
MEGABYTE-pytorch:革新长序列建模的多尺度Transformer架构
在自然语言处理和序列建模领域,处理超长序列一直是一个巨大的挑战。传统的Transformer模型在处理长序列时往往会面临计算复杂度和内存消耗的瓶颈。为了突破这一限制,Meta AI研究团队提出了MEGABYTE(Multiscale Transformers for Predicting Million-byte Sequences)模型,这是一种创新的多尺度Transformer架构,能够高效地对超过100万字节的长序列进行建模和预测。本文将深入探讨MEGABYTE-pytorch的核心设计理念、技术特点及其在长序列建模领域的重要意义。
MEGABYTE模型的核心设计
MEGABYTE模型的设计灵感来源于对长序列特征的深入理解。研究人员发现,长序列通常包含多尺度的结构信息,从局部的字符级别到全局的段落级别。基于这一洞察,MEGABYTE采用了多尺度的架构设计,包括以下三个关键组件:
-
补丁嵌入器(Patch Embedder): 补丁嵌入器负责将输入的离散序列进行嵌入,并将其分割成固定长度的补丁。这一步骤为后续的多尺度处理奠定了基础。
-
全局模块(Global Module): 全局模块是一个大型的自回归Transformer,通过对先前补丁进行自注意力操作来上下文化补丁表示。这使得模型能够捕获长距离依赖关系。
-
局部模块(Local Module): 局部模块是一个小型的局部Transformer,它接收来自全局模型的上下文化补丁表示,并自回归地预测下一个补丁。这允许模型在局部范围内进行精细的建模。
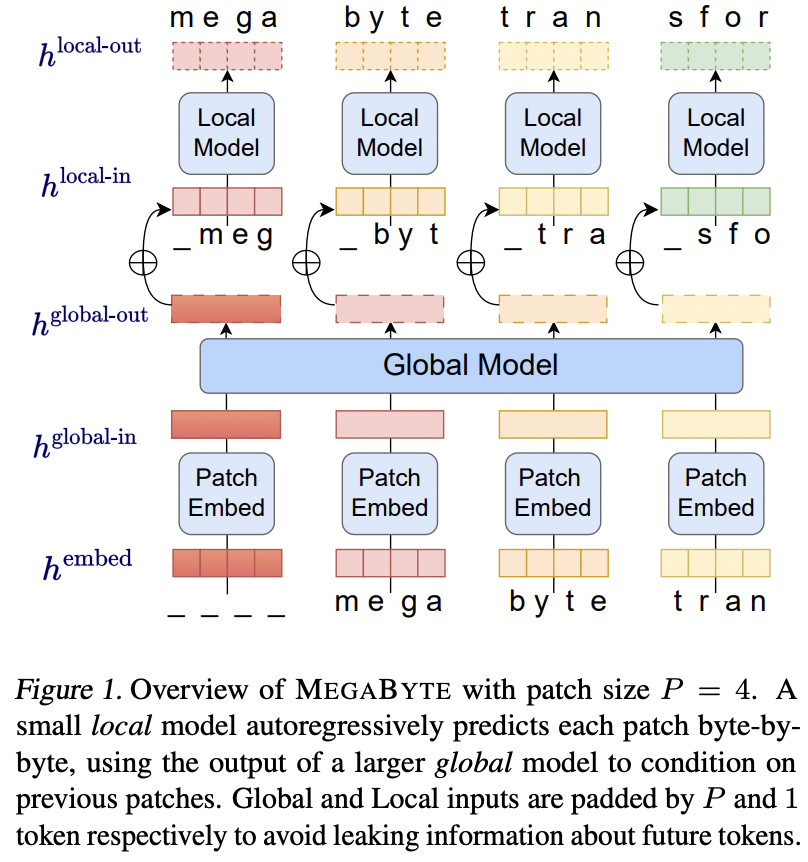
MEGABYTE模型架构概览
MEGABYTE的技术创新
MEGABYTE模型在长序列建模方面引入了几项重要的技术创新:
-
次平方自注意力机制: MEGABYTE通过将长序列分割成两个较短的序列,将自注意力的计算复杂度从O(N^2)降低到O(N^(4/3))。这大大提高了模型处理长序列的效率。
-
每补丁前馈层: 在GPT3规模的模型中,超过98%的计算量用于逐位置的前馈层。MEGABYTE通过对每个补丁而非每个位置使用大型前馈层,在相同计算成本下实现了更大、更强大的模型。
-
解码并行性: 传统Transformer必须串行处理所有计算。MEGABYTE允许在序列生成过程中对补丁进行并行处理,显著提高了生成速度。例如,在相同的计算资源下,一个1.5B参数的MEGABYTE模型可以比常规350M参数的Transformer生成序列快40%,同时还提高了困惑度。
MEGABYTE-pytorch的实现与使用
MEGABYTE-pytorch是MEGABYTE模型的PyTorch实现,由GitHub用户lucidrains开发。这个开源项目不仅忠实实现了原始MEGABYTE模型的核心功能,还进行了进一步的泛化,允许使用多个局部模型。
以下是MEGABYTE-pytorch的基本使用示例:
import torch
from MEGABYTE_pytorch import MEGABYTE
model = MEGABYTE(
num_tokens = 16000, # 词汇表大小
dim = (512, 256), # Transformer模型维度(512用于最粗粒度,256用于细粒度)
max_seq_len = (1024, 4), # 全局和局部的序列长度,可以超过2
