
LLaVA: 开启视觉语言智能新纪元
近年来,随着大型语言模型(LLM)和计算机视觉技术的飞速发展,将两者结合的多模态AI助手引起了广泛关注。其中,LLaVA(Large Language and Vision Assistant)作为一个里程碑式的项目,通过创新性的视觉指令微调方法,实现了接近GPT-4水平的视觉-语言理解能力,为多模态AI的发展开辟了新的方向。本文将全面介绍LLaVA的发展历程、核心技术、应用场景以及最新进展。
LLaVA的诞生与发展
LLaVA项目由来自威斯康星大学麦迪逊分校、微软研究院和哥伦比亚大学的研究人员共同开发。该项目的初衷是构建一个具有GPT-4级别能力的端到端大型多模态模型,可以进行通用的视觉和语言理解。
LLaVA的发展经历了几个重要的里程碑:
-
2023年4月,研究团队发布了首个版本的LLaVA模型,并提出了视觉指令微调的创新方法。
-
2023年10月,LLaVA 1.5版本发布,在11个基准测试中达到了最先进的水平,仅使用公开数据就超越了一些使用数十亿规模数据的方法。
-
2024年1月,最新的LLaVA-NeXT(LLaVA 1.6)版本发布,进一步提升了推理能力、OCR和世界知识,在某些基准测试中甚至超越了Gemini Pro。
