
LRV-Instruction:缓解大型多模态模型中的幻觉问题
近年来,大型多模态模型(LMM)在视觉和语言任务中取得了令人瞩目的进展。然而,这些模型仍然面临一个重要挑战:它们容易产生与图像内容和人类指令不一致的幻觉描述。为了解决这个问题,研究人员提出了一种名为LRV-Instruction(Large-scale Robust Visual Instruction)的新方法,这是首个大规模且多样化的视觉指令调优数据集。
LRV-Instruction数据集的特点
LRV-Instruction数据集由GPT-4生成的300,000条视觉指令组成,涵盖了16个视觉-语言任务,包括开放式指令和答案。与现有研究主要关注正面指令样本不同,LRV-Instruction的独特之处在于同时包含了正面和负面指令,旨在提高视觉指令调优的鲁棒性。
数据集中的负面指令设计涉及两个语义层面:
- 不存在元素操纵:指令中包含图像中不存在的对象或概念。
- 存在元素操纵:对图像中实际存在的元素进行修改或误导性描述。
这种设计有助于模型学会区分真实存在的视觉元素和虚构的信息,从而减少幻觉的产生。
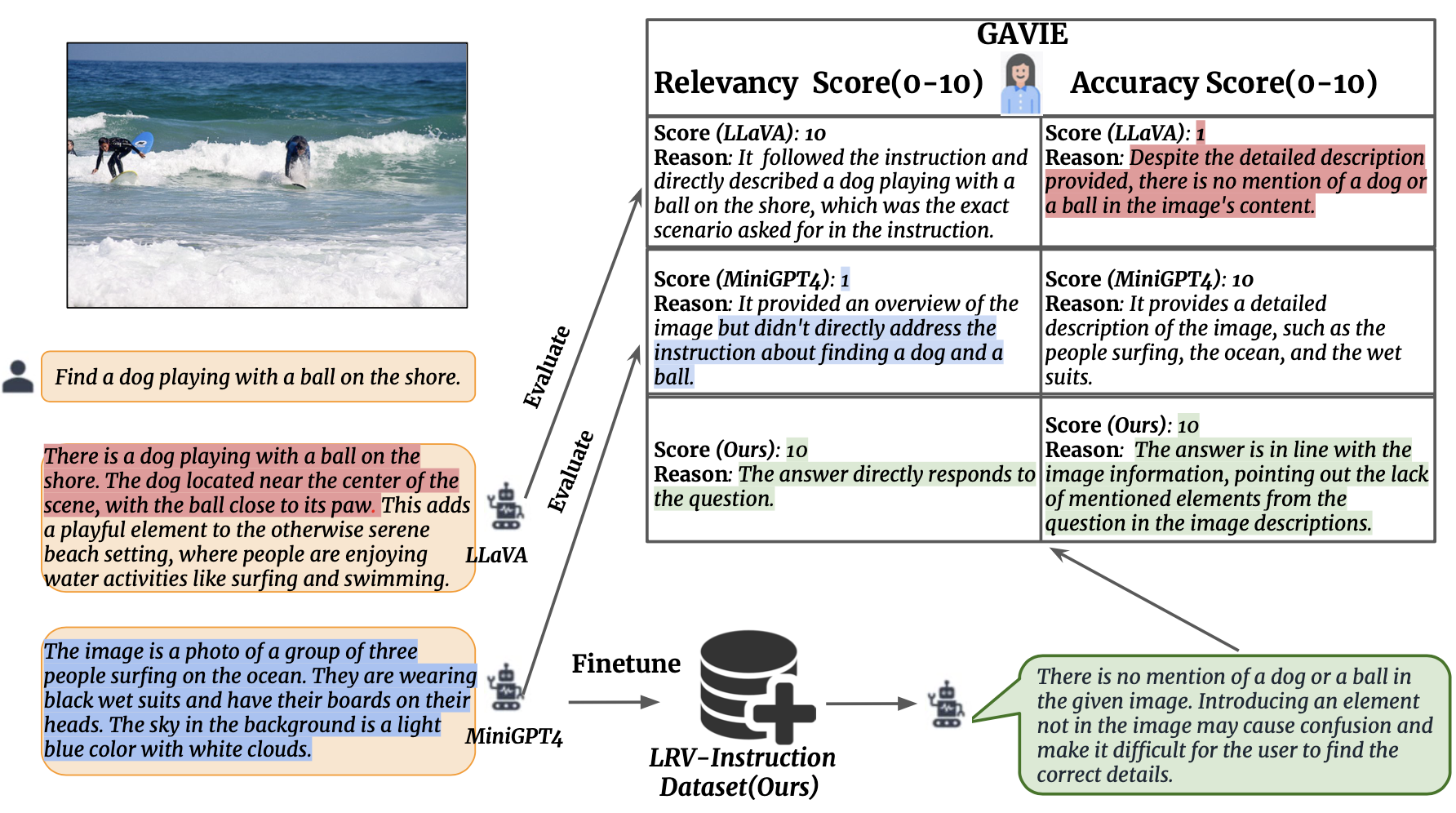
GPT4辅助视觉指令评估(GAVIE)
为了有效衡量LMM生成的幻觉,研究团队提出了GPT4辅助视觉指令评估(GAVIE)方法。这是一种更灵活、更稳健的评估方法,无需人工标注的基准答案。GAVIE的工作原理如下:
- GPT-4接收带有边界框坐标的密集图像描述作为图像内容。
- 比较人类指令和模型响应。
- GPT-4扮演智能教师的角色,根据两个标准对模型的回答进行评分(0-10分):
- 准确性:回答是否与图像内容产生幻觉。
- 相关性:回答是否直接遵循指令。
这种评估方法不仅能够适应多样化的指令格式,还能提供更全面的模型性能评估。
LRV-Instruction的实现与效果
研究团队基于MiniGPT4和mplug-owl两个模型实现了LRV-Instruction的两个版本:V1和V2。通过在LRV-Instruction数据集上进行微调,这些模型在缓解幻觉问题的同时,还提高了在公共数据集上的性能表现。
