
引言
时间序列预测是一个具有广泛应用的重要任务,涉及金融、气象、交通等多个领域。近年来,Transformer模型凭借其强大的长程依赖建模能力,在时间序列预测中取得了显著成果。然而,现实世界中的时间序列数据往往呈现出非平稳特性,即数据的统计特征随时间变化,这给Transformer模型带来了巨大挑战。
为了解决这一问题,清华大学研究团队提出了一种新的非平稳Transformers框架。该框架通过巧妙设计的序列平稳化和去平稳注意力机制,有效提高了模型对非平稳时间序列的预测能力。本文将详细介绍这一创新框架的设计思路、核心组件以及在多个基准数据集上的出色表现。
非平稳Transformers框架
框架概述
非平稳Transformers框架主要包含两个关键组件:序列平稳化(Series Stationarization)和去平稳注意力(De-stationary Attention)。这两个组件协同工作,旨在解决非平稳时间序列预测中的两个核心问题:数据的可预测性和模型的表达能力。
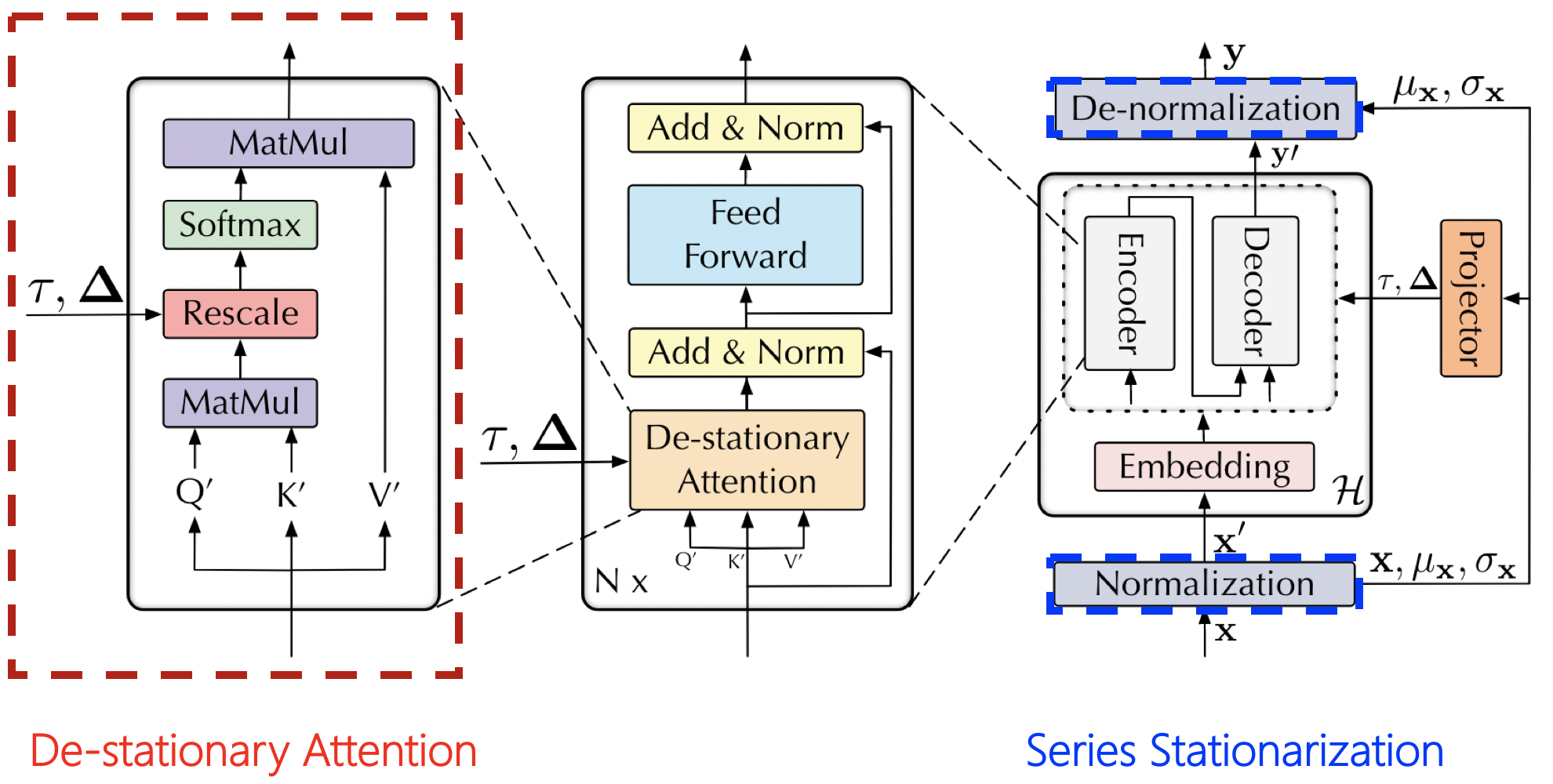
序列平稳化
序列平稳化模块的目标是统一每个输入序列的统计特征,从而提高数据的可预测性。具体来说,该模块通过以下步骤实现:
- 对输入序列进行标准化处理,使其均值为0,方差为1。
- 将标准化后的序列输入Transformer模型进行预测。
