
LLM-eval-survey学习资料汇总 - 大型语言模型评估综述
大型语言模型(LLM)的评估是一个日益重要的研究领域。本文为您汇总了LLM-eval-survey项目的相关学习资料,帮助您快速了解和入门LLM评估研究。
项目简介
LLM-eval-survey是一个关于大型语言模型评估的综述项目,由多所高校和研究机构的学者合作完成。该项目旨在全面系统地总结LLM评估的研究现状,涵盖评估方法、评估指标、评估数据集等多个方面。
核心论文
项目的核心论文是《A Survey on Evaluation of Large Language Models》,发表于arXiv。该论文全面回顾了LLM评估的研究进展,是入门LLM评估领域的重要参考文献。
论文链接:https://arxiv.org/abs/2307.03109
代码仓库
项目在GitHub上维护了一个代码仓库,收集整理了大量LLM评估相关的论文和资源。该仓库是学习和跟踪LLM评估最新进展的宝贵资料库。
仓库地址:https://github.com/MLGroupJLU/LLM-eval-survey
评估框架
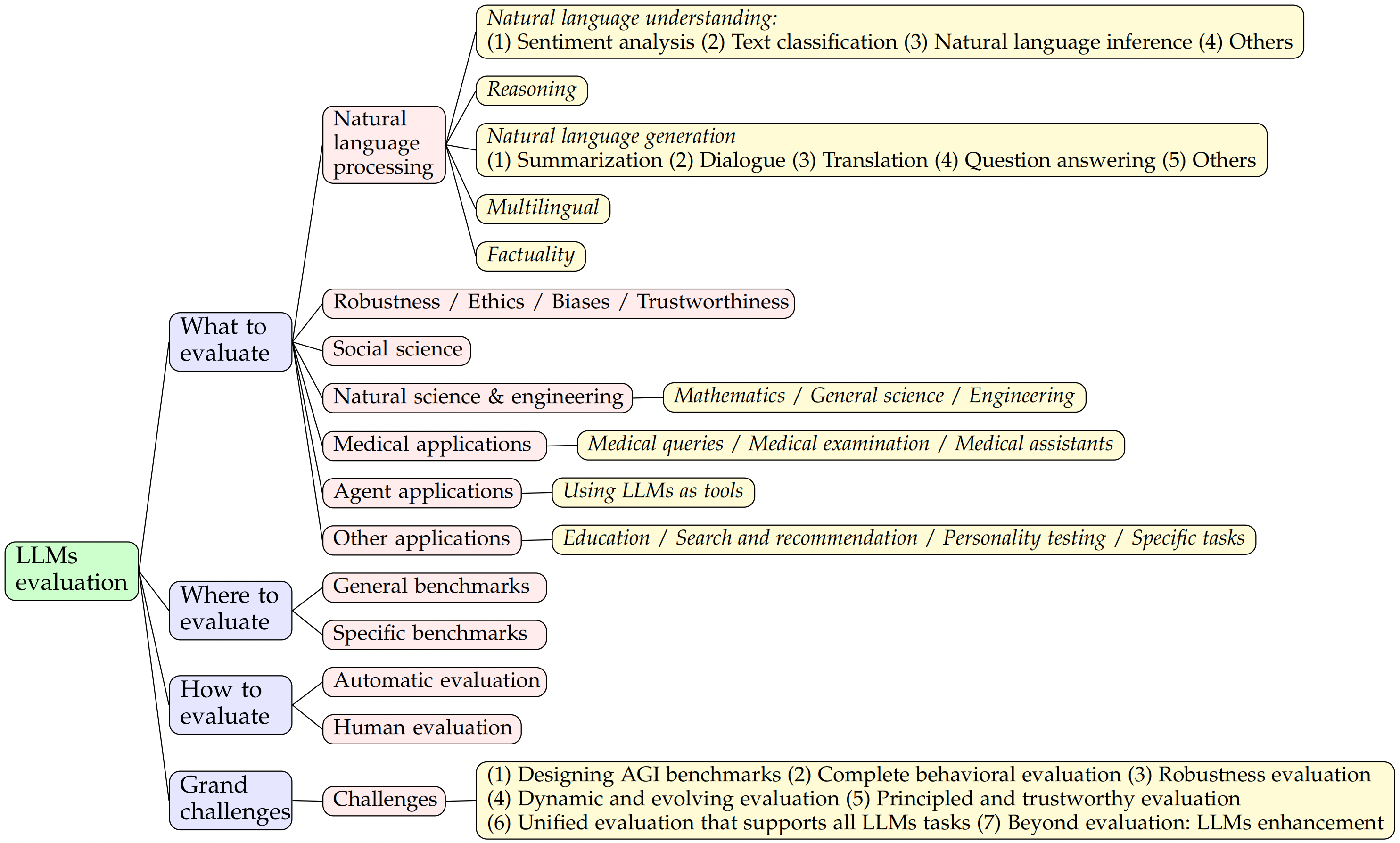
如上图所示,该项目提出了一个系统的LLM评估框架,从"评估什么"、"在哪里评估"和"如何评估"三个维度对LLM评估进行了分类。这个框架有助于我们全面把握LLM评估的研究全貌。
主要研究方向
根据该项目的分类,LLM评估主要包括以下几个研究方向:
- 自然语言处理能力评估
- 推理能力评估
- 鲁棒性评估
- 伦理和偏见评估
- 可信度评估
- 特定领域应用评估(如医疗、法律等)
相关资源
- LLM评估数据集:BIG-bench、HELM等
- 评估工具:PromptBench
- 多语言评估:XGLUE、XTREME等
总结
LLM-eval-survey项目为我们提供了一个系统学习LLM评估的框架和资源。无论您是初学者还是该领域的研究者,都可以从该项目中获得有价值的信息和启发。随着LLM技术的快速发展,对LLM进行全面、客观的评估将变得越来越重要。希望本文能为您了解和开展LLM评估研究提供帮助。
欢迎访问项目主页和GitHub仓库,了解更多详细信息!



















