
LLaVA-Med: 引领生物医学人工智能的新时代
在人工智能技术日新月异的今天,一个革命性的项目正在悄然改变生物医学领域的研究与应用方式。这个名为LLaVA-Med的项目,由微软研究院的顶尖科学家团队开发,旨在打造一个具有GPT-4级别能力的生物医学大规模语言与视觉助手。让我们一起来深入了解这个激动人心的项目。
突破性的训练方法
LLaVA-Med的核心创新在于其独特的训练方法。研究团队采用了一种名为"课程学习"的方法,通过模仿人类学习生物医学知识的过程,让模型逐步掌握从基础概念到复杂应用的全方位能力。这种方法不仅大大提高了训练效率,更重要的是让模型形成了系统性的知识结构,为后续的开放式对话和问答奠定了坚实基础。
具体来说,LLaVA-Med的训练分为两个主要阶段:
-
生物医学概念对齐:在这个阶段,模型学习理解和识别各种生物医学术语、概念和图像。研究团队利用从PubMed Central提取的大规模图像-文本对数据集,让模型建立起生物医学领域的基础知识网络。
-
全面指令微调:在掌握基础知识后,模型进入更高级的训练阶段。研究人员使用GPT-4生成的开放式指令数据,训练模型理解复杂的问题,并提供准确、详细的回答。这个阶段模拟了专业人士如何运用知识解决实际问题的过程。

这种循序渐进的训练方法不仅提高了模型的性能,更让LLaVA-Med具备了惊人的效率——整个训练过程仅需不到15小时就可以完成,这在大规模AI模型的训练中是极其罕见的。
多模态对话的新境界
LLaVA-Med最令人印象深刻的特点是其强大的多模态对话能力。它不仅能够理解文本输入,还可以"看懂"各种生物医学图像,包括X光片、CT扫描、显微镜图像等。这种能力使得LLaVA-Med可以在各种复杂的生物医学场景中提供专业级的分析和建议。
例如,当向LLaVA-Med展示一张肺部X光片时,它可以:
- 识别出图像中的关键结构和可能的异常
- 根据用户的问题提供详细的解释
- 结合已有的医学知识,给出潜在的诊断建议
- 甚至可以讨论不同治疗方案的利弊
这种能力不仅可以辅助医疗专业人员进行诊断和研究,也为医学教育提供了强大的工具。学生可以通过与LLaVA-Med的交互,深入理解复杂的医学概念和案例。
开源精神与研究价值
