
LlamaParse: 为RAG应用打造的高级文档解析工具
在当前人工智能快速发展的背景下,检索增强生成(Retrieval Augmented Generation, RAG)技术正在成为连接大型语言模型(LLM)与专有数据的重要桥梁。然而,RAG系统的效果很大程度上取决于对原始数据的处理质量。面对复杂的非结构化文档,特别是包含表格、图像等嵌入对象的PDF文件,传统的文本提取方法往往难以应对。为了解决这一挑战,LlamaIndex团队推出了一款革命性的文档解析工具—— LlamaParse。
LlamaParse: 解锁复杂文档的潜力
LlamaParse是一个专为RAG应用设计的高级API,旨在高效解析和表示复杂文档。它的核心优势在于能够准确处理包含表格、图像等嵌入对象的PDF等文件,将其转换为结构化的markdown或纯文本格式,从而为后续的检索和上下文增强奠定基础。
LlamaParse的主要特性包括:
- 支持多种文件格式:除PDF外,还支持.pptx、.docx、.rtf、.pages、.epub等格式。
- 灵活的输出选项:可选择输出为markdown或纯文本格式。
- 全面的提取能力:不仅能提取文本,还可以处理表格、图像、图表,甚至数学公式。
- 自定义解析指令:支持通过提示词来指导解析过程,增加灵活性。
- JSON模式:提供文档的完整结构,包括图像大小和位置元数据,表格的JSON格式表示等。
与LlamaIndex的无缝集成
作为LlamaIndex生态系统的一部分,LlamaParse可以与LlamaIndex框架无缝集成,为RAG应用提供端到端的解决方案。这种集成使得从原始文档到结构化数据,再到最终的检索和生成,整个过程变得流畅高效。
使用LlamaParse的优势
-
提高RAG效果:通过保留文档的原始结构和格式信息,LlamaParse能显著提升RAG系统的准确性和相关性。
-
节省工程时间:相比于自行开发复杂的文档解析逻辑,使用LlamaParse可以大幅减少开发时间和成本。
-
处理复杂布局:对于含有复杂表格、图表的文档,LlamaParse的表现远超传统的开源解析器。
-
灵活的集成选项:可以作为独立服务使用,也可以与LlamaIndex的托管摄取和检索API集成。
实际应用案例
LlamaParse在各种领域都展现出了强大的实力:
- 金融分析:解析年报、季报等复杂财务文件,提取关键数据用于分析。
