
MonoHuman:开创单目视频人体建模新纪元
在虚拟现实和数字娱乐等领域,能够自由控制视角的虚拟人物动画一直是一个备受关注的研究方向。近年来,随着神经辐射场(NeRF)技术的发展,从单目视频重建人体三维模型变得可能。然而,如何在保证动作连贯性的同时实现对任意新姿势的高质量渲染,仍然是一个巨大的挑战。近日,来自香港中文大学和商汤科技的研究团队提出了一种名为MonoHuman的新型框架,在这一领域取得了重大突破。
MonoHuman的核心思想
MonoHuman的核心思想是通过双向约束来建模变形场,并充分利用关键帧信息来推理特征相关性,从而实现连贯一致的渲染结果。具体来说,MonoHuman包含两个关键模块:
-
共享双向变形模块(Shared Bidirectional Deformation Module): 该模块通过将前向和后向变形对应关系解耦为共享的骨骼运动权重和独立的非刚性运动,创建了一个与姿势无关的可泛化变形场。这使得MonoHuman能够更好地适应未见过的新姿势。
-
前向对应搜索模块(Forward Correspondence Search Module): 该模块查询关键帧的对应特征来指导渲染网络。这确保了渲染结果在多视角下保持一致性,即使在具有挑战性的新姿势设置下也能保持高保真度。
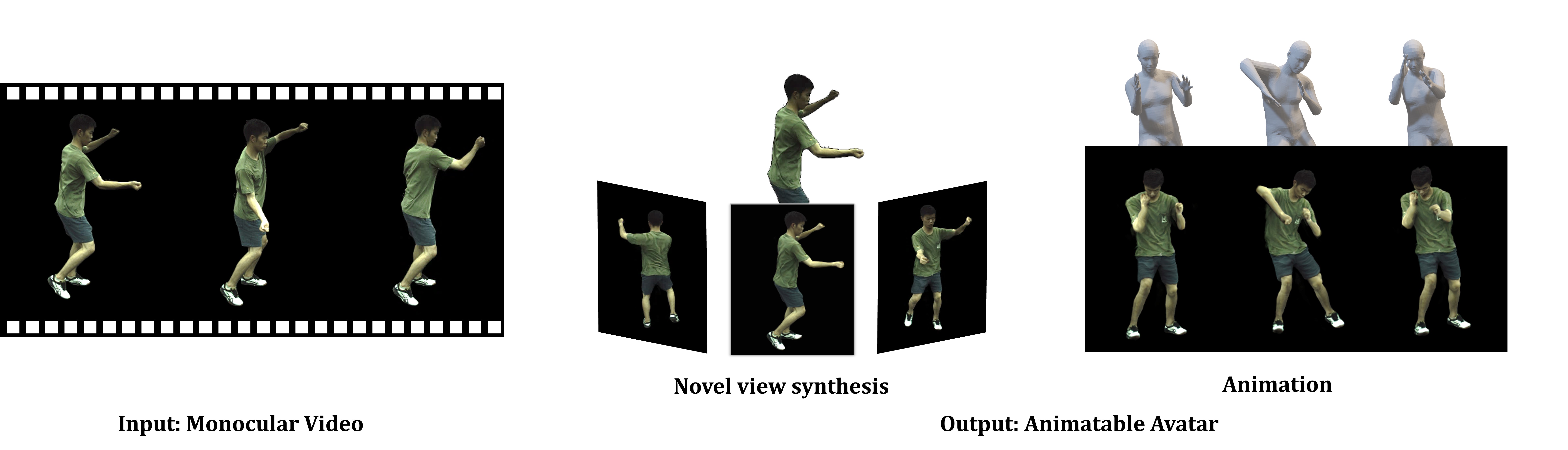
MonoHuman的技术优势
与现有方法相比,MonoHuman具有以下显著优势:
-
pose无关的表示: 通过共享双向变形模块,MonoHuman实现了与姿势无关的表示,大大提高了对新姿势的泛化能力。
-
动作连贯性: 通过前向对应搜索模块,MonoHuman能够有效利用关键帧信息,确保渲染结果在时序上保持连贯。
-
高保真度渲染: MonoHuman能够在各种具有挑战性的新姿势下保持高保真度的渲染效果。
-
多视角一致性: 渲染结果在不同视角下保持一致,这对于自由视角控制至关重要。
MonoHuman的应用示例
MonoHuman在多个应用场景中展现出了强大的性能:
-
动作序列渲染: MonoHuman能够流畅地渲染完整的动作序列,保持高质量的视觉效果。
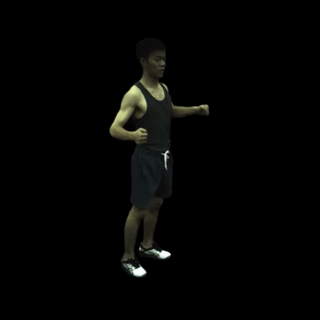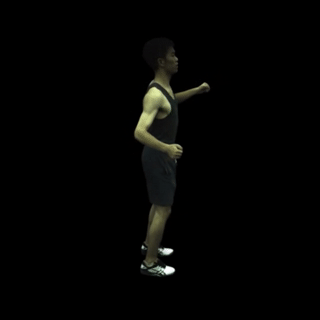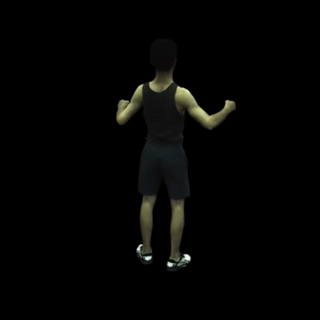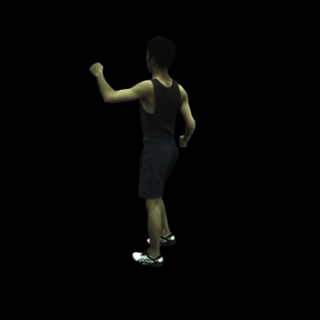
-
自由视角渲染: 对于特定帧,MonoHuman可以实现自由视角的渲染,为用户提供沉浸式的观看体验。