值得一提的是,LLaVA-Med项目秉承了开源精神。研究团队不仅公开了模型的代码和训练数据,还详细描述了整个开发过程。这种开放态度极大地促进了生物医学AI领域的研究与创新。
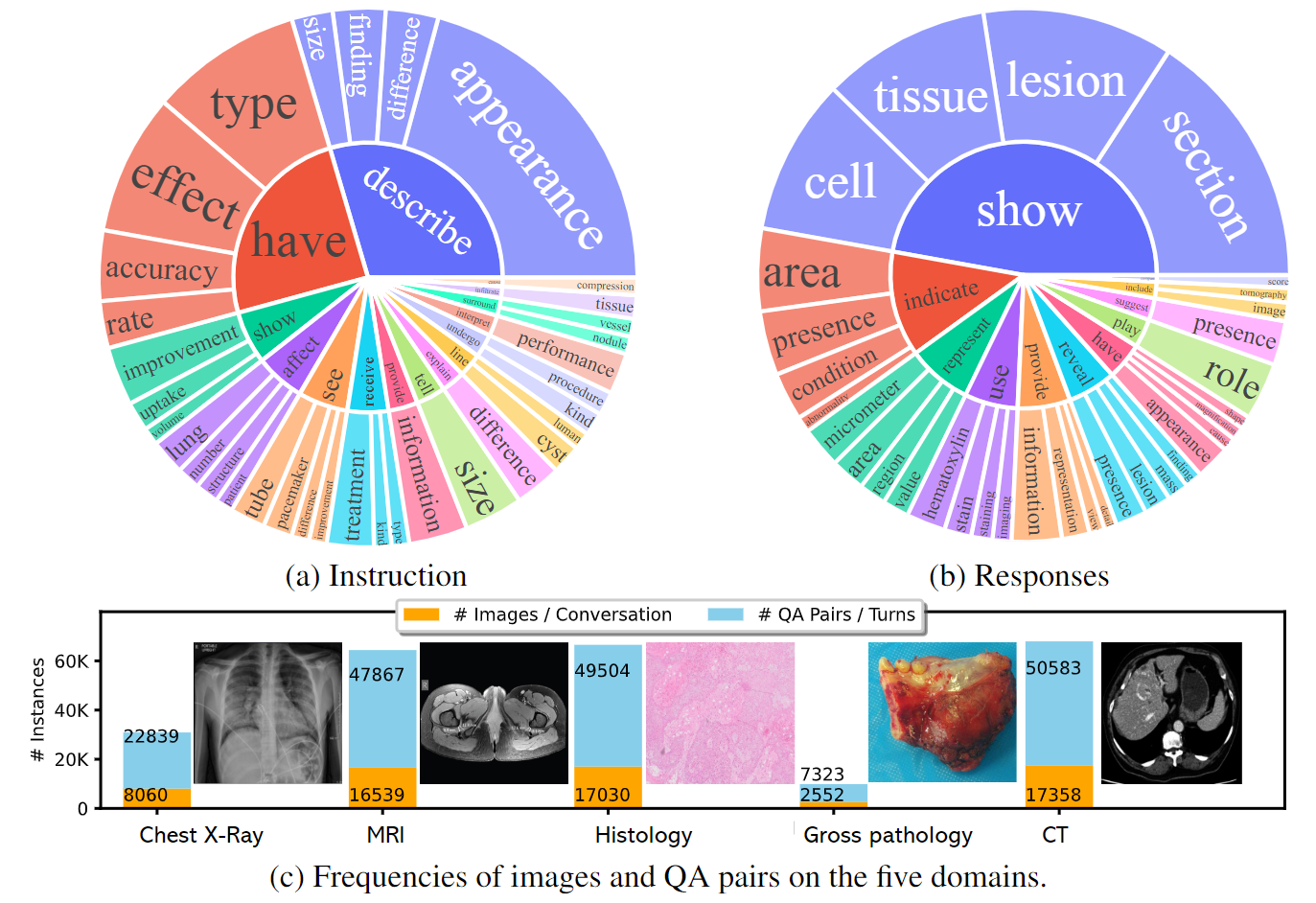
研究人员可以基于LLaVA-Med进行进一步的改进和定制化开发,例如:
- 针对特定疾病或医学领域的专门模型
- 结合本地数据集进行微调,提高在特定场景下的表现
- 探索新的多模态AI应用,如自动报告生成、辅助诊断系统等
性能评估与未来展望
在多个标准生物医学视觉问答数据集上,LLaVA-Med展现出了优异的性能,在某些指标上甚至超越了之前的监督学习状态。这不仅证明了模型的有效性,也为未来的研究指明了方向。
然而,研究团队也强调,LLaVA-Med目前仍然存在一些限制:
- 模型主要基于英语语料训练,对其他语言的支持有限
- 虽然性能优异,但仍不适合直接用于临床决策
- 可能存在数据偏差,需要在实际应用中谨慎处理
未来,研究团队计划进一步扩展LLaVA-Med的能力,包括:
- 增加对更多语言和文化背景的支持
- 提高模型在稀有病例和复杂情况下的表现
- 探索与其他医疗AI系统的集成,打造更全面的智能医疗生态系统
结语
LLaVA-Med的诞生标志着生物医学AI进入了一个新的时代。它不仅展示了大规模语言模型在专业领域的潜力,也为医疗健康行业的数字化转型提供了强大动力。虽然目前该技术还主要局限于研究用途,但我们有理由相信,在不久的将来,像LLaVA-Med这样的AI助手将成为医生、研究人员甚至患者的得力助手,共同推动医学科技的进步,造福人类健康。
作为这一领域的开创性工作,LLaVA-Med无疑将激发更多创新研究。我们期待看到更多基于这一技术的突破性应用,以及它们如何重塑未来的医疗保健landscape。
对于那些对生物医学AI感兴趣的研究者和开发者,LLaVA-Med项目无疑是一个极具价值的资源。无论是深入研究其训练方法,还是基于其架构开发新的应用,这个项目都为大家开启了无限可能。让我们共同期待LLaVA-Med及其衍生技术在未来为人类健康事业带来的巨大贡献!
📌 注意: LLaVA-Med目前仅供研究使用,不应用于任何临床决策或诊断。在将此类技术应用于实际医疗场景之前,还需要更多的研究、验证和监管审批。











