
LLaMA的诞生与发展
在人工智能领域,大语言模型(Large Language Models, LLMs)的发展一直备受关注。2023年2月,Meta AI团队发布了LLaMA(Large Language Model Meta AI)模型,为开源大语言模型的发展开启了新的篇章。LLaMA是一个包含7B、13B、33B和65B参数的系列模型,在多项基准测试中表现出色,甚至在某些任务上超越了GPT-3。
LLaMA的发布引发了开源社区的广泛关注和参与。随后,斯坦福大学发布了基于LLaMA-7B模型微调的Alpaca模型,展示了如何利用较小规模的指令数据集来改进大语言模型的性能。这一成果激发了更多研究者和开发者参与到LLaMA相关模型的优化和应用中来。
LLaMA的技术特点
LLaMA模型具有以下几个显著的技术特点:
-
高效的训练方法: LLaMA采用了更高效的训练方法,使用更少的计算资源就能达到与GPT-3相当的性能。例如,LLaMA-13B模型在许多任务上的表现已经可以媲美GPT-3 175B。
-
开源友好: 虽然LLaMA最初并非完全开源,但其发布的模型权重和代码为研究社区提供了宝贵的资源,促进了开源大语言模型的发展。
-
多语言支持: LLaMA在训练时选择了20种使用人数最多的语言的文本,使模型具有一定的多语言能力。
-
灵活的模型规模: LLaMA提供了多个不同参数规模的模型版本,从7B到65B不等,满足不同应用场景的需求。
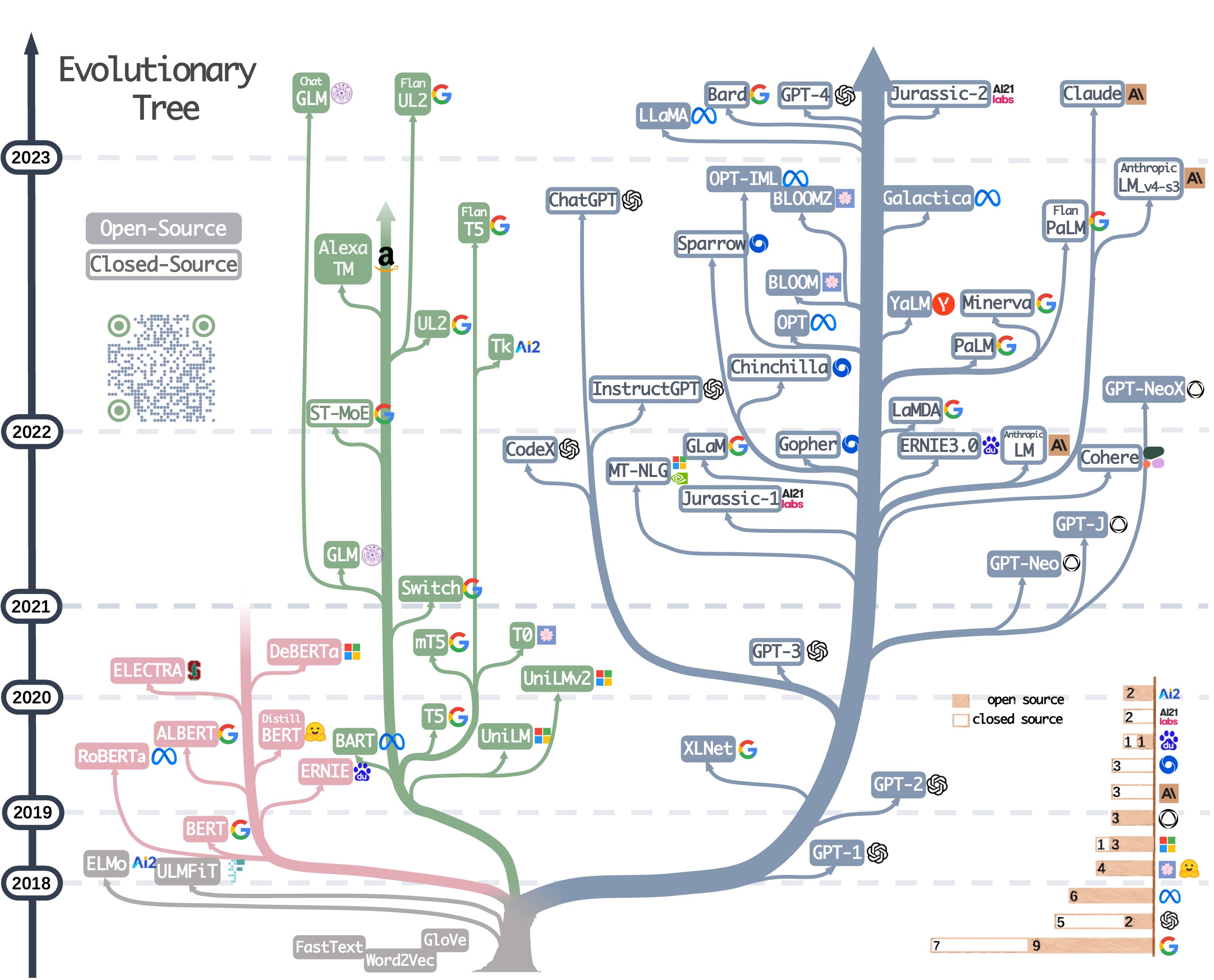
LLaMA的衍生模型
LLaMA的发布引发了一系列衍生模型的出现,这些模型在LLaMA的基础上进行了各种优化和改进:
-
Alpaca: 斯坦福大学团队基于LLaMA-7B模型,使用52K条指令数据进行微调,创建了Alpaca模型。Alpaca展示了如何用较小的数据集和有限的计算资源来提升模型性能。
-
Vicuna: 由UC Berkeley、CMU等机构合作开发,基于LLaMA-7B/13B模型,使用来自ShareGPT.com的用户对话数据进行微调。Vicuna在多项评估中表现出色,被认为达到了ChatGPT 90%的性能水平。
-
Chinese-LLaMA-Alpaca: 该项目针对中文场景对LLaMA进行了优化,增加了20K个中文词汇,并使用大规模中文语料进行了预训练和指令微调。
-
