
NEFTune: 噪声嵌入助力语言模型指令微调
在人工智能和自然语言处理领域,大型语言模型(LLM)的微调一直是研究的热点。最近,来自马里兰大学等机构的研究团队提出了一种名为NEFTune的创新技术,为LLM的指令微调带来了显著的性能提升。本文将详细介绍NEFTune的原理、实现方法及其在多个数据集上的出色表现。
NEFTune的核心思想
NEFTune,全称"Noisy Embedding Instruction Fine Tuning",其核心思想是在模型微调的前向传播过程中,向训练数据的嵌入向量添加随机噪声。这种简单而巧妙的技巧能够显著提高指令微调的效果,而且不需要额外的计算资源或数据。
NEFTune的工作原理可以概括为以下几点:
- 在训练阶段,向模型的词嵌入层添加均匀分布的随机噪声
- 噪声的幅度由一个可调节的参数α控制
- 在推理阶段,不添加噪声,保持模型的正常行为
这种方法的优势在于:
- 实现简单,只需要修改模型的嵌入层前向传播函数
- 无需额外的计算资源或训练数据
- 对模型架构和训练流程影响小,易于集成到现有系统中
NEFTune的实现
要在现有的训练流程中加入NEFTune非常简单。以下是一个针对LLaMA模型的Python实现示例:
from torch.nn import functional as F
def NEFTune(model, noise_alpha=5):
def noised_embed(orig_embed, noise_alpha):
def new_func(x):
if model.training:
embed_init = orig_embed(x)
dims = torch.tensor(embed_init.size(1) * embed_init.size(2))
mag_norm = noise_alpha/torch.sqrt(dims)
return embed_init + torch.zeros_like(embed_init).uniform_(-mag_norm, mag_norm)
else:
return orig_embed(x)
return new_func
orig_forward = model.base_model.embed_tokens.forward
model.base_model.embed_tokens.forward = noised_embed(orig_forward, noise_alpha)
return model
这段代码重写了模型的嵌入层前向传播函数,在训练时添加随机噪声,而在推理时保持原有行为。
NEFTune的惊人效果
NEFTune在多个数据集和模型上都展现出了令人印象深刻的性能提升。以下是一些具体的实验结果:
-
LLaMA-2-7B模型上的表现:
- 使用Alpaca数据集进行微调
- 在AlpacaEval基准测试中,性能从29.8%提升到64.7%
- 提升幅度高达35个百分点
-
在现代指令数据集上的表现:
- 应用于Evol-Instruct、ShareGPT和OpenPlatypus等数据集
- 相比基线模型,性能提升8%到10%
-
对已经经过RLHF(基于人类反馈的强化学习)训练的模型:
- 如LLaMA-2-Chat模型
- 使用NEFTune进行额外训练仍能带来显著收益
-
Mistral-7B-v0.1模型:
- 在OpenAssistant数据集上使用NEFTune训练
- 在MT Bench基准测试中性能提升约25%
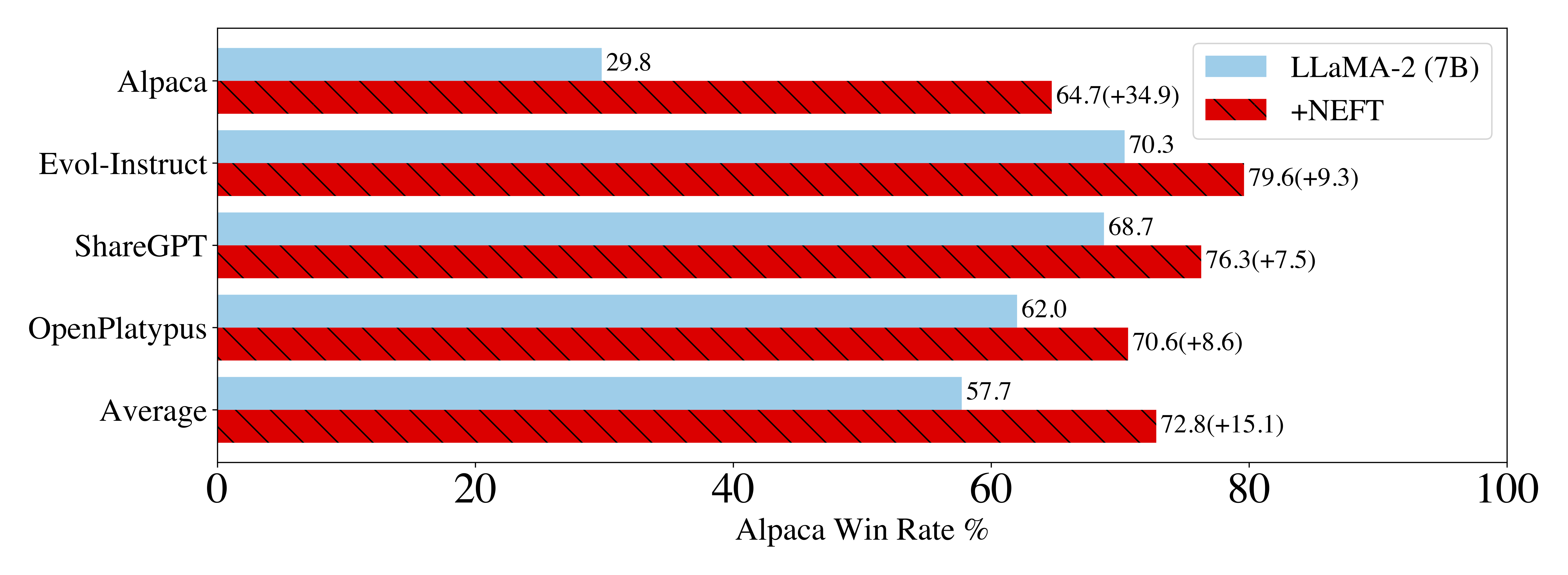
这张图清晰地展示了NEFTune在LLaMA-2-7B模型上的惊人效果。可以看到,添加噪声嵌入后,模型在AlpacaEval基准测试上的性能大幅提升。
NEFTune的工作原理
虽然NEFTune的效果显著,但其具体工作原理仍有待进一步研究。目前的假设是:
- 添加噪声可以防止模型过度拟合指令微调数据集的特定格式和措辞
- 噪声可能起到正则化的作用,提高模型的泛化能力
- 噪声嵌入可能有助于模型探索更广阔的语义空间,生成更丰富多样的回答
研究者们认为,通过添加噪声,模型不再仅仅死记硬背指令数据集中的内容,而是能够更好地利用预训练阶段获得的知识,从而在对话任务中表现出更强的能力。
NEFTune的应用与集成
由于NEFTune的简单性和有效性,它已经被集成到多个主流的深度学习框架和工具中:
- Hugging Face的TRL(Transformer Reinforcement Learning)库
- Hugging Face Trainer
- Ludwig.ai平台
这些集成使得研究者和开发者可以更方便地在自己的项目中使用NEFTune技术。例如,在使用Hugging Face的SFTTrainer时,只需添加一个neftune_noise_alpha参数即可启用NEFTune:
training_arguments = TrainingArguments(
output_dir=output_dir,
max_steps=100,
report_to="tensorboard",
neftune_noise_alpha=5,
fp16=True
)
NEFTune的局限性
尽管NEFTune表现出色,研究团队也坦诚了当前研究的一些局限性:
-
评估指标的单一性:主要依赖AlpacaEval作为指令跟随能力的衡量标准,而AlpacaEval使用GPT-4作为单一评判者,可能存在偏见。
-
计算资源限制:由于资源有限,研究团队未能在LLaMA-2的70B参数版本上进行多数据集的验证。
-
超参数固定:大多数NEFTune实验使用固定的超参数,而非进行全面的参数搜索。
-
理论解释不足:尽管进行了大量实证研究,但对NEFTune为何如此有效仍缺乏完整的理论解释。
未来展望
NEFTune的成功为语言模型微调开辟了一个新的研究方向。未来的工作可能会集中在以下几个方面:
-
理论基础:深入研究NEFTune的工作原理,建立更加完善的理论框架。
-
适用性扩展:验证NEFTune在更多模型架构和任务类型上的效果。
-
参数优化:开发自动化的方法来为不同模型和数据集找到最佳的噪声参数。
-
与其他技术结合:探索NEFTune与其他先进的微调技术(如LoRA、P-tuning等)的结合使用。
-
大规模验证:在更大规模的模型和更多样化的数据集上验证NEFTune的效果。
结语
NEFTune作为一种简单而有效的指令微调技术,为大型语言模型的性能优化提供了一个新的视角。它不仅在多个基准测试中展现出显著的性能提升,而且易于实现和集成,几乎没有额外的计算开销。尽管还存在一些局限性和未解之谜,NEFTune无疑为自然语言处理领域带来了新的机遇和挑战。
随着更多研究者的关注和探索,我们有理由期待NEFTune技术在未来能够得到更广泛的应用,并为大型语言模型的发展做出更大的贡献。同时,NEFTune的成功也启发我们,在人工智能领域,有时候看似简单的想法也可能带来革命性的突破。这再次证明了保持开放思维和勇于尝试的重要性。
参考资源
- NEFTune GitHub仓库: https://github.com/neelsjain/NEFTune
- NEFTune论文: https://arxiv.org/abs/2310.05914
- Hugging Face TRL文档: https://huggingface.co/docs/trl/main/en/sft_trainer
对于那些希望在自己的项目中尝试NEFTune的开发者和研究者,建议先仔细阅读官方文档和论文,然后从小规模实验开始,逐步探索这项技术在不同场景下的应用。同时,也欢迎大家在GitHub上提出问题、反馈使用体验,共同推动NEFTune技术的发展与完善。









