
Modin简介
Modin是一个旨在加速pandas数据处理工作流程的开源库。它的核心理念是通过更改一行导入代码,就能让现有的pandas代码获得多核并行计算的能力,从而大幅提升性能,同时保持与pandas API的完全兼容性。
# 将这一行
import pandas as pd
# 替换为
import modin.pandas as pd
仅仅通过这样简单的替换,就可以让你的pandas代码运行得更快,甚至可以处理超出内存大小的数据集。

Modin的主要特点
-
加速pandas工作流程: Modin可以充分利用多核CPU的计算能力,显著提升pandas操作的速度。即使在普通笔记本电脑上,也可以获得高达4倍的性能提升。
-
处理大规模数据: Modin支持处理超出内存大小的数据集,让你可以在单机上轻松处理数百GB的数据。
-
完全兼容pandas API: Modin设计为pandas的直接替代品,你可以继续使用熟悉的pandas API,无需学习新的接口。
-
易于使用: 只需更改一行导入代码,就可以立即开始使用Modin加速你的pandas工作流程。
-
支持多种计算引擎: Modin支持Ray、Dask和MPI等多种分布式计算引擎,可以根据需求选择最适合的引擎。
Modin的工作原理
Modin通过将数据和计算透明地分布到多个核心上来实现加速。它使用了一种轻量级的并行DataFrame实现,可以自动将操作分解为可并行执行的任务。这样,即使是传统上同步的操作(如read_csv)也能获得显著的速度提升。
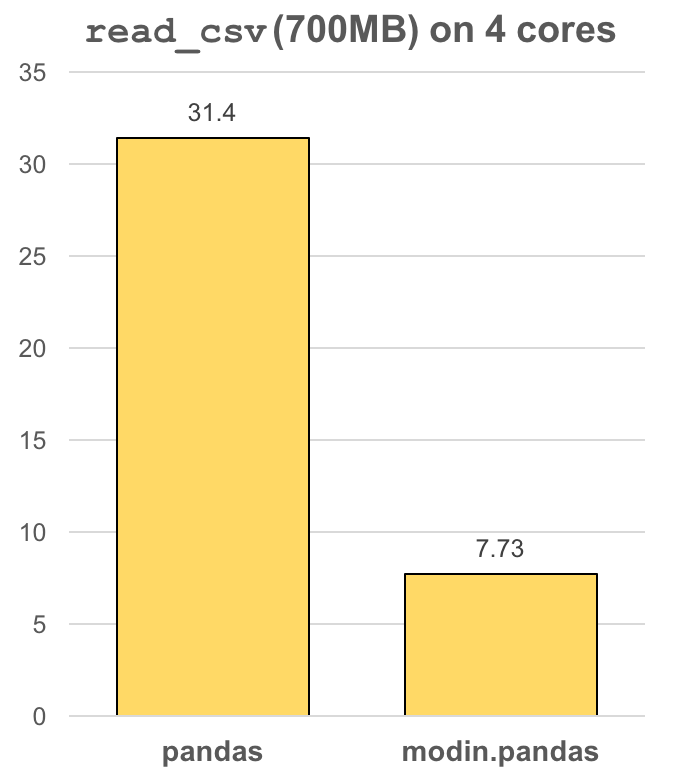
上图展示了Modin在读取CSV文件时相对于pandas的性能提升。可以看到,随着核心数的增加,Modin的性能优势愈发明显。
Modin的架构
Modin采用模块化的架构设计,允许灵活地插入不同的组件:

这种架构使得Modin可以适应不同的计算环境和需求,同时保持核心功能的稳定性。
使用Modin
安装
Modin可以通过pip轻松安装:
pip install "modin[all]" # 安装Modin及所有引擎
或者选择特定的引擎:
pip install "modin[ray]" # 使用Ray引擎
pip install "modin[dask]" # 使用Dask引擎
pip install "modin[mpi]" # 使用MPI引擎
基本用法
安装完成后,只需将pandas的导入语句替换为Modin的导入语句:
import modin.pandas as pd
# 之后的代码与使用pandas完全相同
df = pd.read_csv("large_dataset.csv")
result = df.groupby("column").mean()
选择计算引擎
Modin会自动检测并使用已安装的引擎。如果你想指定使用特定的引擎,可以通过环境变量设置:
export MODIN_ENGINE=ray # 使用Ray引擎
export MODIN_ENGINE=dask # 使用Dask引擎
export MODIN_ENGINE=unidist # 使用Unidist引擎
或者在代码中设置:
import modin.config as cfg
cfg.Engine.put("ray") # 使用Ray引擎
Modin的API覆盖率
Modin目前已经实现了pandas大部分常用的API,包括DataFrame和Series的操作,以及各种I/O函数。以下是Modin对pandas API的覆盖情况:
- DataFrame: 90.8%
- Series: 88.05%
- read_csv, read_table, read_parquet等: 100%
Modin团队正在持续增加对更多pandas API的支持。
Modin的优势
-
性能提升: 在多核系统上,Modin可以显著提升数据处理的速度,特别是对于大型数据集。
-
内存效率: Modin支持处理超出内存大小的数据集,让你可以在普通硬件上处理更大的数据。
-
无缝迁移: 由于与pandas API完全兼容,现有的pandas代码可以轻松迁移到Modin,无需大幅修改。
-
灵活性: Modin支持多种计算引擎,可以根据不同的需求和环境选择最适合的引擎。
-
持续发展: Modin是一个活跃的开源项目,有一个专门的团队持续改进和扩展其功能。
实际应用案例
让我们来看一个简单的例子,展示Modin如何在处理大型CSV文件时提供性能优势:
import time
import modin.pandas as pd
# 读取大型CSV文件
start_time = time.time()
df = pd.read_csv("large_dataset.csv")
end_time = time.time()
print(f"读取CSV文件耗时: {end_time - start_time} 秒")
# 进行数据处理
start_time = time.time()
result = df.groupby("category").agg({
"value": ["mean", "sum", "count"],
"timestamp": ["min", "max"]
})
end_time = time.time()
print(f"数据处理耗时: {end_time - start_time} 秒")
# 输出结果
print(result.head())
在这个例子中,Modin可能会比pandas快几倍,特别是在处理大型数据集时。
注意事项和限制
尽管Modin提供了许多优势,但在使用时也需要注意一些限制:
-
内存使用: 虽然Modin可以处理大型数据集,但在某些操作中可能会临时使用更多的内存。
-
API覆盖: 虽然Modin覆盖了大部分pandas API,但仍有一些不常用的函数可能尚未实现。
-
性能变化: 某些操作在Modin中可能比pandas慢,特别是对于小型数据集。
-
调试难度: 由于涉及并行计算,使用Modin的代码可能更难调试。
总结
Modin为数据科学家和分析师提供了一个强大的工具,使他们能够轻松地加速现有的pandas工作流程。通过简单地更改一行导入代码,就可以利用多核处理能力,显著提升性能,同时保持与pandas的兼容性。
随着数据规模的不断增长,Modin这样的工具将变得越来越重要,让数据处理更加高效和可扩展。无论你是在处理几百MB还是几百GB的数据,Modin都能帮助你更快地完成工作,让你专注于数据分析而不是性能优化。
如果你正在使用pandas处理大型数据集,或者希望提高数据处理的效率,不妨尝试一下Modin。它可能会成为你数据科学工具箱中的一个有力武器。









