
MaxText: 开启大语言模型研究与应用的新篇章
在人工智能领域,大语言模型(LLM)的发展日新月异,不断刷新着人们对机器智能的认知。然而,训练和部署这些庞大的模型往往需要海量的计算资源和复杂的工程实现。为了让更多研究者和开发者能够参与到LLM的创新中来,Google推出了MaxText - 一个高性能、高度可扩展的开源LLM框架。
MaxText的核心特性
MaxText是一个用纯Python和JAX编写的LLM框架,专门针对Google Cloud TPU和GPU进行了优化。它具有以下几个突出特点:
-
高性能: MaxText能够实现很高的模型浮点运算利用率(MFU),充分发挥硬件性能。
-
高度可扩展: 从单机到超大规模集群,MaxText都能保持出色的扩展性。
-
开源: 完全开放源代码,鼓励社区参与和创新。
-
简单易用: 依托JAX和XLA编译器的强大功能,MaxText保持了简洁的代码结构,无需繁琐的手动优化。
-
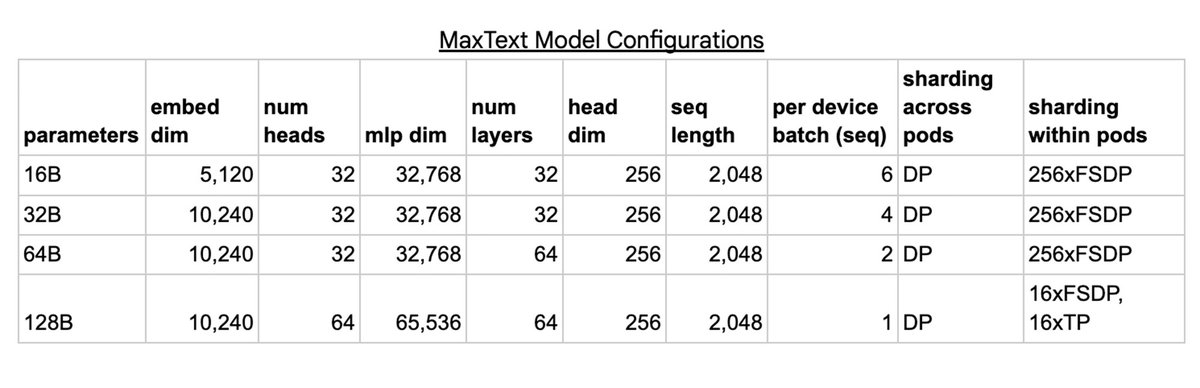
灵活性: 支持多种开源模型,如Llama2、Mistral和Gemma等。
MaxText的技术亮点
MaxText在设计和实现上采用了多项先进技术:
-
JAX框架: 利用JAX的自动微分和即时编译能力,实现高效的数值计算。
-
XLA编译器: 通过XLA编译器对计算图进行优化,提升硬件利用率。
-
分布式训练: 支持数据并行、模型并行等多种并行策略,实现大规模分布式训练。
-
量化训练: 集成了Accurate Quantized Training (AQT)库,支持INT8量化训练,进一步提升性能。
-
自动化编排: 利用XPK (Accelerated Processing Kit)工具,简化了大规模集群上的作业管理。
MaxText的应用案例
Google利用MaxText进行了多项突破性的实验:
-
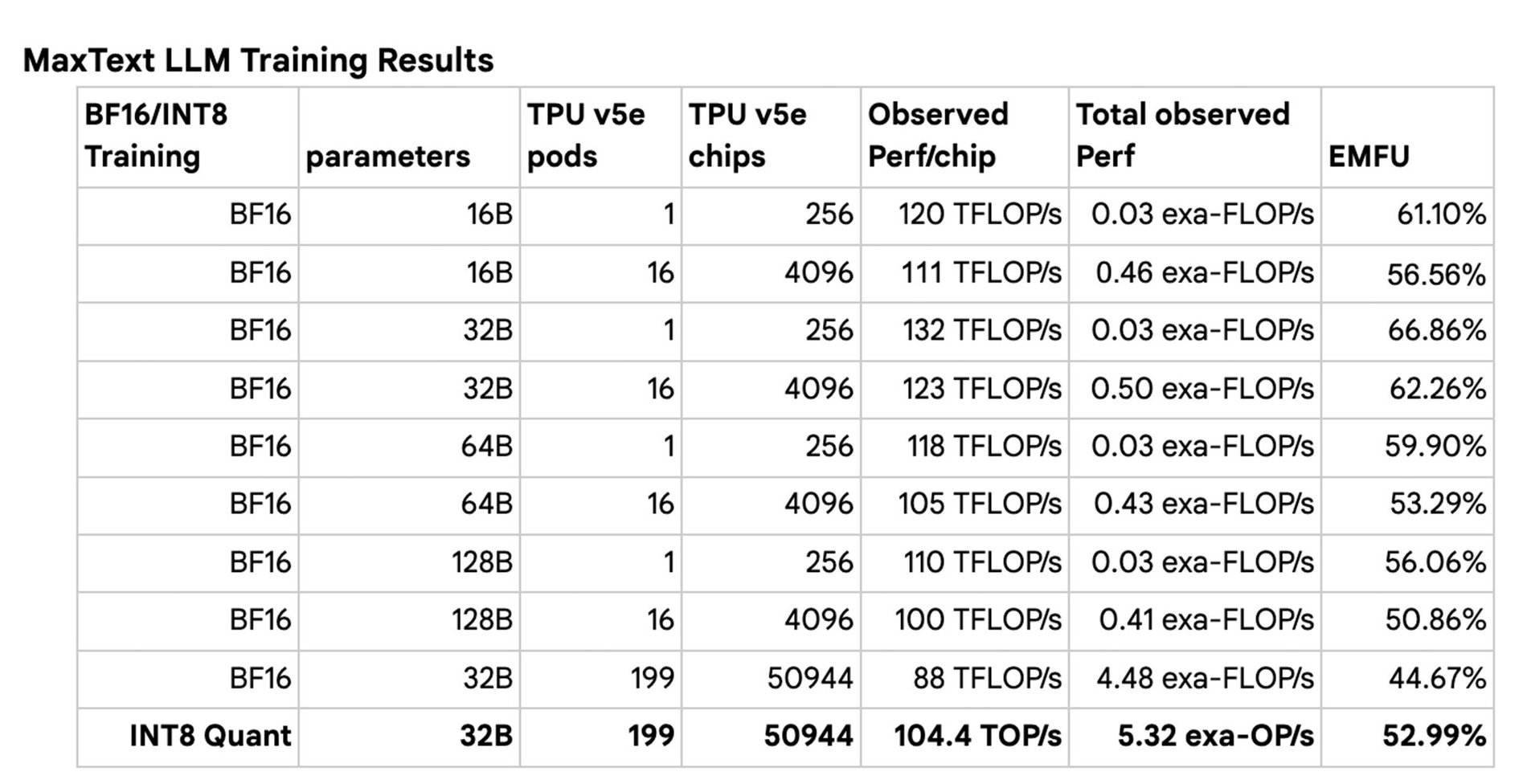
51K芯片规模训练: 在由50,944个Cloud TPU v5e芯片组成的集群上进行了迄今为止最大规模的LLM分布式训练。
-
INT8量化训练: 展示了在保持模型收敛性的同时,使用INT8量化进行高性能训练的可能性。
