
LLM-MovieAgent: 连接大语言模型与图数据库的桥梁
在人工智能和数据科学快速发展的今天,如何有效地将大语言模型(LLM)与结构化数据库结合,成为了一个备受关注的研究方向。GitHub 上的开源项目 LLM-MovieAgent 为这一问题提供了一个富有创意的解决方案,它巧妙地将 OpenAI 的大语言模型与 Neo4j 图数据库连接起来,打造了一个智能的电影推荐和查询系统。
项目概览
LLM-MovieAgent 的核心理念是在大语言模型和图数据库之间构建一个语义层。这个语义层不仅仅是一个简单的接口,而是一套复杂的工具集,能够让 LLM 根据用户的意图智能地与数据库进行交互。项目的创建者 Tomaz Bratanic 在他的博客文章中详细阐述了这一概念。
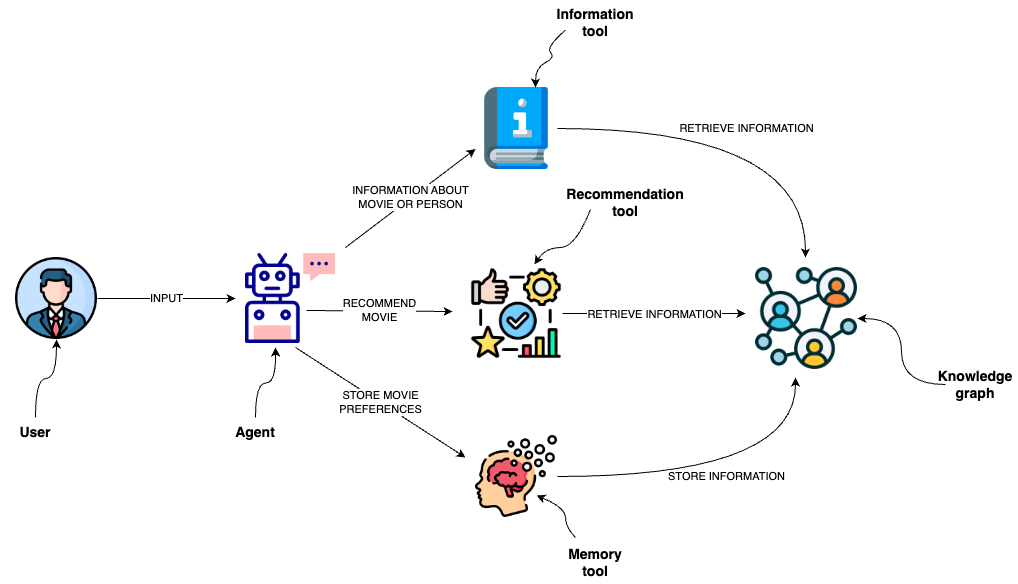
上图展示了 LLM-MovieAgent 的工作流程,直观地说明了语义层是如何协调 LLM 和图数据库的交互的。
技术栈和核心组件
LLM-MovieAgent 的技术栈主要包括以下几个部分:
- Neo4j 图数据库:用于存储电影、演员和用户评分等信息。
- OpenAI 的大语言模型:负责理解用户输入并生成响应。
- LangChain:使用其
neo4j-semantic-layer模板来实现 OpenAI LLM 和函数调用功能。 - Streamlit:提供简洁的聊天用户界面。
- Docker:用于容器化部署整个应用。
项目的核心在于其设计的三个工具:
- 信息工具:从数据库中检索电影或个人信息。
- 推荐工具:根据用户偏好和输入提供电影推荐。
- 记忆工具:将用户偏好存储在知识图谱中,实现个性化的长期交互体验。
项目设置和使用
要运行 LLM-MovieAgent,您需要按照以下步骤进行:
- 克隆项目仓库。
- 在
.env文件中设置必要的环境变量,包括 OpenAI API 密钥和 Neo4j 数据库连接信息。 - 使用 Docker Compose 启动项目:
docker-compose up
- 在浏览器中访问
http://localhost:8501即可与代理进行交互。
数据填充
项目提供了一个 ingest.py 脚本,用于将示例电影数据集导入到 Neo4j 数据库中。这个数据集基于 MovieLens 数据,包含了电影信息和用户评分。运行脚本的方法如下:
# 进入 API 容器的 shell
docker exec -it <container id for llm-movieagent-api> bash
# 运行脚本
python ingest.py
脚本还会创建两个全文索引,用于将用户输入映射到数据库中的信息。
项目的创新性和应用前景
LLM-MovieAgent 项目的创新性主要体现在以下几个方面:
-
语义层概念:通过引入语义层,项目解决了 LLM 与结构化数据库之间的沟通障碍,为两者的协同工作提供了新的思路。
-
个性化推荐:利用图数据库的关系模型和 LLM 的自然语言处理能力,项目能够提供更加精准和个性化的电影推荐。
-
交互式体验:用户可以通过自然语言与系统进行对话,获取电影信息或推荐,这大大提升了用户体验。
-
可扩展性:虽然当前项目专注于电影领域,但其架构设计使得它可以轻松扩展到其他领域,如图书推荐、音乐推荐等。
-
开源协作:作为一个开源项目,LLM-MovieAgent 为社区提供了一个研究和改进 LLM 与图数据库交互的平台。
未来展望
LLM-MovieAgent 项目展示了 AI 与数据库技术结合的巨大潜力。随着项目的不断发展,我们可以期待看到:
- 更复杂的查询和推荐算法的实现。
- 支持多语言交互,扩大用户群。
- 引入更多数据源,丰富知识图谱。
- 优化性能,提高响应速度和准确率。
- 探索在其他领域的应用,如教育、医疗等。
结语
LLM-MovieAgent 项目为我们展示了一个令人兴奋的前景:通过智能地结合大语言模型和图数据库,我们可以创造出更加智能、个性化和用户友好的应用。这个项目不仅仅是一个电影推荐系统,更是一个探索 AI 与数据交互新范式的尝试。随着技术的不断进步和社区的积极参与,我们有理由相信,类似 LLM-MovieAgent 这样的项目将在未来扮演越来越重要的角色,为用户提供更加智能和个性化的服务体验。
💡 如果您对 AI、数据库或推荐系统感兴趣,不妨深入研究这个项目,或者考虑为其贡献代码。开源社区的力量将推动这类创新性项目不断向前发展,为 AI 应用开辟新的可能性。