这一系列的进展使LLaVA迅速成为多模态AI领域的前沿项目之一,吸引了广泛的关注和应用。
LLaVA的核心技术
LLaVA的核心创新在于其独特的训练方法 - 视觉指令微调(Visual Instruction Tuning)。这种方法包含两个主要阶段:
-
特征对齐阶段:使用LAION-CC-SBU数据集的558K子集,将预训练的视觉编码器与大型语言模型(LLM)连接起来。这一阶段的目的是让视觉特征与语言模型的表示空间对齐。
-
视觉指令微调阶段:使用150K GPT生成的多模态指令数据,加上约515K来自学术导向任务的VQA数据,教导模型遵循多模态指令。这一阶段使模型能够理解和执行涉及图像的复杂指令。
LLaVA的架构包括以下关键组件:
- 视觉编码器:使用CLIP ViT-L/14作为视觉特征提取器
- 语言模型:基于Vicuna大型语言模型
- 视觉-语言连接器:采用两层MLP结构,将视觉特征映射到语言模型的表示空间
这种设计使LLaVA能够有效地融合视觉和语言信息,实现高水平的多模态理解和生成能力。
LLaVA的应用场景
LLaVA作为一个通用的视觉-语言助手,具有广泛的应用前景:
-
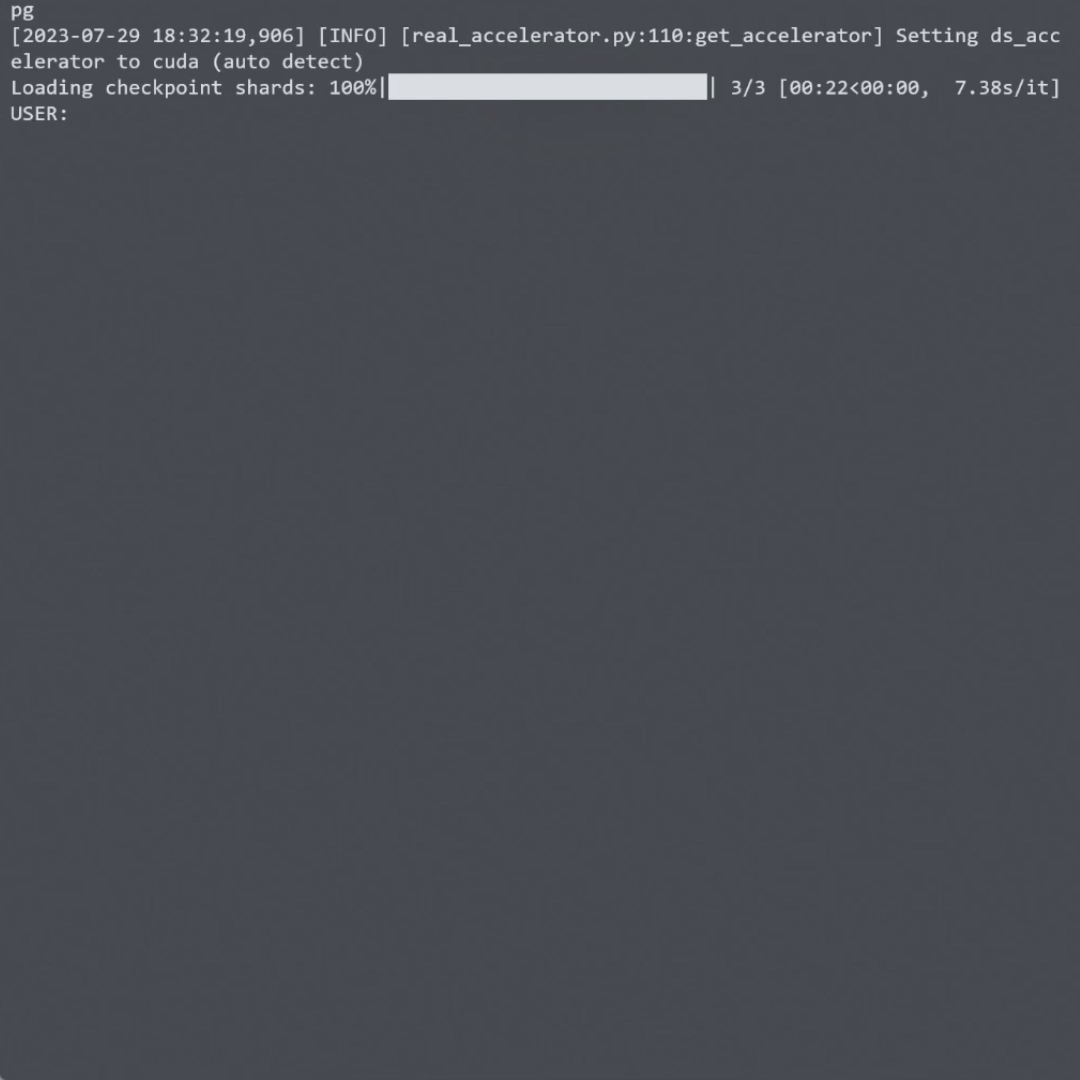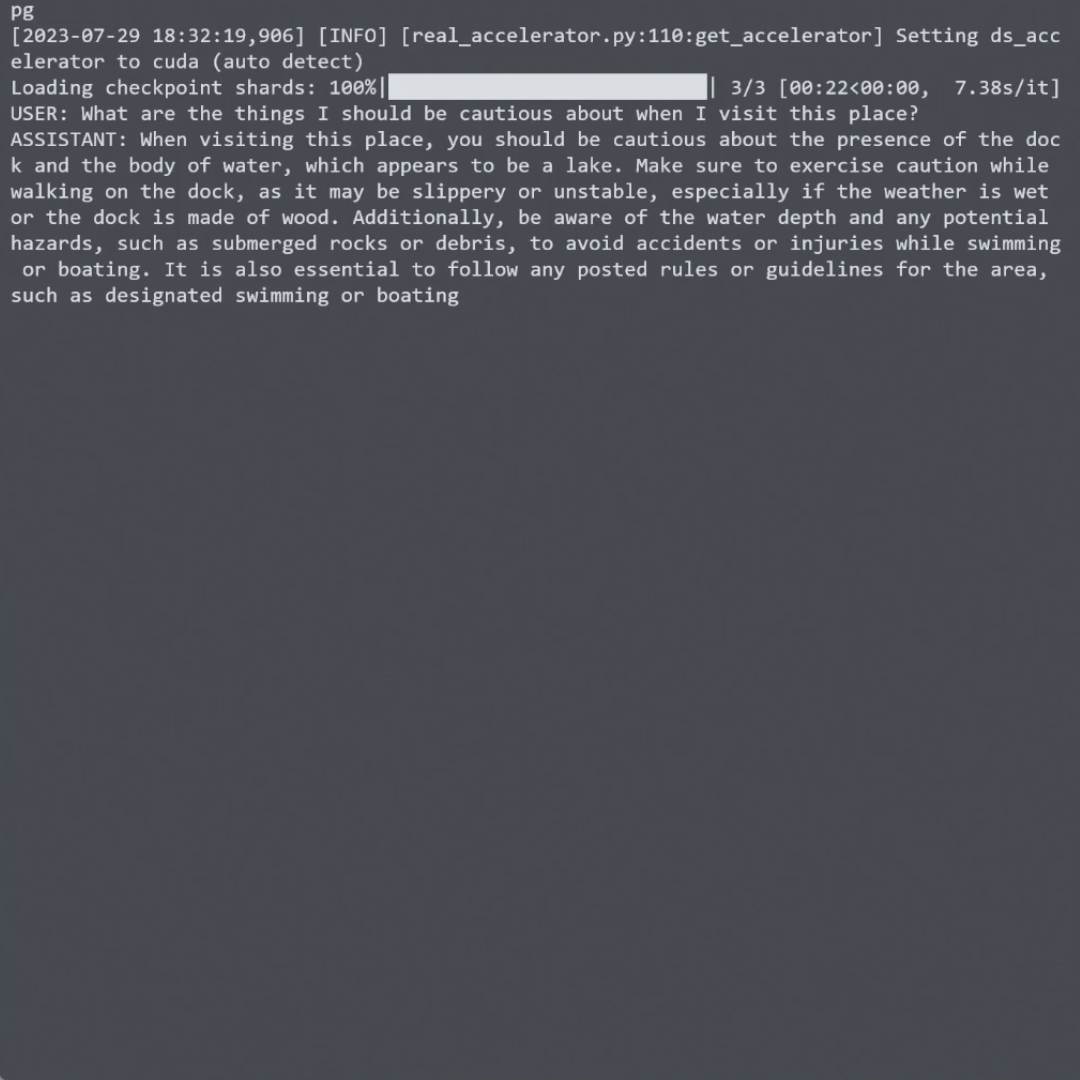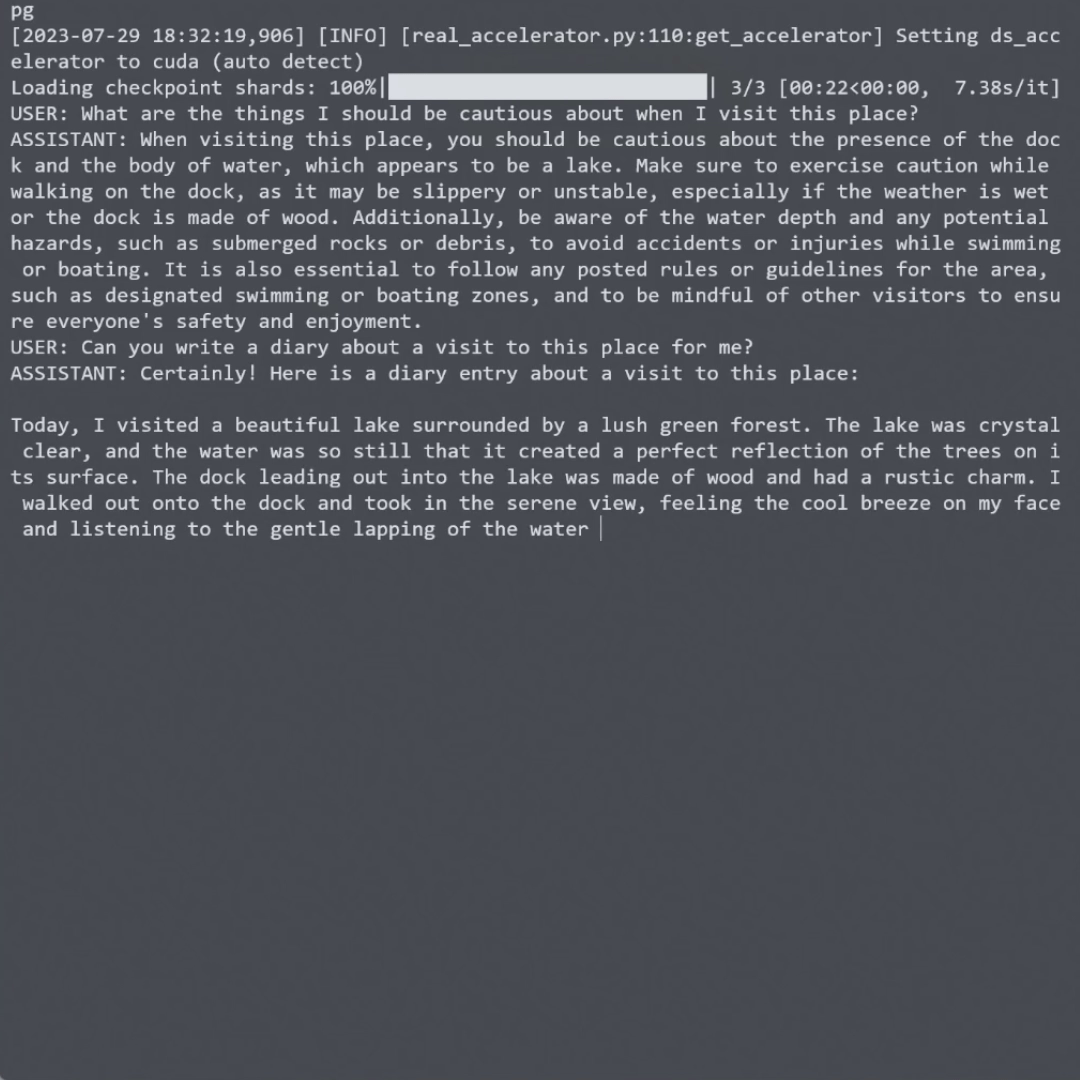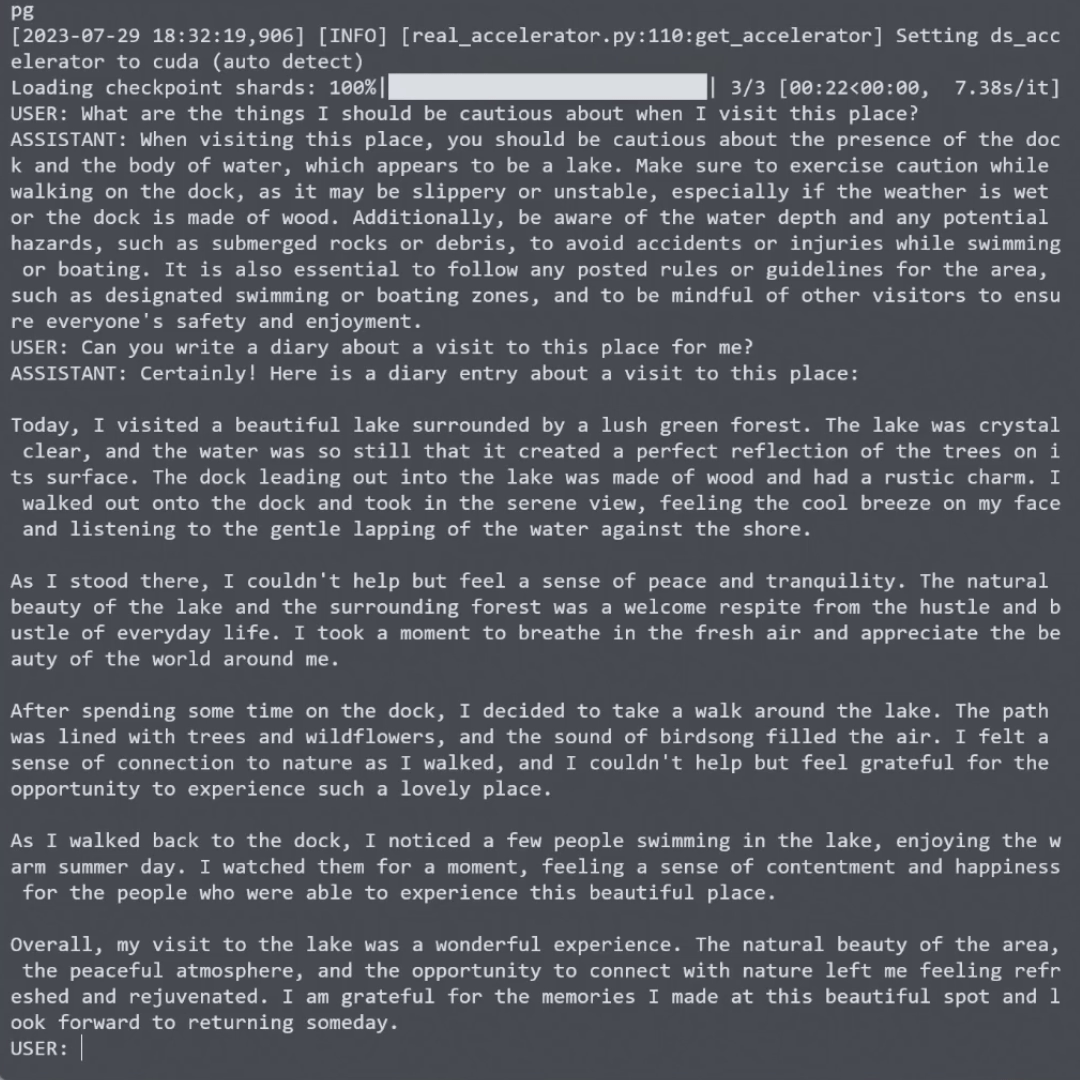
视觉问答:用户可以针对图像提出各种问题,LLaVA能够理解图像内容并给出准确回答。
-
图像描述生成:LLaVA可以为给定图像生成详细、准确的描述文本。
-
视觉推理:模型能够基于图像进行复杂的推理任务,如物体关系分析、场景理解等。
-
多模态对话:LLaVA支持基于图像的自然语言对话,可以进行连贯的多轮交互。
-
视觉创作辅助:在图像编辑、设计等领域,LLaVA可以提供创意建议和指导。
-
教育辅助:通过图像解释复杂概念,帮助学习者更好地理解知识点。
-
医疗影像分析:辅助医生解读各类医疗影像,提供诊断建议。
-
安防监控:分析监控图像和视频,识别异常情况并生成报告。
这些应用场景展示了LLaVA在实际生活和各行各业中的巨大潜力。
LLaVA的最新进展
LLaVA项目一直在快速迭代和改进中。最新的LLaVA-NeXT(1.6版本)带来了多项重要升级:
-
扩展模型规模:新增了34B参数的模型,显著提升了整体性能。
-
