
中文Mixtral大模型:开启中文大规模语言模型新篇章
近年来,大规模语言模型(Large Language Models, LLMs)在自然语言处理领域取得了突破性进展,展现出强大的语言理解和生成能力。然而,大多数主流LLMs主要针对英语进行训练,在中文等其他语言上的表现相对较弱。为了推动中文大模型的发展,研究人员基于Mistral AI公司发布的Mixtral-8x7B模型,开发了专门针对中文优化的Chinese-Mixtral系列模型,为中文自然语言处理带来了新的可能性。
Mixtral模型架构简介
Mixtral模型采用了稀疏混合专家(Sparse Mixture of Experts, MoE)架构,这是一种新颖的神经网络设计。与传统的Transformer架构不同,MoE模型在每个前馈网络(FFN)层包含多个"专家"子网络。在推理过程中,模型会根据输入动态选择最相关的专家子网络进行计算,从而在保持较小计算量的同时,实现更大的模型容量。
具体来说,Mixtral-8x7B模型包含8个专家子网络,但在处理每个token时只会激活其中2个。这种设计使得模型的总参数量达到46.7B,但实际激活的参数量仅为13B左右。这种架构不仅提高了模型的效率,还增强了其处理不同类型任务的能力。
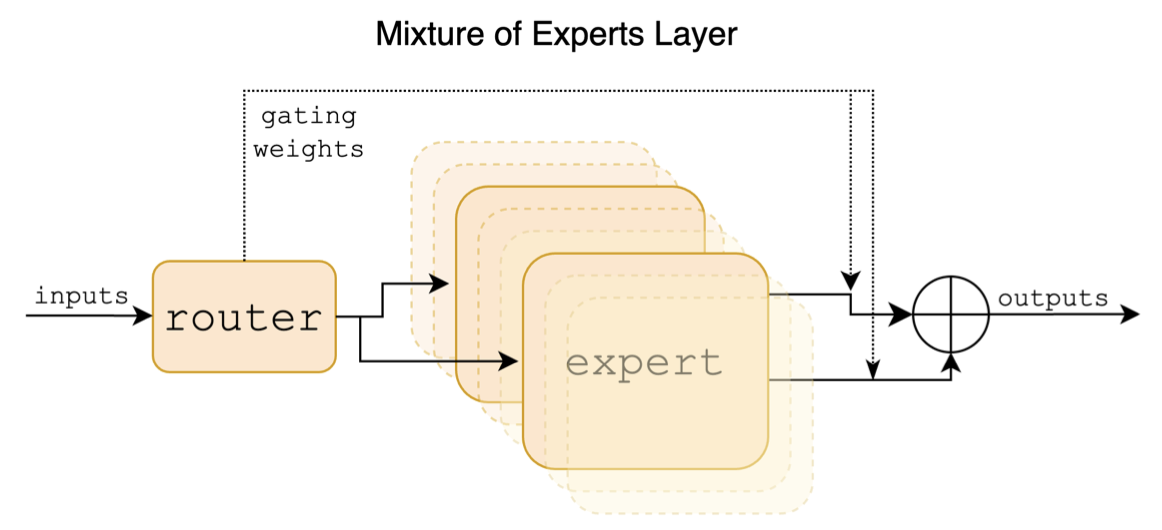
Chinese-Mixtral模型系列
基于Mixtral-8x7B模型,研究人员开发了两个主要的中文模型:
-
Chinese-Mixtral: 这是一个基础模型,通过在原始Mixtral模型上进行增量预训练得到。预训练使用了约20GB的中文无标注文本数据,显著提升了模型的中文理解和生成能力。
-
Chinese-Mixtral-Instruct: 这是一个指令微调模型,在Chinese-Mixtral的基础上,使用高质量的中文指令数据进行了进一步的微调。该模型更适合于对话、问答等需要遵循特定指令的任务。
这两个模型都保留了原始Mixtral模型的核心优势,包括支持32K tokens的上下文窗口(实测可达128K),以及在数学推理、代码生成等方面的出色表现。
模型下载与使用
为了方便不同需求的用户,Chinese-Mixtral模型提供了多种下载选项:
- 完整版模型: 直接下载即可使用,适合网络条件较好的用户。
