
MLX-LLM:在苹果芯片上释放AI潜力
随着人工智能技术的快速发展,大型语言模型(LLMs)已成为自然语言处理领域的核心驱动力。然而,这些模型通常需要强大的计算资源才能高效运行。为了解决这一挑战,MLX-LLM应运而生 - 这是一个基于苹果MLX框架的开源项目,旨在让开发者能够在苹果芯片上实时运行和部署大型语言模型。
MLX-LLM的诞生与优势
MLX-LLM由Riccardo Musmeci开发,是一个建立在苹果MLX框架基础上的项目。MLX是苹果公司推出的机器学习框架,专为苹果芯片优化。MLX-LLM充分利用了MLX的优势,使得大型语言模型能够在苹果silicon芯片上高效运行。
与传统的深度学习框架(如PyTorch和TensorFlow)相比,MLX-LLM具有以下优势:
- 针对苹果芯片优化:充分利用苹果M系列芯片的性能潜力。
- 内存效率高:采用统一内存架构,减少CPU和GPU之间的数据传输开销。
- 实时性能:能够在消费级设备上实现大型语言模型的实时推理。
支持的模型家族
MLX-LLM目前支持多个主流的大型语言模型家族,包括:
- LLaMA 2
- LLaMA 3
- Phi3
- Mistral
- TinyLLaMA
- Gemma
- OpenELM
这些模型涵盖了从轻量级到大规模的不同规格,能够满足各种应用场景的需求。例如,开发者可以选择LLaMA 3 8B模型用于复杂的自然语言理解任务,也可以使用TinyLLaMA等小型模型在资源受限的环境中部署。
核心功能与应用
1. 模型加载与量化
MLX-LLM提供了简单的API来加载预训练模型。开发者可以轻松地从HuggingFace加载模型权重:
from mlx_llm.model import create_model
# 从HuggingFace加载权重
model = create_model("llama_3_8b_instruct")
此外,MLX-LLM还支持模型量化,这可以显著减少模型的内存占用和推理时间,同时保持性能:
from mlx_llm.model import create_model, quantize, get_weights
from mlx_llm.utils.weights import save_weights
# 创建并量化模型
model = create_model("llama_3_8b_instruct")
model = quantize(model, group_size=64, bits=4)
# 保存量化后的模型权重
weights = get_weights(model)
save_weights(weights, "llama_3_8b_instruct-4bit.safetensors")
2. 文本嵌入生成
MLX-LLM允许开发者从给定文本中提取嵌入向量,这对于各种下游任务(如文本分类、相似度计算等)非常有用:
import mlx.core as mx
from mlx_llm.model import create_model, create_tokenizer
model = create_model("llama_3_8b_instruct")
tokenizer = create_tokenizer('llama_3_8b_instruct')
text = ["I like to play basketball", "I like to play tennis"]
tokens = tokenizer(text)
x = mx.array(tokens["input_ids"])