GPT4All: 基于LLaMA-7B模型,使用约800K条GPT-3.5-Turbo生成的指令数据进行微调,旨在提供一个可在消费级硬件上运行的强大语言模型。
这些衍生模型展示了LLaMA的潜力和灵活性,也为开源社区提供了丰富的研究和应用方向。
LLaMA的应用与影响
LLaMA及其衍生模型在多个领域展现出了广阔的应用前景:
-
自然语言处理: 在文本生成、问答系统、情感分析等任务中,LLaMA系列模型表现出色。
-
多语言支持: 通过针对性的优化,如Chinese-LLaMA-Alpaca项目,LLaMA可以为非英语语言提供强大的支持。
-
低资源环境应用: 较小规模的LLaMA模型(如7B版本)可以在普通PC甚至移动设备上运行,为边缘计算和个人AI助手提供了可能性。
-
领域特定应用: 研究者可以基于LLaMA针对特定领域(如法律、医疗、金融等)进行微调,创建专业化的语言模型。
LLaMA的开源性质极大地推动了AI民主化进程,使更多研究者和开发者能够参与到大语言模型的研究和应用中来。这不仅加速了技术创新,也促进了AI伦理和安全等重要议题的讨论。
未来展望
随着LLaMA及其衍生模型的不断发展,我们可以期待以下几个方向的进展:
-
模型效率提升: 研究者将继续探索如何在保持或提高性能的同时,进一步减小模型规模,提高训练和推理效率。
-
多模态集成: 将LLaMA与计算机视觉、语音识别等技术结合,发展多模态AI系统。
-
个性化和定制化: 开发更灵活的微调和适应方法,使模型能够更好地适应个人或特定领域的需求。
-
伦理和安全: 随着模型能力的提升,如何确保AI系统的安全性、公平性和可控性将成为越来越重要的研究方向。
-
跨语言能力增强: 进一步提升模型的多语言处理能力,减少语言之间的性能差距。
结语
LLaMA的出现标志着开源大语言模型进入了一个新的阶段。它不仅展示了高效训练大规模语言模型的可能性,也为AI研究和应用提供了一个开放、灵活的平台。随着社区的持续努力和创新,我们有理由相信,LLaMA及其衍生模型将继续推动自然语言处理技术的边界,为人工智能的发展做出重要贡献。
作为研究者、开发者或是AI爱好者,我们都有机会参与到这一激动人心的进程中来。无论是通过对模型进行微调、开发新的应用,还是探讨AI的伦理问题,每个人都可以在LLaMA生态系统中找到自己的角色。让我们共同期待LLaMA带来的更多可能性,并为构建更智能、更有益于人类的AI系统贡献自己的力量。


