- LoRA版模型: 需要与原版Mixtral-8x7B-v0.1合并使用,适合已有原版模型的用户。
- GGUF版模型: 兼容llama.cpp等工具的量化版本,适合部署推理的用户。
模型可以从多个平台下载,包括百度网盘、Hugging Face和ModelScope等。用户可以根据自己的需求选择合适的版本和下载渠道。
模型部署与推理
Chinese-Mixtral模型支持多种部署和推理方式,以适应不同的应用场景:
- llama.cpp: 提供丰富的量化选项和高效的本地推理能力。
- Hugging Face Transformers: 使用原生的Transformers库进行推理。
- 仿OpenAI API调用: 提供类似OpenAI API的接口,方便集成到现有系统。
- text-generation-webui: 提供图形用户界面,便于非技术用户使用。
- LangChain: 适合进行二次开发的大模型应用框架。
- privateGPT: 支持多文档本地问答的框架。
- LM Studio: 提供多平台支持的图形界面聊天软件。
这些多样化的部署选项使得Chinese-Mixtral模型能够满足从个人用户到企业级应用的各种需求。
模型效果评测
为了全面评估Chinese-Mixtral模型的性能,研究人员进行了一系列客观评测:
-
C-Eval: 在这个综合性中文评测集上,Chinese-Mixtral-Instruct模型在5-shot设置下达到了51.5%的准确率,显著优于Chinese-Alpaca-2-13B等模型。
-
CMMLU: 在这个专门针对中文知识和推理能力的测试集上,Chinese-Mixtral-Instruct在5-shot设置下取得了53.0%的准确率,同样优于其他中文大模型。
-
MMLU: 在这个主流的英文评测集上,Chinese-Mixtral-Instruct展现出了强大的跨语言能力,在5-shot设置下达到了69.8%的准确率,与原版Mixtral模型相当。
-
LongBench: 在这个长文本理解能力评测基准上,Chinese-Mixtral-Instruct在多个子任务中表现出色,特别是在代码补全和合成任务方面。
这些评测结果表明,Chinese-Mixtral模型不仅在中文任务上表现优异,还保持了原始Mixtral模型在英文和专业领域任务上的强大能力。
量化效果评估