提高像素处理能力:可以处理4倍于之前的像素数量,提升了对高分辨率图像的处理能力。
-
增强OCR能力:大幅提升了文字识别和理解能力,可以更好地处理包含文本的图像。
-
改进世界知识:通过更多训练数据,增强了模型的背景知识和常识推理能力。
-
支持更多任务:如图像编辑、生成等,扩展了模型的应用范围。
此外,LLaVA团队还发布了一系列相关项目,如LLaVA-Plus(使用工具的多模态代理)、LLaVA-Interactive(交互式图像聊天、分割、生成和编辑)等,进一步拓展了LLaVA的能力边界。
LLaVA的开源贡献
LLaVA项目秉持开源精神,为整个AI社区做出了重要贡献:
-
开源代码:完整的训练和推理代码已在GitHub上公开,方便研究者复现和改进。
-
预训练模型:多个版本的预训练模型权重可在Hugging Face上获取,降低了使用门槛。
-
数据集:项目使用的指令微调数据集也已公开,推动了相关研究的发展。
-
评估基准:提供了多个评估脚本和基准,有助于公平比较不同模型的性能。
-
社区贡献:支持多种部署方式,如llama.cpp、Colab等,方便不同环境下的使用。
这些开源努力极大地促进了多模态AI领域的发展,也为LLaVA赢得了广泛的社区支持。
未来展望