- 学术研究:处理ArXiv上的论文,精确提取文本、公式和图表。
- 医疗报告:从复杂的医疗文档中提取结构化信息,支持临床决策。
- 法律文件:解析合同、法律条款等文件,支持法律分析和合规检查。
快速上手指南
要开始使用LlamaParse,只需几个简单步骤:
-
获取API密钥:访问https://cloud.llamaindex.ai/api-key注册并获取密钥。
-
安装必要的包:
pip install llama-parse pip install -U llama-index --upgrade --no-cache-dir --force-reinstall -
基本使用示例:
from llama_parse import LlamaParse parser = LlamaParse( api_key="your_api_key_here", result_type="markdown", num_workers=4, verbose=True ) documents = parser.load_data("./your_file.pdf")
与其他工具的比较
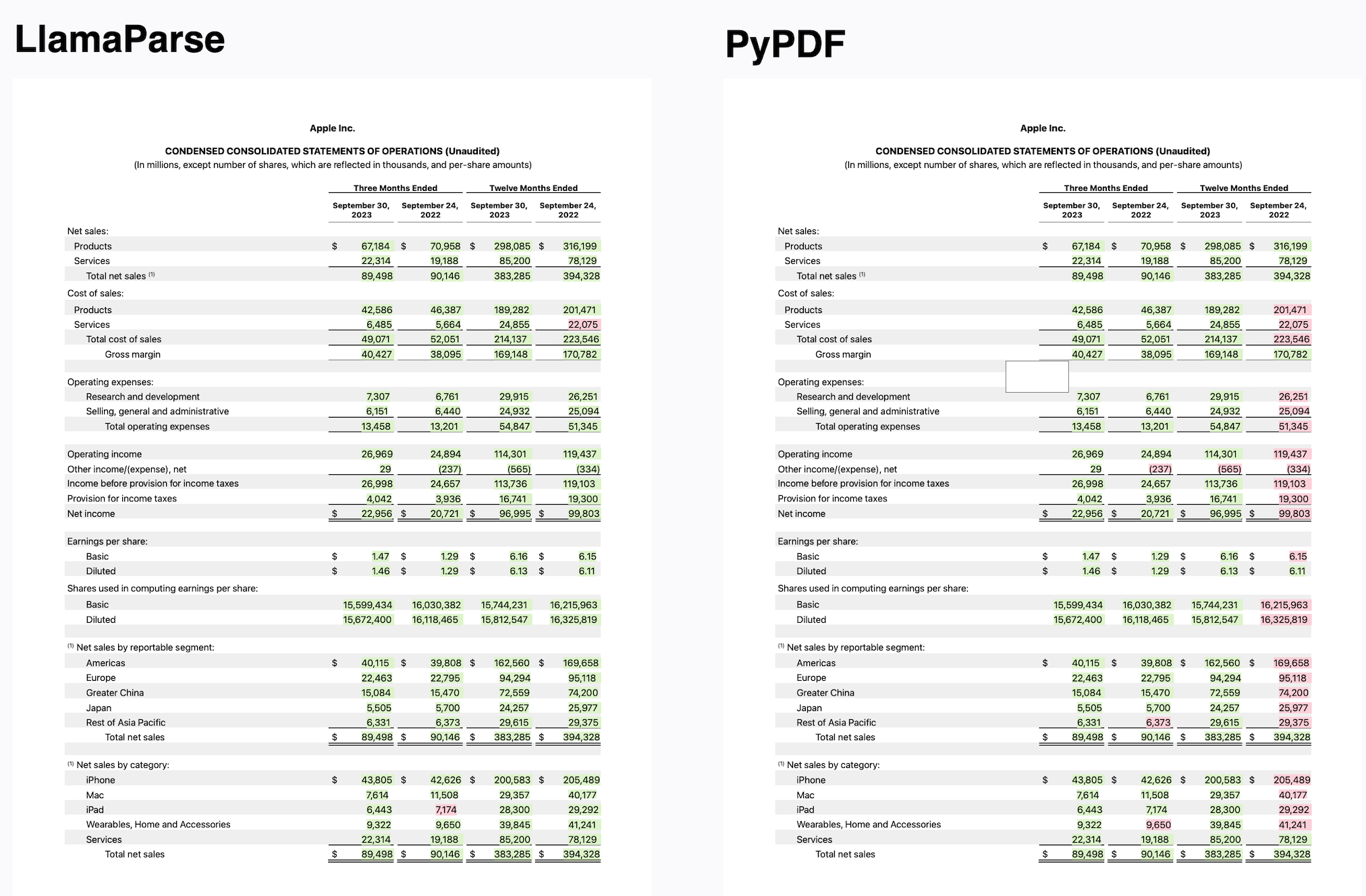
与传统的PDF解析工具相比,LlamaParse在处理复杂文档时表现出明显优势。例如,在解析包含嵌套表格的金融报告时,LlamaParse能准确识别和提取表格结构,而普通工具往往会失败。

未来展望
LlamaParse团队正在持续改进和扩展其功能:
- 增强对图像的支持:提高图表和图像的解析准确度。
- 扩展文件类型支持:计划增加对更多常用文档格式的原生支持。
- 性能优化:进一步提高处理速度和效率。
结语
LlamaParse代表了文档解析技术的一次重大飞跃,为构建高性能RAG系统铺平了道路。通过解决复杂文档解析的痛点,它使得开发者可以更专注于核心业务逻辑的实现,而不必被繁琐的数据预处理所困扰。随着LlamaParse的不断发展和完善,我们有理由相信,它将在推动RAG技术的广泛应用和创新中发挥越来越重要的作用。
对于那些正在寻求提升文档处理能力、构建更智能RAG应用的开发者和企业来说,LlamaParse无疑是一个值得深入探索和尝试的强大工具。通过结合LlamaParse的强大解析能力与LlamaIndex的先进索引和检索功能,开发者可以构建出更加智能、高效的AI应用,为各行各业带来前所未有的价值。