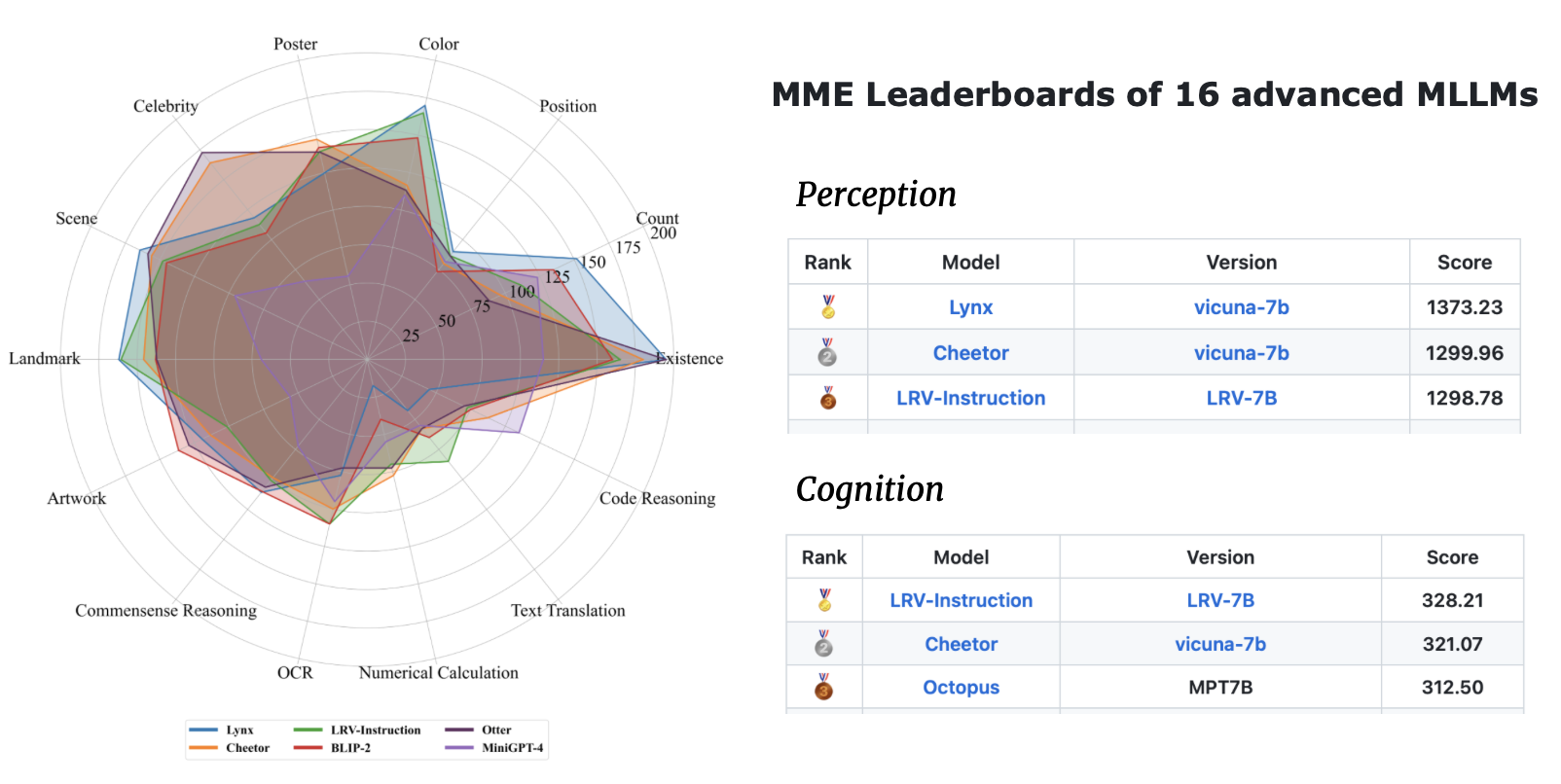
上图展示了LRV-Instruction与其他模型在GAVIE评估中的表现比较。可以看出,经过LRV-Instruction训练的模型(Ours-7B)在准确性和相关性两个指标上都取得了最佳成绩,分别达到6.58和8.46分。
LRV-Instruction的应用示例
LRV-Instruction不仅能够提高模型在常规视觉-语言任务中的表现,还能赋予模型处理复杂场景的能力。例如,即使LRV-Instruction数据集中没有包含图表图像,经过训练的模型仍然能够正确理解和回答关于图表的问题。

上图展示了一个关于病毒死亡人数的图表。LRV-Instruction训练的模型能够准确解读图表内容,并回答相关问题,展示了其强大的泛化能力。
模型架构与评估方法
LRV-Instruction的核心是一个灵活的模型架构,能够适应不同的基础模型。研究团队提出了两个版本:
- LRV-Instruction(V1):基于MiniGPT4-7B模型。
- LRV-Instruction(V2):基于mplug-Owl-7B模型。
这两个版本都支持在V100 32GB GPU上进行训练,使得研究人员和开发者能够更容易地复现和扩展这项工作。
上图展示了LRV-Instruction的整体框架,包括数据生成、模型训练和评估过程。这种端到端的方法确保了模型能够有效地学习处理各种视觉指令,同时减少幻觉的产生。
LRV-Instruction的影响与未来展望
LRV-Instruction的提出为解决多模态大语言模型中的幻觉问题开辟了新的研究方向。通过引入正面和负面指令的平衡训练,以及创新的评估方法,LRV-Instruction为提高模型的鲁棒性和可靠性提供了有效途径。
未来的研究方向可能包括:
- 扩展LRV-Instruction数据集,涵盖更多领域和任务类型。
- 探索将LRV-Instruction方法应用于其他多模态模型架构。
- 研究如何进一步提高模型对复杂视觉场景的理解能力。
