
MFTCoder: 推动代码大语言模型性能的多任务微调利器
在人工智能和大语言模型快速发展的今天,代码智能生成和理解已经成为一个重要的研究方向。为了进一步提升代码大语言模型的性能,蚂蚁集团AI Native团队开发了MFTCoder多任务微调框架,并将其开源,为整个AI社区带来了宝贵的技术贡献。
MFTCoder的核心优势
MFTcoder作为一个专注于代码大语言模型的多任务微调框架,具有以下几个突出特点:
-
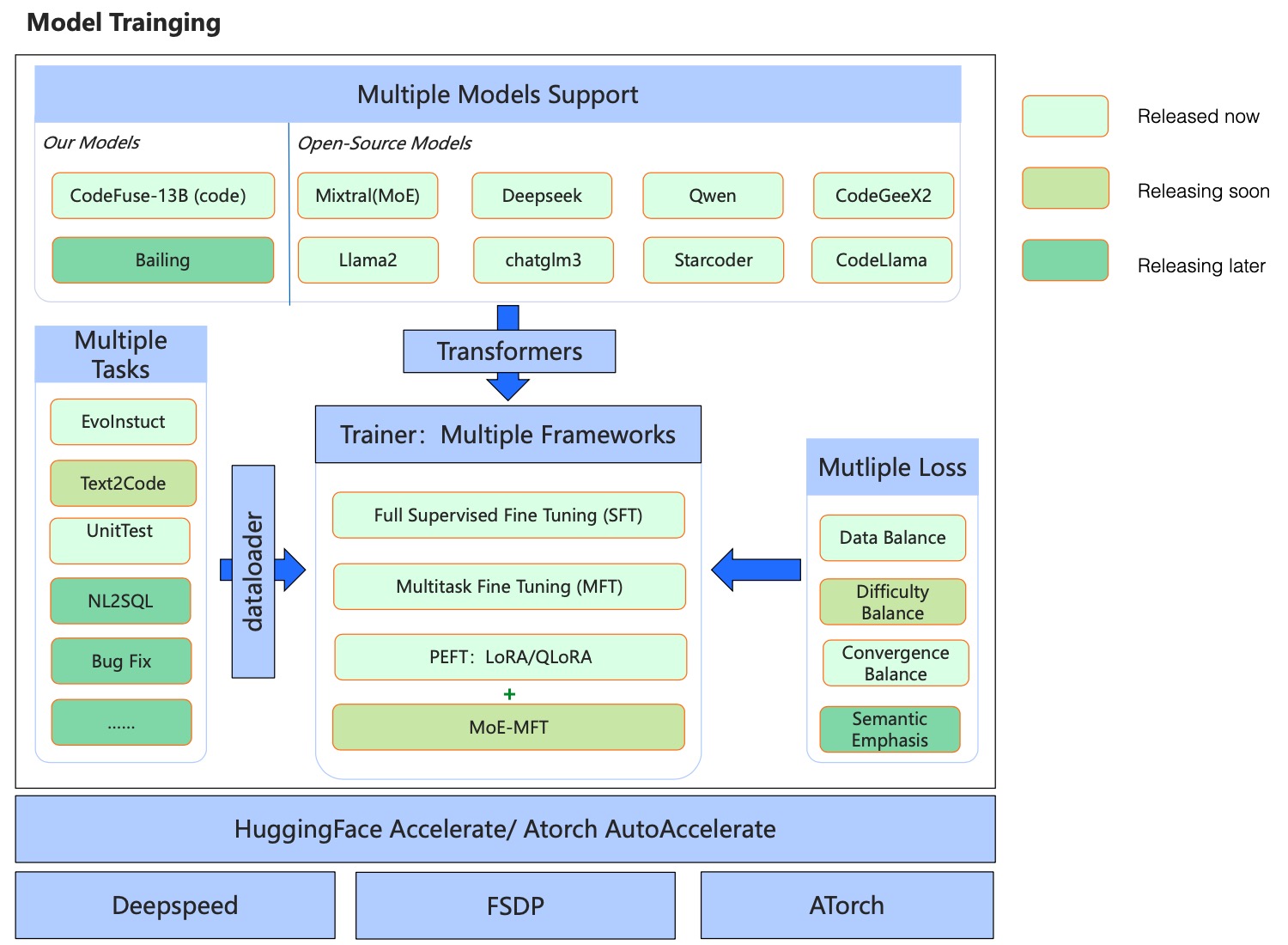
多任务学习: MFTCoder支持在多个任务上同时进行微调,有效平衡不同任务间的学习,甚至可以泛化到全新的未见任务。这种方法充分利用了不同编程任务之间的内在联系,提高了模型的通用性和鲁棒性。
-
多模型支持: 该框架集成了多个主流的开源大语言模型,如CodeLlama、Qwen、StarCoder等。这种广泛的兼容性使得研究人员可以方便地在不同模型上进行实验和比较。
-
高效微调: MFTCoder支持LoRA、QLoRA等高效参数微调技术,以及全参数微调。这使得即使在有限的计算资源下,也能对大型模型进行有效的微调。
-
多框架支持: 框架同时支持Accelerate(配合DeepSpeed和FSDP)以及ATorch,为用户提供了灵活的训练选择。
突破性的性能表现
通过MFTCoder的微调,研究团队在多个基准测试上取得了令人瞩目的成绩。以HumanEval为例,多个基于MFTCoder微调的模型展现出色的表现:
- CodeFuse-DeepSeek-33B: 在HumanEval上达到78.7%的pass@1分数(2024年1月)
- CodeFuse-CodeLlama-34B: 达到74.4%的pass@1分数(2023年9月)
- CodeFuse-StarCoder2-15B: 达到73.2%的pass@1分数(2023年5月)
