
LLaMA-Pro简介
LLaMA-Pro是腾讯人工智能实验室(Tencent ARC)开发的大语言模型,基于LLaMA2进行改进和扩展。该模型在保持通用语言理解能力的同时,增强了编程和数学等领域的专业知识,是一个兼具通用性和专业性的AI模型。
主要特点:
- 基于LLaMA2-7B扩展到8.3B参数规模
- 在代码和数学语料上进行了额外训练(约800亿token)
- 在编程和数学等任务上表现优异
- 开源了8B和8B-Instruct两个版本
官方资源
- GitHub仓库 - 包含模型代码、训练脚本等
- HuggingFace模型页面 - 可下载模型权重
- arXiv论文 - 详细介绍模型原理和实验结果
模型使用
LLaMA-Pro模型可以通过以下方式使用:
- 使用HuggingFace Transformers库加载:
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("TencentARC/LLaMA-Pro-8B")
model = AutoModelForCausalLM.from_pretrained("TencentARC/LLaMA-Pro-8B")
- 使用Ollama运行:
ollama run llama-pro
- 本地部署Demo:
Clone GitHub仓库后,运行demo目录下的app.py文件即可启动Gradio界面。
评测结果
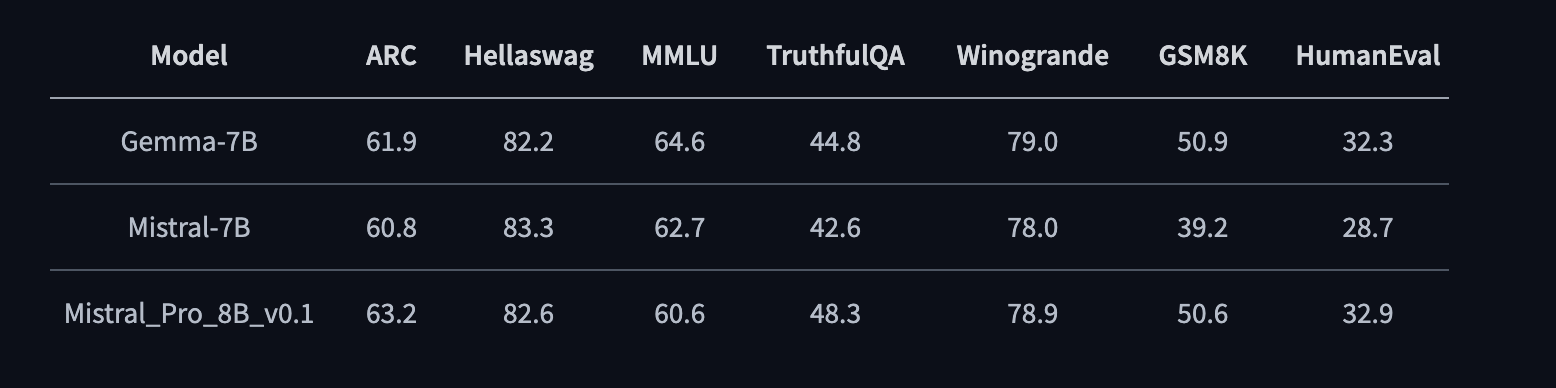
LLaMA-Pro在多个基准测试中展现出优异性能,特别是在代码和数学任务上。与同等规模的开源模型相比,LLaMA-Pro取得了全面领先的成绩。
相关项目
- Mistral-Pro - 基于Mistral的改进版本,性能进一步提升
- MetaMath-Mistral-Pro - 专注于数学能力的改进版本
总结
LLaMA-Pro作为一个开源的高性能大语言模型,为研究人员和开发者提供了宝贵的资源。通过本文提供的资料,读者可以快速上手使用LLaMA-Pro,并深入了解其技术细节。随着模型的持续更新和社区的贡献,相信LLaMA-Pro会在未来发挥更大的作用。