embeds, _ = model.embed(x, norm=True)
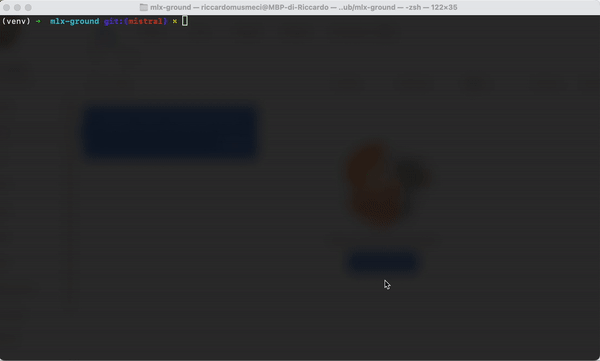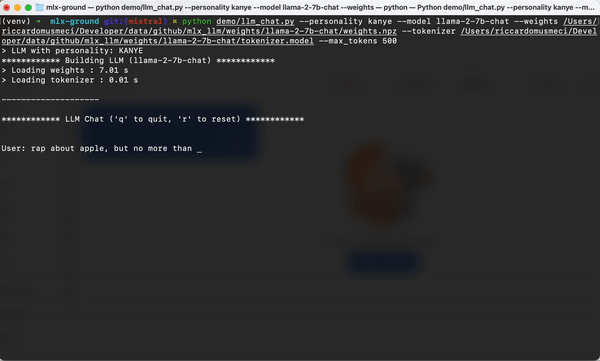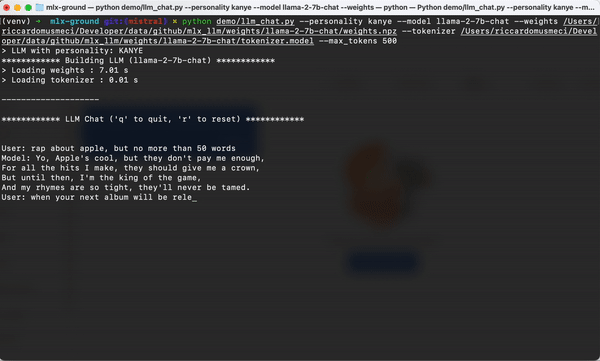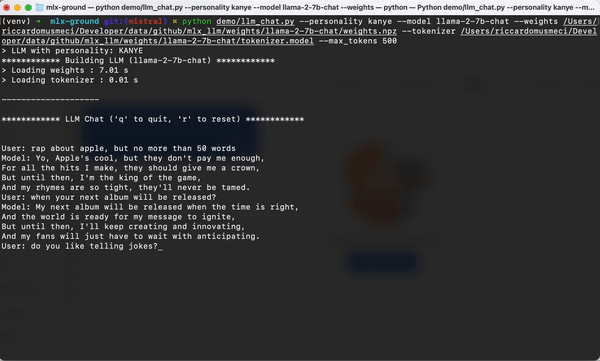
3. 交互式聊天接口
MLX-LLM提供了简单易用的聊天接口,使得开发者可以轻松地创建基于大型语言模型的对话系统:
from mlx_llm.chat import ChatSetup, LLMChat
model_name = "tiny_llama_1.1B_chat_v1.0"
chat = LLMChat(
model_name=model_name,
prompt_family="tinyllama",
chat_setup=ChatSetup(
system="You are Michael Scott from The Office. Your goal is to answer like him, so be funny and inappropriate, but be brief.",
history=[
{"question": "What is your name?", "answer": "Michael Scott"},
{"question": "What is your favorite episode of The Office?", "answer": "The Dinner Party"},
],
),
quantized=False, # 可以使用量化参数提高速度
)
chat.start()
这个聊天接口允许设置系统提示和历史对话,从而控制模型的行为和语气。
性能与效率
MLX-LLM在苹果芯片上展现出了令人印象深刻的性能。根据开发者Heiko Hotz的测试,在配备16GB内存的MacBook Pro (M1芯片)上,MLX-LLM能够实现实时的模型推理。这意味着即使是像Mistral-7B这样的大型模型,也能在普通的苹果笔记本电脑上流畅运行。
这种优异的性能主要得益于MLX框架的统一内存架构。与传统框架不同,MLX-LLM不需要在CPU和GPU之间频繁复制数据,从而大大减少了内存开销和延迟。
未来展望
MLX-LLM项目仍在积极开发中,未来计划添加更多功能,包括:
- LoRA和QLoRA微调支持:这将使模型能够更好地适应特定领域或任务。
- 检索增强生成(RAG):通过结合外部知识库,提高模型的问答能力。
这些计划中的功能将进一步扩展MLX-LLM的应用范围,使其成为更加全面和强大的工具。
结语
MLX-LLM为在苹果设备上部署和运行大型语言模型开辟了新的可能性。它不仅使得开发者能够在本地设备上进行AI实验和原型设计,还为构建隐私保护的AI应用提供了基础。随着项目的不断发展和完善,我们可以期待看到更多基于MLX-LLM的创新应用在苹果生态系统中涌现。
无论您是AI研究人员、应用开发者,还是对大型语言模型感兴趣的技术爱好者,MLX-LLM都为您提供了一个强大而灵活的工具,让您能够在苹果设备上释放AI的无限潜力。🚀🍎
欢迎访问MLX-LLM的GitHub页面了解更多详情,并关注项目的最新进展。如果您对项目有任何问题或建议,也可以直接联系项目作者Riccardo Musmeci。让我们一起探索MLX-LLM带来的AI新世界!