-
多种模型规模: 成功训练了从16B到128B参数的多种规模模型,验证了框架的灵活性。
MaxText与其他框架的比较
MaxText在设计理念上借鉴了多个优秀的开源项目,同时也有自己的独特之处:
-
相比MinGPT/NanoGPT,MaxText支持更多工业级模型,并且在MFU上有显著提升。
-
与Nvidia/Megatron-LM相比,MaxText采用纯Python实现,更加依赖XLA编译器而非手写CUDA核心。
-
相比Pax,MaxText更加注重简洁的实现,鼓励用户直接修改源代码来扩展功能。
使用MaxText进行LLM开发
对于想要使用MaxText进行LLM研究或应用开发的开发者,可以按照以下步骤开始:
-
克隆MaxText仓库:
git clone https://github.com/google/maxtext.git -
安装依赖: 运行
setup.sh脚本安装所需的Python包。 -
选择模型: MaxText支持多种开源模型,如Llama2、Mistral和Gemma等。
-
配置训练: 修改
configs/base.yml文件,设置模型参数、训练超参数等。 -
启动训练: 使用
train.py脚本开始训练过程。 -
监控与调试: 利用MaxText提供的诊断工具,如堆栈跟踪收集、提前编译(AOT)等功能进行优化。
MaxText的未来展望
作为一个活跃的开源项目,MaxText还在不断发展和完善中。未来的发展方向包括:
-
进一步提升大规模训练的效率和稳定性。
-
优化作业启动时间,提高资源利用率。
-
支持更多新兴的LLM架构和训练技术。
-
加强与云原生技术的集成,简化部署和运维。
-
扩大社区参与度,吸收更多创新ideas。
结语
MaxText为LLM的研究和应用开辟了一条新的道路。它不仅是一个高性能的训练框架,更是一个开放的创新平台。无论是学术研究者还是产业界开发者,都可以基于MaxText快速开展LLM相关工作,推动人工智能技术的进步。随着更多开发者的加入和贡献,相信MaxText将在未来的AI浪潮中发挥越来越重要的作用。
让我们一起期待MaxText带来的更多可能性!










