
Luminaire: 智能化的时间序列异常检测利器
在当今数据驱动的世界中,时间序列数据的监控和异常检测变得越来越重要。无论是在金融、电子商务、物联网还是其他领域,能够及时发现时间序列数据中的异常对于业务运营和决策制定都至关重要。然而,时间序列数据通常具有复杂的模式和特征,如趋势、季节性、周期性等,这使得异常检测成为一项具有挑战性的任务。为了应对这一挑战,Zillow集团的AI团队开发了Luminaire - 一个强大而灵活的Python库,专门用于时间序列数据的异常检测和监控。
Luminaire的核心优势
Luminaire的设计理念是提供一个"hands-off"(无需人工干预)的异常检测解决方案。它具有以下几个关键优势:
-
自动化配置: Luminaire内置了配置优化组件,可以自动为不同类型的时间序列数据选择最佳的模型参数,大大减少了人工调参的工作量。
-
多模型支持: 该库集成了多种结构化时间序列模型和基于滤波的模型,可以适应不同特征的时间序列数据。
-
数据预处理: Luminaire提供了强大的数据预处理功能,包括缺失值插补、异常值识别和移除、数据转换等,为后续的建模提供干净可靠的数据。
-
高频数据支持: 除了传统的逐点异常检测,Luminaire还支持对高频时间序列数据进行窗口化处理,更适合流式数据的监控场景。
-
可解释性: 该库不仅提供异常检测结果,还可以生成数据的概况信息,如历史变点、趋势变化等,有助于理解数据的长期行为。
Luminaire的工作流程
Luminaire的异常检测工作流程主要包含三个核心组件:
-
数据预处理和概况分析组件
这一步骤会对原始时间序列数据进行一系列预处理,包括:
- 缺失值插补
- 识别并移除训练数据中的近期异常点
- 必要的数据转换
- 基于最近的变点进行数据截断
同时,该组件还会生成数据的概况信息,如历史变点、趋势变化等。这些信息可以用于监控数据漂移和长期不规则波动。
-
建模组件
Luminaire的建模过程可以基于用户指定的配置,也可以使用优化后的配置。它集成了多种结构化时间序列模型和基于滤波的模型。建模步骤会在数据预处理之后进行,确保模型训练使用的是经过充分准备的数据。
-
配置优化组件
这是Luminaire实现"hands-off"异常检测的关键。用户只需提供最少的配置信息,优化组件就能自动为各种类型的时间序列数据选择最佳的模型参数。这大大简化了异常检测的配置过程,使得Luminaire能够更容易地应用于大规模的时间序列监控任务。
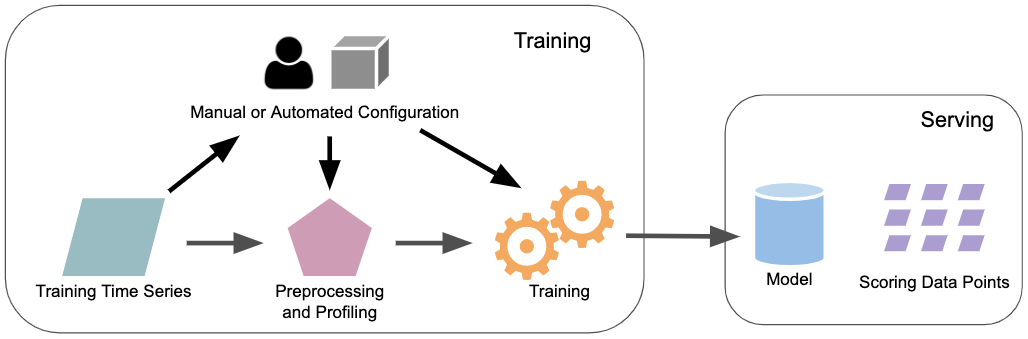
使用Luminaire进行异常检测
下面我们通过两个简单的例子来展示如何使用Luminaire进行批处理和流式时间序列的异常检测。
批处理时间序列监控
import pandas as pd
from luminaire.optimization.hyperparameter_optimization import HyperparameterOptimization
from luminaire.exploration.data_exploration import DataExploration
# 加载数据
data = pd.read_csv('Path to input time series data')
# 输入数据应该有一个时间列作为dataframe的索引列,以及一个名为'raw'的值列
# 优化配置
hopt_obj = HyperparameterOptimization(freq='D')
opt_config = hopt_obj.run(data=data)
# 数据预处理和概况分析
de_obj = DataExploration(freq='D', **opt_config)
training_data, pre_prc = de_obj.profile(data)
# 确定模型类型
model_class_name = opt_config['LuminaireModel']
module = __import__('luminaire.model', fromlist=[''])
model_class = getattr(module, model_class_name)
# 训练模型
model_object = model_class(hyper_params=opt_config, freq='D')
success, model_date, trained_model = model_object.train(data=training_data, **pre_prc)
# 异常检测
trained_model.score(100, '2021-01-01')
流式时间序列监控
import pandas as pd
from luminaire.model.window_density import WindowDensityHyperParams, WindowDensityModel
from luminaire.exploration.data_exploration import DataExploration
# 加载数据
data = pd.read_csv('Path to input time series data')
# 输入数据应该有一个时间列作为dataframe的索引列,以及一个名为'raw'的值列
# 配置和数据预处理
config = WindowDensityHyperParams().params
de_obj = DataExploration(**config)
data, pre_prc = de_obj.stream_profile(df=data)
config.update(pre_prc)
# 训练模型
wdm_obj = WindowDensityModel(hyper_params=config)
success, training_end, model = wdm_obj.train(data=data)
# 异常检测
score, scored_window = model.score(scoring_data) # scoring_data是一个时间窗口内的数据,而不是单个数据点
Luminaire的应用前景
Luminaire作为一个功能强大且易于使用的时间序列异常检测库,在多个领域都有广泛的应用前景:
-
金融市场监控: 可用于检测股票价格、交易量等金融指标的异常波动,帮助投资者及时发现市场异常。
-
电子商务: 可监控网站流量、订单数量、用户行为等指标,及时发现销售异常或系统问题。
-
IoT和工业监控: 可用于监测设备运行状态、生产线效率等,提前预警可能的设备故障或生产异常。
-
网络安全: 可监控网络流量、系统日志等,检测潜在的安全威胁和异常活动。
-
智慧城市: 可用于监控交通流量、能源消耗、空气质量等城市指标,帮助管理者及时发现并解决城市问题。
-
医疗健康: 可用于监测患者生命体征、医疗设备运行状态等,提高医疗安全性和效率。
结语
Luminaire作为一个开源项目,不仅为时间序列异常检测提供了强大的工具,也为整个数据科学社区贡献了宝贵的资源。它的"hands-off"设计理念和灵活的架构使得它能够适应各种复杂的时间序列数据,无论是在学术研究还是在工业应用中都具有巨大的潜力。
随着数据驱动决策在各行各业变得越来越重要,Luminaire这样的工具将在未来扮演更加重要的角色。它不仅能帮助数据科学家和工程师更高效地进行异常检测,还能使得这项技术更容易被广大用户所采用,从而推动整个行业向前发展。
对于那些对时间序列分析和异常检测感兴趣的开发者和研究者来说,深入研究Luminaire的源代码,参与项目的开发和改进,无疑是一个很好的学习和贡献机会。我们期待看到更多基于Luminaire的创新应用和研究成果,共同推动时间序列分析技术的进步。