尽管LLaVA已经取得了令人瞩目的成果,但多模态AI仍有很长的发展道路要走。未来的研究方向可能包括:
-
进一步提升模型规模和效率,探索更优的架构设计。
-
增强对复杂场景和抽象概念的理解能力。
-
改进模型的可解释性和安全性,减少偏见和幻觉。
-
拓展到更多模态,如音频、视频、触觉等。
-
探索与其他AI技术的结合,如强化学习、图神经网络等。
-
研究更高效的训练方法,减少对大规模数据和计算资源的依赖。
LLaVA作为多模态AI的重要里程碑,为未来的研究指明了方向。我们可以期待在不久的将来,更加智能、通用和易用的视觉语言助手将成为现实,为人类的工作和生活带来革命性的变化。
结语
LLaVA项目展示了视觉和语言融合的巨大潜力,为构建真正的通用人工智能迈出了重要一步。通过持续的创新和开源合作,LLaVA正在推动多模态AI领域的快速发展。无论是研究人员、开发者还是普通用户,都有机会参与到这一激动人心的技术革命中来,共同塑造AI驱动的未来世界。
随着LLaVA及其衍生项目的不断进步,我们可以期待看到更多令人惊叹的应用和突破。这个领域的发展将不仅改变我们与计算机交互的方式,还将为解决复杂的现实世界问题提供强大工具。让我们共同期待LLaVA和多模态AI的光明未来!