depth = (6, 4), # 全局和局部的层数,可以超过2,但长度必须与max_seq_len匹配
dim_head = 64, # 每个注意力头的维度
heads = 8, # 注意力头的数量
flash_attn = True # 使用flash attention加速
)
x = torch.randint(0, 16000, (1, 1024, 4))
loss = model(x, return_loss = True)
loss.backward()
# 训练后可以用于生成
logits = model(x)
# 也可以使用generate函数进行采样
sampled = model.generate(temperature = 0.9, filter_thres = 0.9) # (1, 1024, 4)
MEGABYTE在内容生成领域的影响
MEGABYTE的出现为内容生成领域带来了新的可能性。传统模型在处理长序列时面临的挑战,如标记化、可扩展性和生成速度等问题,在MEGABYTE中得到了很好的解决。
-
无需标记化: MEGABYTE直接在字节级别上操作,避免了传统模型中复杂的标记化过程。这不仅简化了预处理,还为多模态建模和新领域迁移提供了便利。
-
优异的可扩展性: 通过创新的架构设计,MEGABYTE能够有效地处理百万字节级别的长序列,大大扩展了模型的应用范围。
-
快速生成: MEGABYTE的并行生成能力显著提高了文本生成的速度,这对于需要实时响应的应用(如聊天机器人)尤为重要。
-
多模态潜力: MEGABYTE的字节级建模为处理多种数据类型(如图像、音频、代码等)提供了统一的框架,为未来的多模态AI系统奠定了基础。
MEGABYTE与其他AI技术的协同
MEGABYTE的创新不是孤立的,它与Meta AI最近发布的其他开源AI工具形成了良好的协同效应:
-
Segment Anything Model 2 (SAM 2): SAM 2在单一模型中实现了视频和图像的分割和跟踪。MEGABYTE的长序列处理能力可能为SAM 2处理更长的视频序列提供支持。
-
DINOv2: 作为一种先进的自监督学习技术,DINOv2能够从未标记的图像中学习视觉表示。MEGABYTE的多尺度架构可能为DINOv2提供新的建模思路。
-
ImageBIND: ImageBIND引入了跨六种不同模态的联合嵌入空间学习方法。MEGABYTE的字节级建模能力可能为ImageBIND处理更多样化的数据类型提供支持。
这些技术的结合,展现了Meta AI在推动AI研究和开发方面的全面实力,为未来的AI系统开辟了新的可能性。
结语
MEGABYTE-pytorch的出现标志着长序列建模领域的一个重要里程碑。它不仅解决了传统Transformer模型在处理超长序列时面临的挑战,还为未来的AI系统提供了新的架构范式。随着MEGABYTE及其PyTorch实现的不断发展和完善,我们有理由期待它在自然语言处理、多模态AI、大规模内容生成等领域带来更多突破性的应用。
作为开源项目,MEGABYTE-pytorch为研究人员和开发者提供了一个宝贵的工具,用于探索和推进长序列建模技术。我们鼓励感兴趣的读者深入研究MEGABYTE-pytorch的源代码,参与到这个充满潜力的项目中来,共同推动AI技术的进步。
参考资源
让我们期待MEGABYTE在未来为AI领域带来更多令人兴奋的突破和创新! 🚀🔬🧠









