
LLaMA-Cult-and-More学习资料汇总 - 平价但强大的大语言模型资源导航
LLaMA-Cult-and-More是一个致力于组织和整理平价但强大的大语言模型(LLMs)资源的GitHub项目。本文将为大家汇总该项目的核心内容和相关学习资料,帮助读者快速了解和学习大语言模型相关知识。
项目简介
LLaMA-Cult-and-More项目提供了以下主要内容:
- 最新模型的详细信息,包括参数数量、微调数据集和技术、硬件规格等
- LLM对齐后训练的实用指南,包括数据集、基准测试数据集、高效训练库和技术
- 从预训练模型到后训练模型的探索
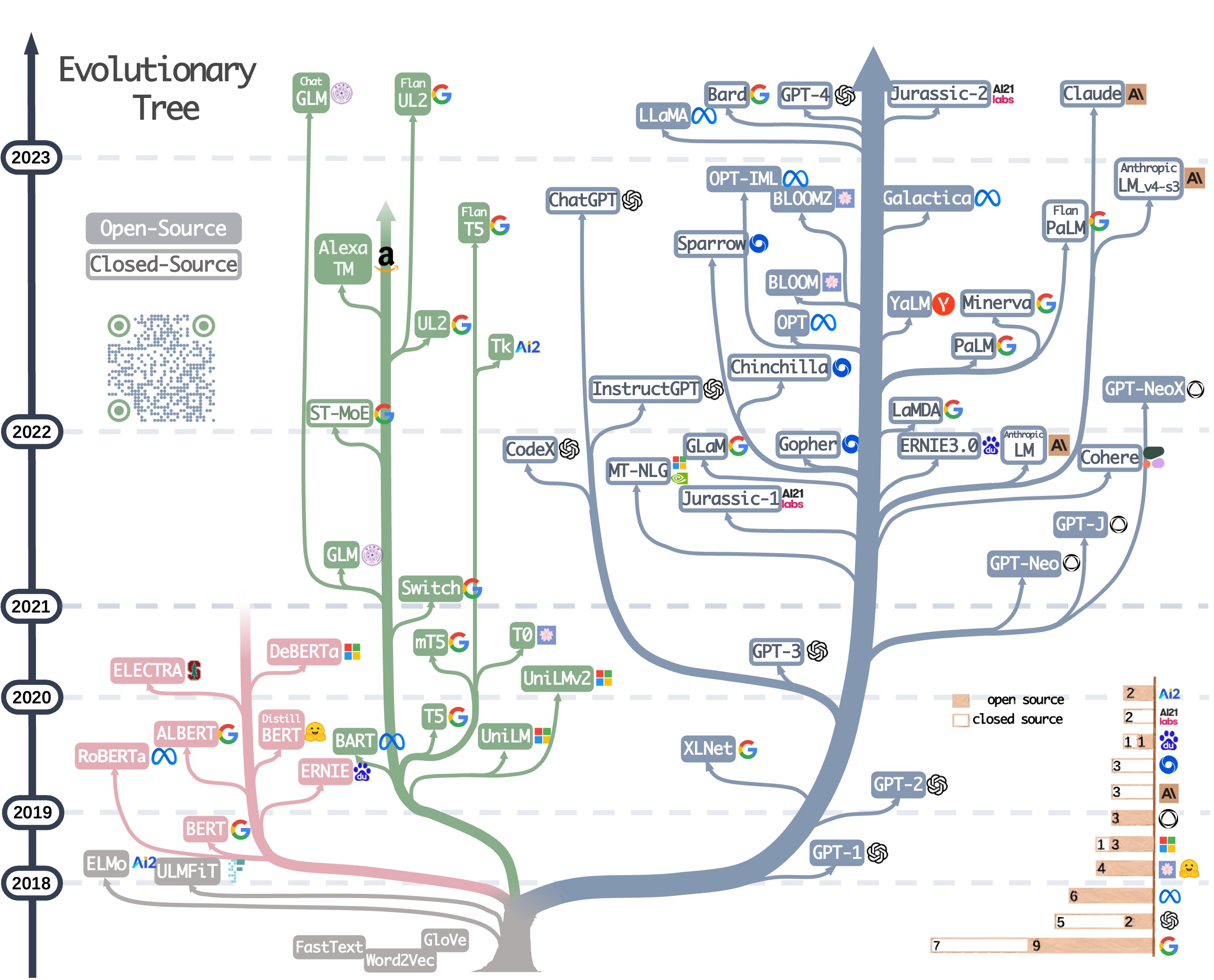
基础模型介绍
项目整理了主流的开源大语言模型,包括:
- OpenAI: GPT系列
- Meta: LLaMA、OPT等
- Google: T5、PaLM等
- EleutherAI: GPT-Neo、GPT-J等
- Tsinghua: GLM、ChatGLM等
指令数据集
项目收集了用于指令微调的数据集,如:
- Stanford Alpaca: 52K指令数据集
- Databricks Dolly: 15K人工标注数据集
- LAION OIG: 开源指令生成数据集
高效训练方法
介绍了一些高效训练大语言模型的技术:
- LoRA: 低秩适应
- DeepSpeed: 分布式训练
- 8-bit量化: 减少内存占用
- PEFT: 参数高效微调
评估基准
收集了一些评估LLM性能的基准数据集:
- MMLU: 英语LLM评估
- C-Eval: 中文LLM评估
- TruthfulQA: 事实性评估
相关资源
本项目为研究人员和开发者提供了全面的大语言模型学习资源,从基础模型到训练技巧,再到评估方法,都有详细的介绍。无论你是刚接触LLM还是已有一定经验,都能在这里找到有价值的信息。随着LLM技术的快速发展,该项目也在持续更新,建议读者保持关注,及时了解最新进展。


















