
Mango简介
Mango是一个强大的Python库,专门用于为机器学习分类器寻找最优超参数。它支持在复杂的搜索空间中进行并行优化,可以处理连续、离散和分类值。
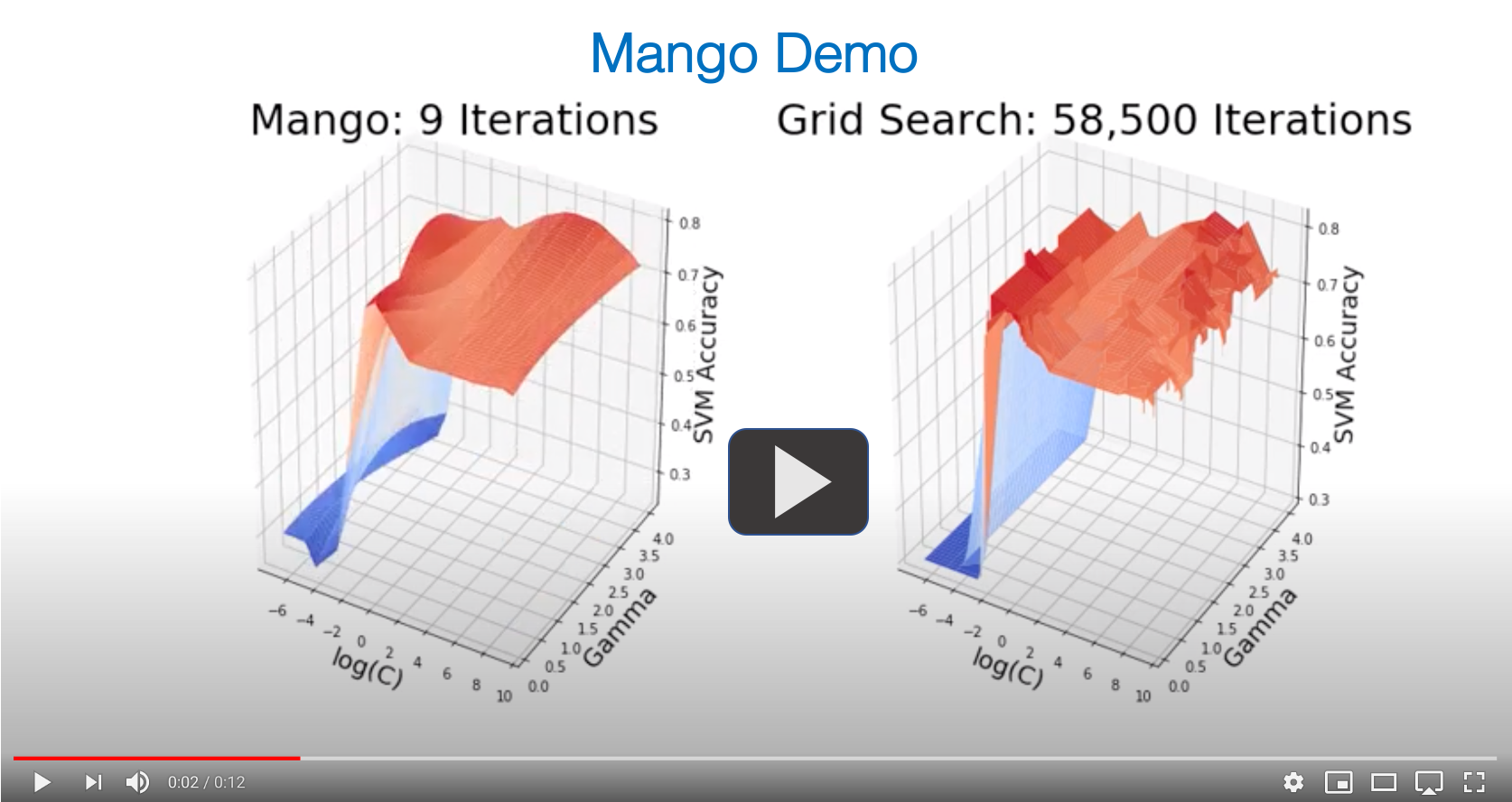
Mango具有以下突出特点:
- 易于定义复杂的搜索空间,与scikit-learn兼容
- 采用先进的无梯度优化器,可处理连续/离散/分类值
- 模块化设计,可在本地、集群或云基础设施上调度目标函数
- 应用层的故障检测,提高在普通硬件上的可扩展性
- 在生产环境中持续测试和使用,不断添加新功能
安装
可以通过pip安装Mango:
pip install mango-optimizer
也可以从源码安装:
git clone https://github.com/ARM-software/mango.git
cd mango
pip install .
