
LongLM:让大语言模型自我延伸上下文窗口
大型语言模型(LLM)在处理长文本时往往受限于其固定的上下文窗口大小。传统上,要扩展模型的上下文窗口通常需要进行昂贵的微调过程。然而,来自德克萨斯A&M大学的研究团队提出了一种创新的方法 - LongLM,它可以让LLM在无需任何微调的情况下自我扩展其上下文窗口。这项技术不仅大大提高了LLM处理长文本的能力,还为自然语言处理领域带来了新的可能性。
LongLM的核心理念
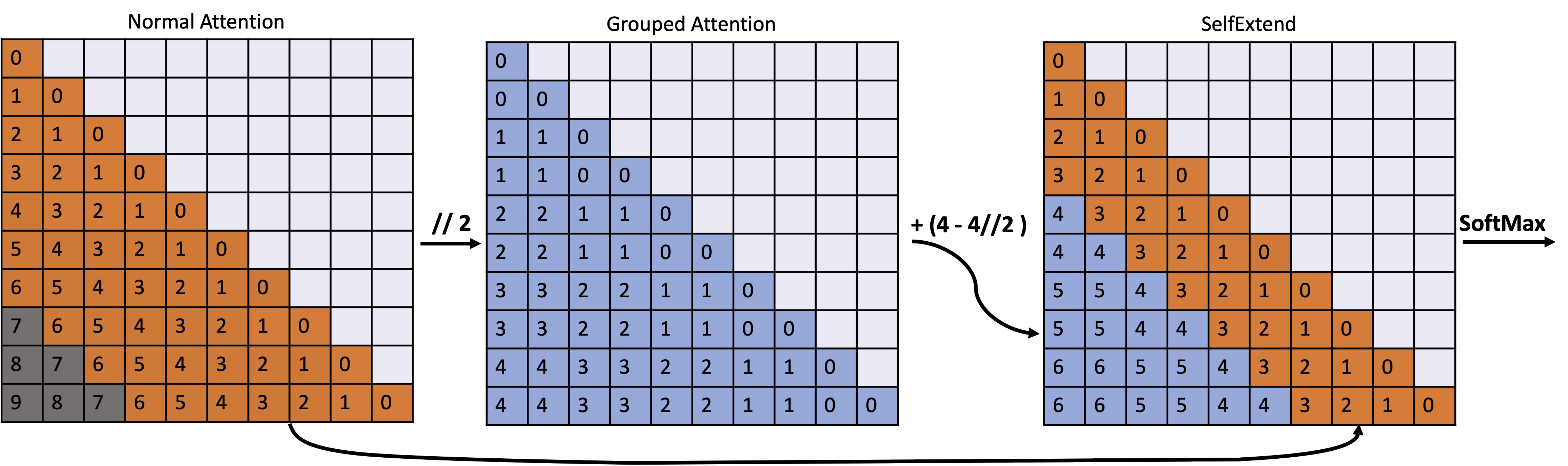
LongLM的核心思想是激发LLM处理长上下文的潜在能力。研究人员认为,现有的LLM本身就具备处理长上下文的内在能力,只是需要一种合适的方法来充分利用这种能力。基于这一观点,他们提出了"Self-Extend"(自我扩展)的概念,通过构建双层注意力信息来刺激LLM的长上下文处理潜力。
双层注意力机制
LongLM的关键在于其独特的双层注意力机制:
- 组级别(Group Level):捕捉相距较远的token之间的依赖关系。
- 邻居级别(Neighbor Level):捕捉指定范围内相邻token之间的依赖关系。
这两个层次的注意力信息都是由原始模型的自注意力机制计算得出,这意味着整个过程不需要额外的训练。通过这种方式,LongLM可以有效地扩展模型的上下文窗口,使其能够处理远超原始训练序列长度的输入。
LongLM的实现与应用
LongLM的实现相对简单,主要涉及对现有LLM架构的轻微修改。研究团队提供了适用于多种流行LLM的实现,包括Llama、Mistral、Phi-2等。使用LongLM只需几行代码即可完成:
import SelfExtend
# 加载模型
loaded_model = AutoModelForCausalLM.from_pretrained(model_path)
# 应用Self-Extend
SelfExtend.apply(loaded_model, group_size, window_size)
# 进行推理
loaded_model.generate(...)
其中,group_size和window_size是两个关键参数,分别控制组级别和邻居级别注意力的范围。研究人员提供了一些经验法则来帮助选择这些参数,但也强调LongLM对超参数的选择并不十分敏感。
LongLM的性能与优势
LongLM在多个长文本处理任务上展现出了卓越的性能。特别是在"Needle in a Haystack"(大海捞针)任务中,LongLM显著提高了模型在长文本中定位关键信息的能力。研究结果表明,即使在处理远超原始训练长度的输入时,LongLM也能保持较高的准确性。
LongLM的主要优势包括:
- 无需微调:直接扩展现有模型的能力,节省时间和计算资源。
- 灵活性强:适用于多种LLM架构,易于集成。
- 性能提升显著:在长文本处理任务中表现优异。
- 资源效率高:不需要额外的参数或复杂的训练过程。
LongLM的未来展望
LongLM的出现为LLM的应用开辟了新的可能性。它不仅提高了模型处理长文本的能力,还为研究人员提供了一个探索LLM内在能力的新视角。未来,LongLM可能在以下方面产生重要影响:
- 长文档分析:提高LLM在处理长篇文档、报告或书籍时的效率和准确性。
- 对话系统:增强聊天机器人在长对话中保持上下文连贯性的能力。
- 信息检索:改善在大规模文本数据中搜索和提取相关信息的能力。
- 跨文档推理:促进LLM在多个长文档之间进行复杂推理的能力。
结语
LongLM代表了自然语言处理领域的一个重要突破。通过巧妙地利用LLM的内在能力,它为解决长文本处理的挑战提供了一种创新且高效的方法。随着研究的深入和技术的完善,我们可以期待LongLM在更多实际应用中发挥重要作用,推动自然语言处理技术向前发展。
对于那些对LLM技术感兴趣的研究者和开发者来说,LongLM无疑是一个值得关注和尝试的项目。它不仅提供了一种新的思路来提升LLM的能力,还为探索和理解这些复杂模型的内部工作机制提供了宝贵的机会。随着更多人加入到这项技术的研究和应用中,我们有理由相信,LongLM将在推动自然语言处理技术的进步中发挥越来越重要的作用。