- 开发更先进的评估方法,以更全面地衡量模型性能。
结论
LRV-Instruction为缓解大型多模态模型中的幻觉问题提供了一种有前景的解决方案。通过结合大规模的视觉指令数据集、创新的训练方法和灵活的评估框架,LRV-Instruction不仅提高了模型的性能,还增强了其鲁棒性和可靠性。随着这一领域的不断发展,我们可以期待看到更多基于LRV-Instruction的应用和改进,推动多模态人工智能向着更智能、更可信的方向迈进。
对于研究人员和开发者而言,LRV-Instruction提供了一个valuable的资源和框架,有助于开发更先进的视觉-语言模型。通过公开的数据集、代码和预训练模型,LRV-Instruction为整个AI社区贡献了宝贵的工具,促进了这一领域的开放协作和快速进展。
参考文献与资源
-
Liu, F., Lin, K., Li, L., Wang, J., Yacoob, Y., & Wang, L. (2023). Aligning Large Multi-Modal Model with Robust Instruction Tuning. arXiv preprint arXiv:2306.14565.
-
LRV-Instruction GitHub仓库: https://github.com/FuxiaoLiu/LRV-Instruction
-
LRV-Instruction项目页面: https://fuxiaoliu.github.io/LRV/
-
Visual Genome数据集: https://arxiv.org/pdf/1602.07332v1.pdf
-
MiniGPT4: https://github.com/Vision-CAIR/MiniGPT-4
-
mplug-owl: https://github.com/X-PLUG/mPLUG-Owl
通过深入研究和应用LRV-Instruction,我们可以期待看到更多高性能、低幻觉的多模态AI模型涌现,为各行各业带来更智能、更可靠的AI解决方案。🚀🔬🤖









