身体验这款令人兴奋的 PyTorch 编译器。让我们共同期待 Thunder 在未来带来更多惊喜,为深度学习领域的发展贡献力量。🚀⚡


