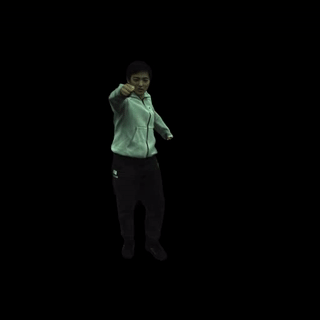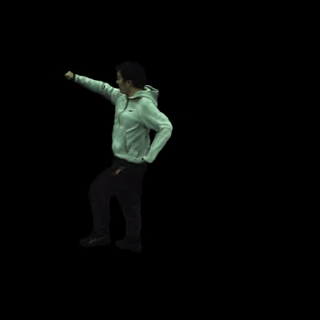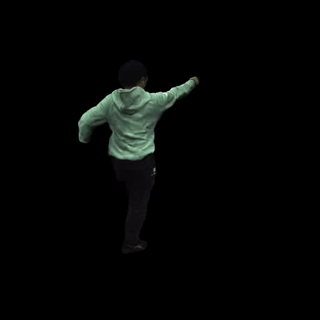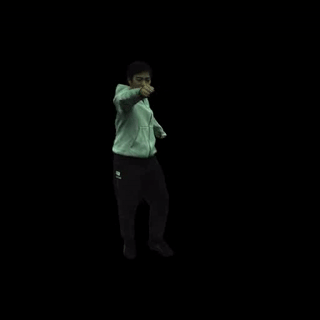
-
文本驱动的动作生成: 结合动作生成模型(如MDM),MonoHuman可以根据文本描述生成并渲染相应的动作序列。例如,"一个人正在做后空翻"。
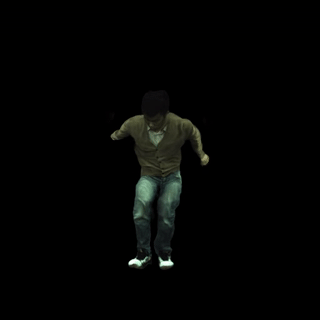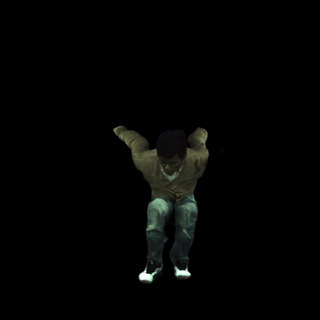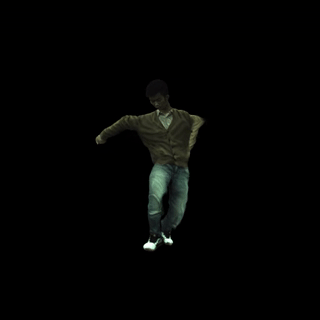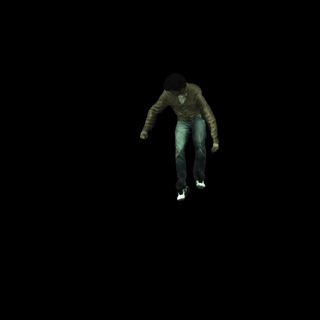
-
真实世界视频处理: MonoHuman不仅适用于实验室环境,还能处理真实世界的视频数据,展现出强大的实用性。

MonoHuman的技术实现
MonoHuman的实现基于PyTorch深度学习框架。研究团队提供了详细的安装指南和使用说明,使得其他研究者和开发者能够轻松地复现和扩展这项工作。主要步骤包括:
- 环境配置:使用Anaconda创建虚拟环境。
- 数据准备:支持ZJU-Mocap数据集和自定义的真实世界视频数据。
- 模型训练:提供了单机和分布式训练的脚本。
- 渲染和评估:包括动作序列渲染、自由视角渲染和文本驱动的动作渲染。
MonoHuman的未来展望
MonoHuman的成功为人体建模和动画领域开辟了新的研究方向。未来的工作可能包括:
- 进一步提高对极具挑战性姿势的处理能力。
- 增强对复杂场景和多人交互的支持。
- 优化计算效率,实现实时渲染。
- 探索与其他模态(如音频)的结合,创造更丰富的交互体验。
MonoHuman的出现无疑为虚拟现实、数字娱乐、在线教育等领域带来了新的可能性。随着技术的不断完善和应用的深入,我们可以期待看到更多令人惊叹的虚拟人物动画应用。
结语
MonoHuman代表了人体神经场景建模和动画技术的最新进展。它不仅在技术上实现了突破,还为相关应用领域带来了无限可能。随着这项技术的不断发展和完善,我们有理由相信,更加逼真、自然的虚拟人物交互体验将在不久的将来成为现实。
对于有兴趣深入了解或尝试使用MonoHuman的读者,可以访问项目的GitHub仓库获取更多信息和资源。让我们共同期待MonoHuman及相关技术在未来带来的更多惊喜和突破!









