
nanoT5:高效快速预训练和微调T5模型的开源框架
近年来,大型语言模型如T5在自然语言处理领域取得了革命性的进展。然而,这些模型的巨大计算需求阻碍了大部分研究人员对其进行深入研究。为了解决这一挑战,来自爱丁堡大学的研究人员Piotr Nawrot开发了nanoT5 - 一个专门针对T5模型优化的PyTorch框架,旨在让研究人员能够在有限计算资源下高效地预训练和微调T5模型。
nanoT5的主要特点
-
高效预训练: nanoT5允许研究人员在单个A100 GPU上仅用16小时就能预训练一个T5-Base模型(2.48亿参数),而且性能不会有明显损失。
-
简化流程: 该框架简化了T5模型的训练流程,为NLP研究提供了一个用户友好的起点模板。
-
开源透明: nanoT5的所有代码、配置和训练日志都公开可用,大大提高了NLP研究的可访问性。
-
PyTorch实现: 基于广泛使用的PyTorch框架实现,使更多研究人员能够容易地使用和修改。

核心创新
nanoT5的核心贡献不在于T5模型本身,而是对整个训练流程的优化:
-
数据处理优化:
- 实现了C4数据集的并行下载和预处理,与模型训练同步进行。
- 这使得研究人员可以在几分钟内就开始预训练自己的T5模型,而不需要提前下载和处理庞大的数据集。
-
优化器改进:
- 分析了Adafactor和AdamW优化器的差异。
- 通过在AdamW中引入矩阵级学习率RMS缩放,显著提高了训练稳定性和效率。
-
训练流程暴露:
- 使用HuggingFace Accelerator实现了检查点保存、梯度累积等操作。
- 采用neptune.ai进行实验跟踪,使用hydra管理超参数。
- 提供了T5模型、训练循环、数据预处理等的简化实现,便于理解和修改。
-
效率优化:
- 采用混合精度训练(TF32 & BF16)
- 使用PyTorch 2.0 compile功能
- 实现了多项已知的优化技巧
预训练性能
在预训练方面,nanoT5展现出了令人印象深刻的性能:
- 在C4数据集的保留测试集上,nanoT5在16小时内达到了1.953的负对数似然损失。
- 相比之下,原始T5论文报告的结果是1.942,但使用了150倍以上的计算资源。
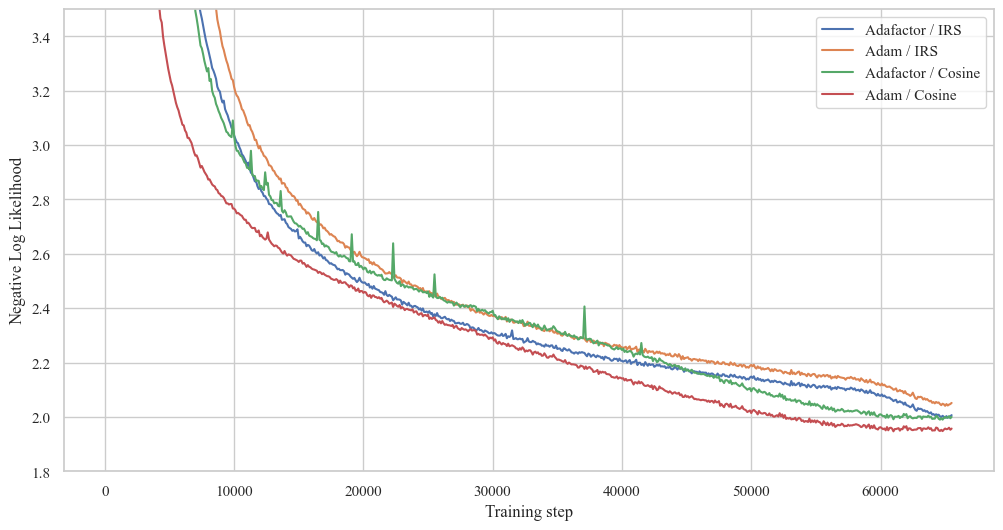
上图展示了不同优化器(Adafactor vs AdamW)和学习率调度器(ISR vs Cosine)组合的训练损失曲线。可以看出,nanoT5提出的AdamW+RMS缩放+Cosine调度的组合表现最佳。
微调性能
为了评估预训练模型的下游任务性能,研究人员在Super-Natural Instructions (SNI)数据集上进行了微调:
