
SAM 2简介
Meta AI最近发布了Segment Anything Model 2 (SAM 2),这是一个突破性的人工智能模型,旨在解决图像和视频中的可提示视觉分割问题。作为原始SAM模型的successor,SAM 2在多个方面都有显著改进,尤其是将视频分割能力整合到了一个统一的模型中。
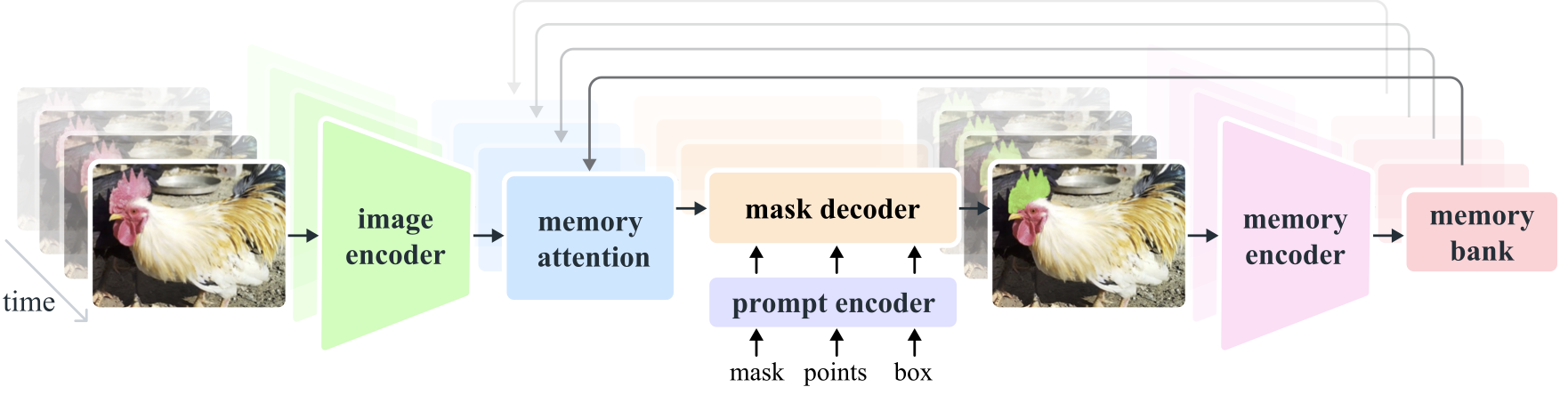
SAM 2的核心思想是将图像视为单帧视频,从而将图像分割的能力无缝扩展到视频领域。该模型采用了简洁而强大的Transformer架构,并结合了流式内存机制,实现了实时的视频处理能力。
主要特性和优势
SAM 2相比原始SAM模型有以下几个显著的改进:
-
统一的图像和视频分割能力:SAM 2是首个能够同时处理图像和视频分割任务的统一模型。
-
实时视频处理:通过优化的架构设计,SAM 2能够以约44帧/秒的速度实时处理视频,使其适用于各种实时应用场景。
-
改进的交互性:SAM 2支持更高级的提示技术,包括使用掩码作为输入提示,提高了模型处理复杂场景的能力。
-
增强的记忆机制:SAM 2引入了基于会话的记忆模块,能够在视频帧之间跟踪目标对象,即使对象暂时消失也能保持连贯性。
-
灵活的提示和修正:用户可以在任何视频帧上添加提示或进行修正,模型会实时更新分割结果。
SA-V数据集
为了训练SAM 2,研究团队构建了迄今为止规模最大的视频分割数据集SA-V。该数据集包含:
- 超过600,000个masklet注释
- 跨越51,000个视频
- 来自47个国家的地理多样性场景
- 包括完整对象、部件和具有挑战性的遮挡情况

这个庞大而多样化的数据集使SAM 2能够在各种复杂场景中表现出色,具有很强的泛化能力。
性能和对比
SAM 2在多个基准测试中展现出卓越的性能:
- 在图像分割任务上,SAM 2相比原始SAM模型准确度更高,速度提升了6倍。
- 在视频对象分割任务上,SAM 2的表现优于现有的专门视频分割模型,特别是在跟踪物体部件方面。
- 在交互式视频分割任务中,SAM 2所需的交互时间比现有方法少。
以下是不同规模SAM 2模型的性能对比:
| 模型 | 参数量 (M) | 速度 (FPS) | SA-V测试 (J&F) | MOSE验证 (J&F) | LVOS v2 (J&F) |
|---|---|---|---|---|---|
| sam2_hiera_tiny | 38.9 | 47.2 | 75.0 | 70.9 | 75.3 |
| sam2_hiera_small | 46 | 43.3 (53.0*) | 74.9 | 71.5 | 76.4 |
| sam2_hiera_base_plus | 80.8 | 34.8 (43.8*) | 74.7 | 72.8 | 75.8 |
| sam2_hiera_large | 224.4 | 24.2 (30.2*) | 76.0 | 74.6 | 79.8 |
*使用编译优化后的速度
应用场景
SAM 2的强大功能为多个领域带来了新的可能性:
-
创意产业:简化了图像和视频编辑中的对象选择、背景替换和高级合成等任务。
-
科学研究:在医学成像中精确识别和分离不同身体部位,或在环境研究中分析卫星图像。
-
自动驾驶:提高自动驾驶车辆感知系统的准确性,更好地识别和追踪行人、车辆和障碍物。
-
增强现实:通过实时精确跟踪对象,创造更加沉浸式的AR体验。
-
AI模型训练:自动化大规模数据集的分割过程,提高训练数据的质量和效率。
开始使用SAM 2
要开始使用SAM 2,您需要按照以下步骤操作:
-
安装依赖:
git clone https://github.com/facebookresearch/segment-anything-2.git cd segment-anything-2 pip install -e . -
下载模型权重:
cd checkpoints ./download_ckpts.sh cd .. -
使用示例代码进行图像或视频分割:
图像分割:
import torch from sam2.build_sam import build_sam2 from sam2.sam2_image_predictor import SAM2ImagePredictor checkpoint = "./checkpoints/sam2_hiera_large.pt" model_cfg = "sam2_hiera_l.yaml" predictor = SAM2ImagePredictor(build_sam2(model_cfg, checkpoint)) with torch.inference_mode(), torch.autocast("cuda", dtype=torch.bfloat16): predictor.set_image(<your_image>) masks, _, _ = predictor.predict(<input_prompts>)视频分割:
import torch from sam2.build_sam import build_sam2_video_predictor checkpoint = "./checkpoints/sam2_hiera_large.pt" model_cfg = "sam2_hiera_l.yaml" predictor = build_sam2_video_predictor(model_cfg, checkpoint) with torch.inference_mode(), torch.autocast("cuda", dtype=torch.bfloat16): state = predictor.init_state(<your_video>) frame_idx, object_ids, masks = predictor.add_new_points_or_box(state, <your_prompts>) for frame_idx, object_ids, masks in predictor.propagate_in_video(state): # 处理每一帧的分割结果
更多详细示例和用法,请参考官方GitHub仓库中的Jupyter Notebook示例。
结论与展望
SAM 2代表了计算机视觉领域的重要进展,它将图像和视频分割任务统一到一个高效的模型中,为众多应用场景提供了新的可能性。随着研究人员和开发者开始探索SAM 2的潜力,我们可以期待看到更多创新性的应用出现。
然而,SAM 2也面临一些挑战和局限性。例如,在处理大幅度视角变化、长时间遮挡或复杂场景时可能需要额外的人工干预。此外,同时分割多个对象的效率还有提升空间。
未来的研究方向可能包括:
- 进一步提高模型在复杂场景下的鲁棒性
- 优化多对象同时分割的性能
- 探索与其他AI技术(如生成式AI)的结合
- 开发更多针对特定领域的应用和优化
总的来说,SAM 2为计算机视觉领域带来了令人兴奋的新可能性,它的开源性质也将推动整个AI社区的创新和进步。随着技术的不断发展,我们可以期待看到更多基于SAM 2的突破性应用出现在各个领域。