为了满足在资源受限环境下的部署需求,研究人员对Chinese-Mixtral模型进行了多种精度的量化,并评估了其性能:
- 从F16(87GB)到IQ2_XXS(11.4GB),提供了多个量化版本,满足不同的存储和计算需求。
- 在困惑度(PPL)指标上,Q4_0及以上精度的量化版本与原始F16版本相差不大,保持了较好的语言建模能力。
- 在Apple M3 Max和NVIDIA A100上进行了推理速度测试,为用户选择合适的量化版本提供了参考。
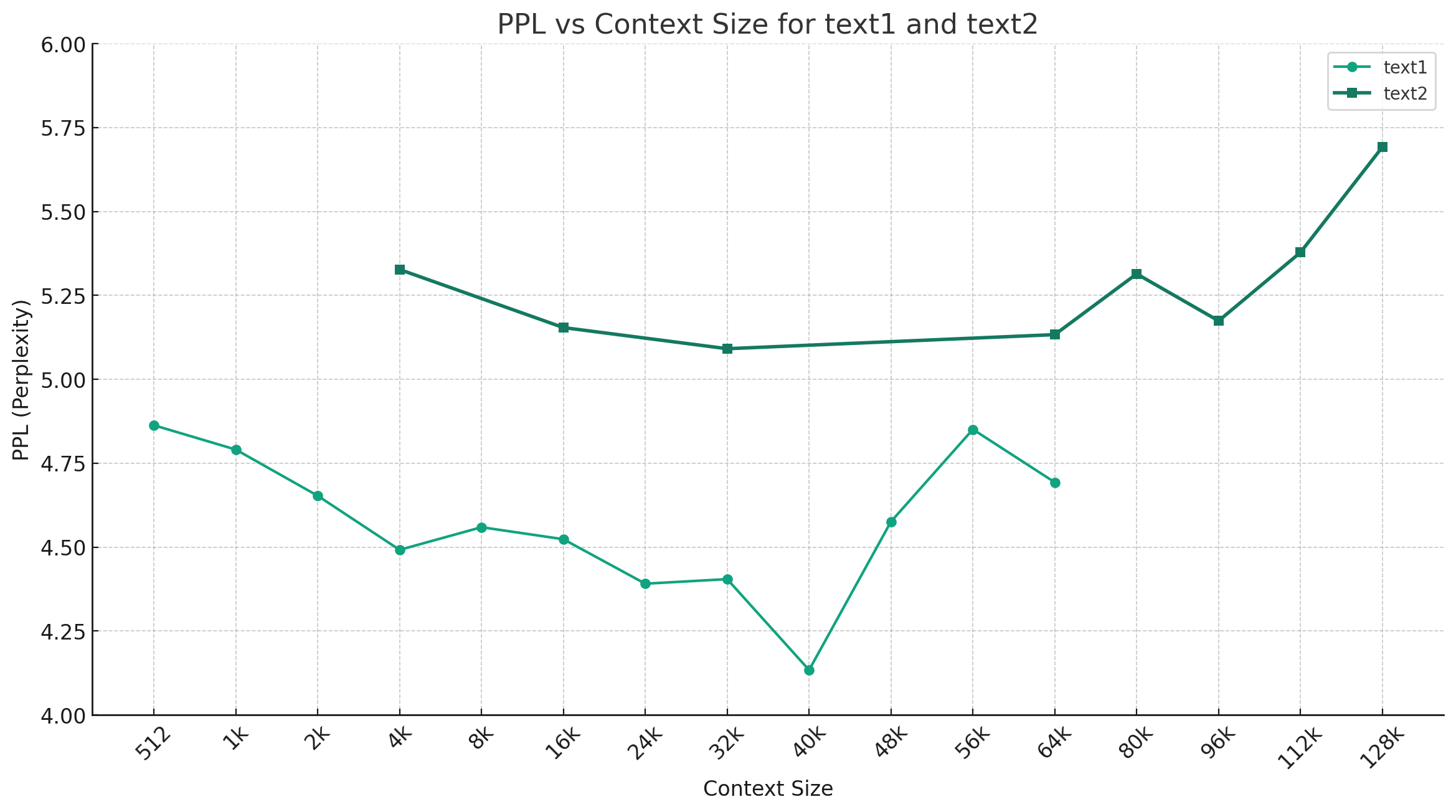
特别值得一提的是,研究人员发现Chinese-Mixtral模型在长文本处理方面表现出色。实验表明,该模型在64K甚至128K tokens的上下文长度下仍能保持较低的困惑度,这大大扩展了模型的应用场景。
模型训练与微调
Chinese-Mixtral模型的训练过程主要包括两个阶段:
-
预训练阶段: 使用约20GB的中文无标注文本数据,在原始Mixtral-8x7B模型基础上进行增量训练,得到Chinese-Mixtral基座模型。
-
指令微调阶段: 使用高质量的中文指令数据,对Chinese-Mixtral基座模型进行微调,得到Chinese-Mixtral-Instruct模型。
研究人员采用了QLoRA(Quantized Low-Rank Adaptation)技术进行训练,这种方法可以在有限的计算资源下实现高效的模型适应。同时,项目还开源了训练和微调的相关代码,方便其他研究者进行复现和进一步优化。
结语
Chinese-Mixtral项目为中文自然语言处理领域带来了一个强大而灵活的大规模语言模型。通过结合Mixtral的创新架构和针对中文的优化训练,该模型在多个评测基准上展现出卓越的性能。其支持长文本处理、多种部署方式和量化选项的特性,使其能够适应从学术研究到工业应用的广泛场景。
随着模型的开源和相关资源的公开,我们可以期待看到更多基于Chinese-Mixtral的创新应用和研究成果。这不仅将推动中文自然语言处理技术的进步,也将为人工智能在中文语境下的应用开辟新的可能性。
未来,研究团队计划进一步优化模型性能,探索更多的应用场景,并与社区合作推动中文大模型生态的发展。Chinese-Mixtral的出现,无疑为中文自然语言处理领域注入了新的活力,开启了一个充满机遇和挑战的新篇章。