快速入门
Mango使用起来非常简单。下面是一个最小化整数输入平方函数的示例:
from mango import scheduler, Tuner
# 定义搜索空间
param_space = dict(x=range(-10,10))
# 目标函数
@scheduler.serial
def objective(x):
return x * x
# 初始化并运行Tuner
tuner = Tuner(param_space, objective)
results = tuner.minimize()
print(f'最优参数: {results["best_params"]} 目标值: {results["best_objective"]}')
# => 最优参数: {'x': 0} 目标值: 0
超参数调优示例
下面是一个使用Mango来调优KNN分类器超参数的完整示例:
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score
from mango import Tuner, scheduler
# KNN分类器超参数搜索空间
param_space = dict(
n_neighbors=range(1, 50),
algorithm=['auto', 'ball_tree', 'kd_tree', 'brute']
)
@scheduler.serial
def objective(**params):
X, y = datasets.load_breast_cancer(return_X_y=True)
clf = KNeighborsClassifier(**params)
score = cross_val_score(clf, X, y, scoring='accuracy').mean()
return score
tuner = Tuner(param_space, objective)
results = tuner.maximize()
print('最优参数:', results['best_params'])
print('最佳准确率:', results['best_objective'])
搜索空间定义
Mango的搜索空间定义与scikit-learn兼容。搜索空间通过一个字典来定义,键是参数名,值是离散选项列表、整数范围或概率分布。
一些常见的搜索空间定义示例:
整数参数
param_space = dict(x=range(-10, 11)) # -10到10
param_space = dict(x=range(0, 101, 10)) # 0到100,步长为10
分类参数
param_space = dict(color=['red', 'blue', 'green'])
param_space = dict(v=[0.2, 0.1, 0.3])
param_space = dict(max_features=['auto', 0.2, 0.3])
概率分布
from scipy.stats import uniform
from mango.domain.distribution import loguniform
param_space = dict(
a=uniform(-1, 2), # 在-1到1之间均匀分布
learning_rate=loguniform(-3, 2) # 在10^-3到10^-1之间对数均匀分布
)
调度器
Mango设计为可以利用分布式计算。目标函数可以调度在本地或集群上并行执行。Mango支持使用任何分布式计算框架(如Celery或Kubernetes)。
串行调度器
from mango import scheduler
@scheduler.serial
def objective(x):
return x * x
并行调度器
from mango import scheduler
@scheduler.parallel(n_jobs=2)
def objective(x):
return x * x
自定义分布式调度器
用户可以定义自己的分布策略:
from mango import scheduler
@scheduler.custom(n_jobs=4)
def objective(params_batch):
# 在分布式框架上评估目标函数
...
return results
可选配置
Mango提供了一些可选的配置参数:
- domain_size: 每次迭代探索的大小
- initial_random: 随机采样的次数
- num_iteration: 总迭代次数
- batch_size: 并行评估的批量大小
- early_stopping: 自定义提前停止条件
- constraint: 参数空间约束条件
- initial_custom: 自定义初始评估点
- scale_params: 是否对搜索空间进行缩放
可以通过配置字典修改这些选项:
conf_dict = dict(num_iteration=40, domain_size=10000, initial_random=3)
tuner = Tuner(param_dict, objective, conf_dict)
其他特性
处理运行时失败
Mango可以处理运行时的评估失败,只使用成功的评估继续优化。
神经架构搜索
Mango还可以进行高效的神经架构搜索,例如搜索最佳的滤波器大小、数量等。
分类器选择与优化(CASH)
Mango提供了一个新功能,可以同时进行分类器选择和超参数优化。用户可以直接指定一组分类器及其不同的超参数空间,Mango会用最少的迭代次数找到最佳分类器和最优参数。
参与贡献
欢迎参与Mango的开发!可以查看开放的issues寻找贡献机会。如果有任何问题,也可以创建issue进行提问。
总结
Mango是一个功能强大、易于使用的超参数优化库。它支持复杂搜索空间的并行优化,具有高度的灵活性和可扩展性。无论是用于科研还是生产环境,Mango都是一个值得尝试的优秀工具。希望本文能帮助读者了解Mango的主要特性和用法,开始使用Mango来优化你的机器学习模型!