- 经过16小时预训练的nanoT5模型在SNI测试集上达到了40.7的Rouge-L分数。
- 相比之下,HuggingFace上原始的T5-base-v1.1模型(训练资源是nanoT5的150倍)的分数为40.9。
- 这意味着nanoT5几乎复现了原始T5模型的性能,但仅用了极少的计算资源。
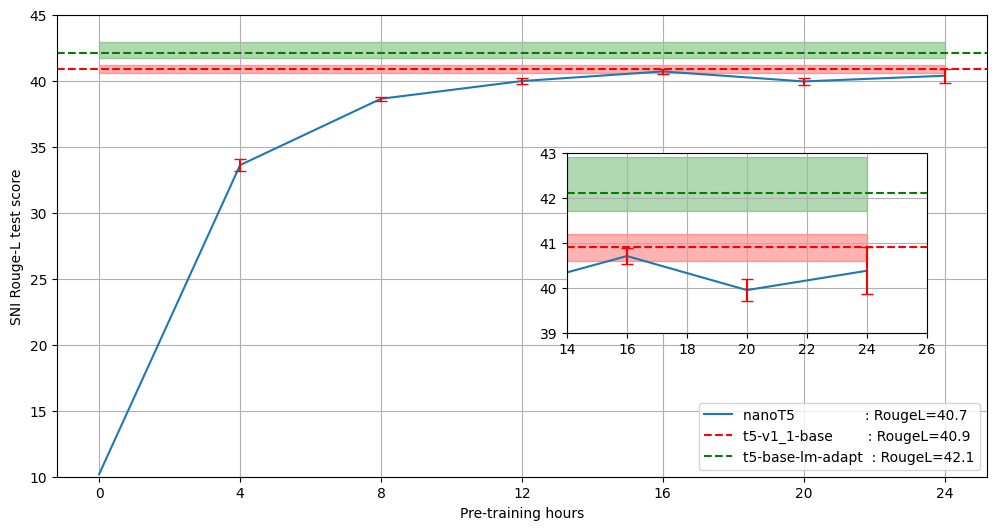
上图展示了不同预训练时长的nanoT5模型与原始T5模型在SNI任务上的Rouge-L分数对比。可以看出,经过16小时预训练的nanoT5模型已经非常接近原始T5模型的性能。
使用nanoT5
研究人员可以通过以下步骤快速开始使用nanoT5:
- 克隆仓库并安装依赖:
git clone https://github.com/PiotrNawrot/nanoT5.git
cd nanoT5
conda create -n nanoT5 python=3.8
conda activate nanoT5
pip install -r requirements.txt
- 运行预训练:
python -m nanoT5.main \
optim.name={adafactor,adamwscale} \
optim.lr_scheduler={legacy,cosine}
- 运行微调:
python -m nanoT5.main task=ft \
model.name={google/t5-v1_1-base,google/t5-base-lm-adapt} \
model.random_init={true,false} \
model.checkpoint_path={"","/path/to/pytorch_model.bin"}
结论与展望
nanoT5成功展示了在有限计算资源下预训练大型语言模型的可能性。它为NLP研究人员提供了一个高效、透明的工具,使更多人能够参与到语言模型的研究中来。未来,nanoT5团队计划进一步优化框架,探索更多高效训练技术,并支持更多模型架构。
通过nanoT5这样的工具,我们有望看到更多创新性的NLP研究成果,推动整个领域的发展。对于有兴趣深入研究语言模型的研究人员和开发者来说,nanoT5无疑是一个值得关注和尝试的项目。
🔗 项目链接: nanoT5 GitHub仓库
总的来说,nanoT5为NLP研究领域带来了一股新鲜空气,它证明了即使在资源受限的情况下,也能进行高质量的语言模型研究。这个项目不仅为学术研究提供了便利,也为工业界在特定领域快速训练和部署自定义语言模型开辟了可能性。随着更多研究者参与到nanoT5的开发和使用中来,我们有理由期待看到更多基于T5架构的创新应用和突破性研究成果。












