
MoCo:开创自监督视觉表示学习新纪元
在计算机视觉领域,如何从大量未标注数据中学习到高质量的视觉表示一直是一个重要而富有挑战性的问题。近年来,自监督学习方法在这一领域取得了巨大进展,而Facebook AI Research团队提出的MoCo(Momentum Contrast)无疑是其中的佼佼者。MoCo通过巧妙的对比学习设计和动量编码器的创新,在多个下游任务中取得了突破性成果,成为了自监督视觉表示学习的重要里程碑。
MoCo的核心思想
MoCo的核心思想是通过对比学习来学习视觉表示。具体来说,它将同一图像的不同视图(如不同的数据增强结果)视为正样本对,将不同图像视为负样本对。模型的目标是将正样本对的特征表示拉近,同时将负样本对的特征表示推远。
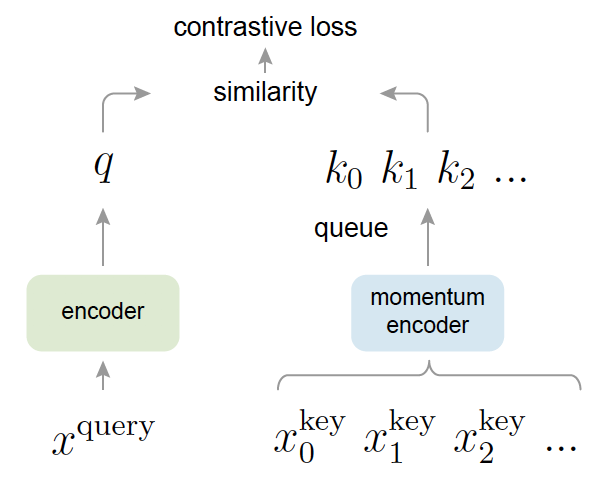
MoCo的创新之处主要体现在以下几个方面:
-
动量编码器:MoCo引入了一个动量编码器,它是主编码器的缓慢移动平均。这种设计使得模型可以维护一个大而一致的字典,从而提高对比学习的效果。
-
队列机制:MoCo使用一个队列来存储负样本的特征表示,而不是像之前的方法那样只使用当前mini-batch内的样本。这大大增加了负样本的数量和多样性,有助于学习更好的表示。
-
动量更新:MoCo采用动量更新的方式来更新key encoder的参数,这使得key encoder的参数变化更加平滑,有助于保持字典的一致性。
MoCo的实现与优化
MoCo的PyTorch实现非常简洁高效。以下是其核心代码片段:
# momentum update of key encoder
self._momentum_update_key_encoder()
# compute query features
q = self.encoder_q(im_q) # queries: NxC
q = nn.functional.normalize(q, dim=1)
# compute key features
with torch.no_grad(): # no gradient to keys
k = self.encoder_k(im_k) # keys: NxC
k = nn.functional.normalize(k, dim=1)
# compute logits
l_pos = torch.einsum('nc,nc->n', [q, k]).unsqueeze(-1)
l_neg = torch.einsum('nc,ck->nk', [q, self.queue.clone().detach()])
# contrastive loss
logits = torch.cat([l_pos, l_neg], dim=1)
labels = torch.zeros(logits.shape[0], dtype=torch.long).cuda()
loss = nn.CrossEntropyLoss().cuda()(logits / self.T, labels)
在MoCo v2中,研究人员进一步对MoCo进行了优化:
-
引入MLP投影头:在编码器输出后添加一个多层感知机(MLP)投影头,这有助于提高表示的质量。
-
余弦学习率调度:采用余弦学习率调度策略,使学习率随训练进程平滑衰减。
-
更强的数据增强:引入更强的数据增强策略,如随机裁剪、颜色抖动等,增加正样本对的难度。
这些优化使得MoCo v2在多个下游任务上的表现进一步提升。
MoCo的惊人成果
MoCo在多个计算机视觉任务上取得了令人瞩目的成果:
-
ImageNet线性分类:在200轮预训练后,MoCo v2达到了67.5%的top-1准确率,远超同期的其他自监督方法。
-
目标检测:在COCO数据集上,MoCo预训练的模型在目标检测任务上的性能超过了从头训练的模型,甚至接近了使用ImageNet监督预训练的模型。
-
语义分割:在PASCAL VOC数据集上,MoCo预训练的模型在语义分割任务上也取得了优异的成绩。
-
实例分割:在COCO数据集的实例分割任务上,MoCo同样表现出色。
这些结果表明,MoCo学习到的视觉表示具有很强的通用性和迁移能力,可以有效地应用于各种下游任务。
MoCo的影响与展望
MoCo的成功不仅在于其出色的性能,更在于它为自监督视觉表示学习开辟了一个新的方向。它证明了通过精心设计的对比学习方法,可以学习到与监督学习相媲美甚至更好的视觉表示。
MoCo的成功也激发了众多后续工作,如SimCLR、BYOL、SwAV等。这些方法在MoCo的基础上进行了进一步的创新和优化,推动了自监督学习领域的快速发展。
展望未来,MoCo及其衍生方法在以下方面仍有巨大潜力:
-
多模态学习:将MoCo的思想扩展到图像-文本、视频-音频等多模态学习场景。
-
大规模预训练:利用MoCo的高效性,在更大规模的数据集上进行预训练,可能会带来更惊人的结果。
-
领域迁移:探索MoCo在医疗影像、遥感图像等特定领域的应用潜力。
-
结合其他学习范式:将MoCo与半监督学习、元学习等其他学习范式相结合,可能会产生新的突破。
总的来说,MoCo作为自监督视觉表示学习的里程碑,不仅推动了技术的进步,也为人工智能向着更加通用和智能的方向发展提供了重要启示。它的成功表明,通过巧妙的算法设计,我们可以从海量的未标注数据中学习到强大而通用的表示,这无疑为AI的发展开辟了一条充满希望的道路。
参考资料
- MoCo: Momentum Contrast for Unsupervised Visual Representation Learning
- Improved Baselines with Momentum Contrastive Learning
- MoCo GitHub仓库
无论你是计算机视觉领域的研究者、工程师,还是对AI前沿技术感兴趣的学习者,深入了解MoCo都将为你打开一扇通向自监督学习精彩世界的大门。让我们一起期待MoCo及其衍生方法在未来带来的更多突破和创新!