这些成绩不仅超越了许多同规模的模型,甚至在某些指标上超过了GPT-4等更大规模的模型。
开源共享,推动技术进步
MFTCoder项目的一个重要特点是其开源性质。研究团队不仅开源了框架本身,还发布了多个经过微调的代码大语言模型,以及高质量的代码相关指令数据集。这种开放共享的态度,极大地促进了整个AI社区在代码智能领域的研究和应用。
开源的模型包括:
- CodeFuse-DeepSeek-33B
- CodeFuse-Mixtral-8x7B
- CodeFuse-CodeLlama-34B
- CodeFuse-StarCoder-15B
- CodeFuse-QWen-14B等
开源的数据集包括:
- Evol-instruction-66k: 一个高质量的代码指令数据集
- CodeExercise-Python-27k: Python代码练习指令数据集
这些资源的开放极大地降低了其他研究者和开发者进入这一领域的门槛,推动了整个社区的技术进步。
持续发展与未来展望
MFTCoder项目正在持续快速发展中。最新版本(v0.4)引入了QLoRA + DeepSpeed Zero3和QLoRA + FSDP等新特性,支持了更多新模型如Qwen2、Qwen2-MoE、Starcoder2、Gemma等。这些更新进一步提升了框架的性能和灵活性。
同时,项目团队也在积极探索新的研究方向,如解决多任务学习中的数据不平衡、任务难度差异和收敛速度不一致等问题。这些努力将进一步推动代码大语言模型的性能边界。
结语
MFTCoder的出现和持续发展,为代码大语言模型的研究和应用带来了新的可能。通过多任务微调,我们看到了模型性能的显著提升。这不仅有助于提高软件开发的效率,还可能在代码理解、程序修复等多个方面产生深远影响。
随着更多研究者和开发者参与到这个开源项目中来,我们可以期待看到更多创新性的应用和突破。MFTCoder正在成为推动代码智能化的重要力量,为AI赋能软件开发开辟了广阔的前景。