- 在输出阶段,恢复预测结果的原始统计特征,以获得最终的预测值。
这一过程可以用下图直观表示:
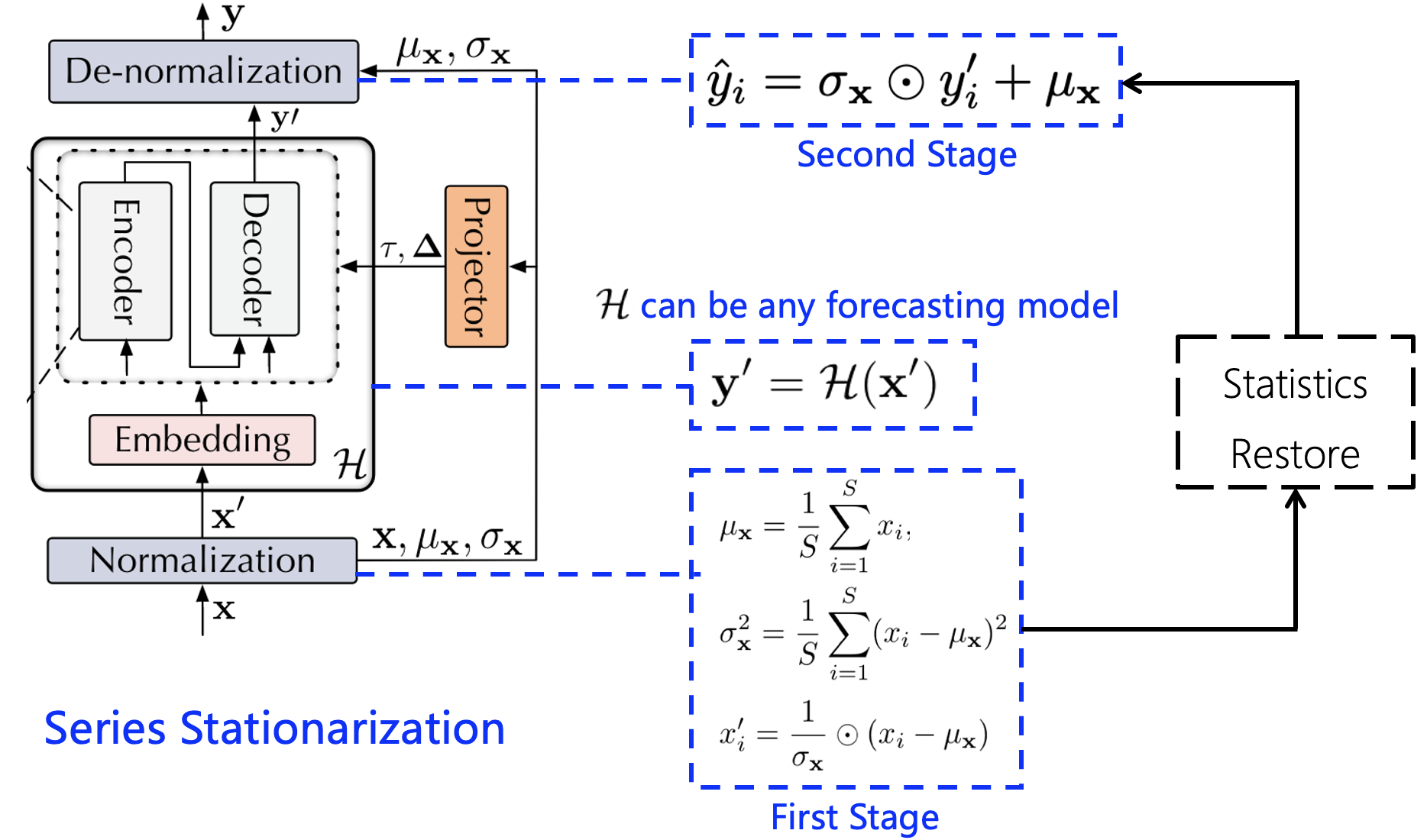
序列平稳化的优势在于,它能够在保留原始序列非平稳信息的同时,提高数据的可预测性。这一特性对于准确预测现实世界中的突发事件尤为重要。
去平稳注意力
去平稳注意力机制是为了解决过度平稳化问题而设计的。在传统的平稳化处理中,模型可能会丢失序列中的重要非平稳信息,导致对不同序列生成相似的注意力分布。为了克服这一缺陷,去平稳注意力机制通过以下方式恢复非平稳信息:
- 首先,模型学习原始非平稳序列的注意力分布。
- 然后,通过近似这些区分性强的注意力分布,将非平稳信息重新引入到时间依赖关系中。
这一过程可以用下图表示:

通过去平稳注意力机制,模型能够在保持数据可预测性的同时,有效捕捉序列中的非平稳特征,从而提高预测准确性。
实验结果与分析
为了验证非平稳Transformers框架的有效性,研究团队在多个基准数据集上进行了广泛的实验。实验结果表明,该框架能够显著提升多种主流Transformer模型的性能。
主要实验结果
在多变量时间序列预测任务中,配备了非平稳框架的vanilla Transformer在所有六个基准数据集和不同预测长度上均取得了最先进的性能。下图展示了详细的实验结果:
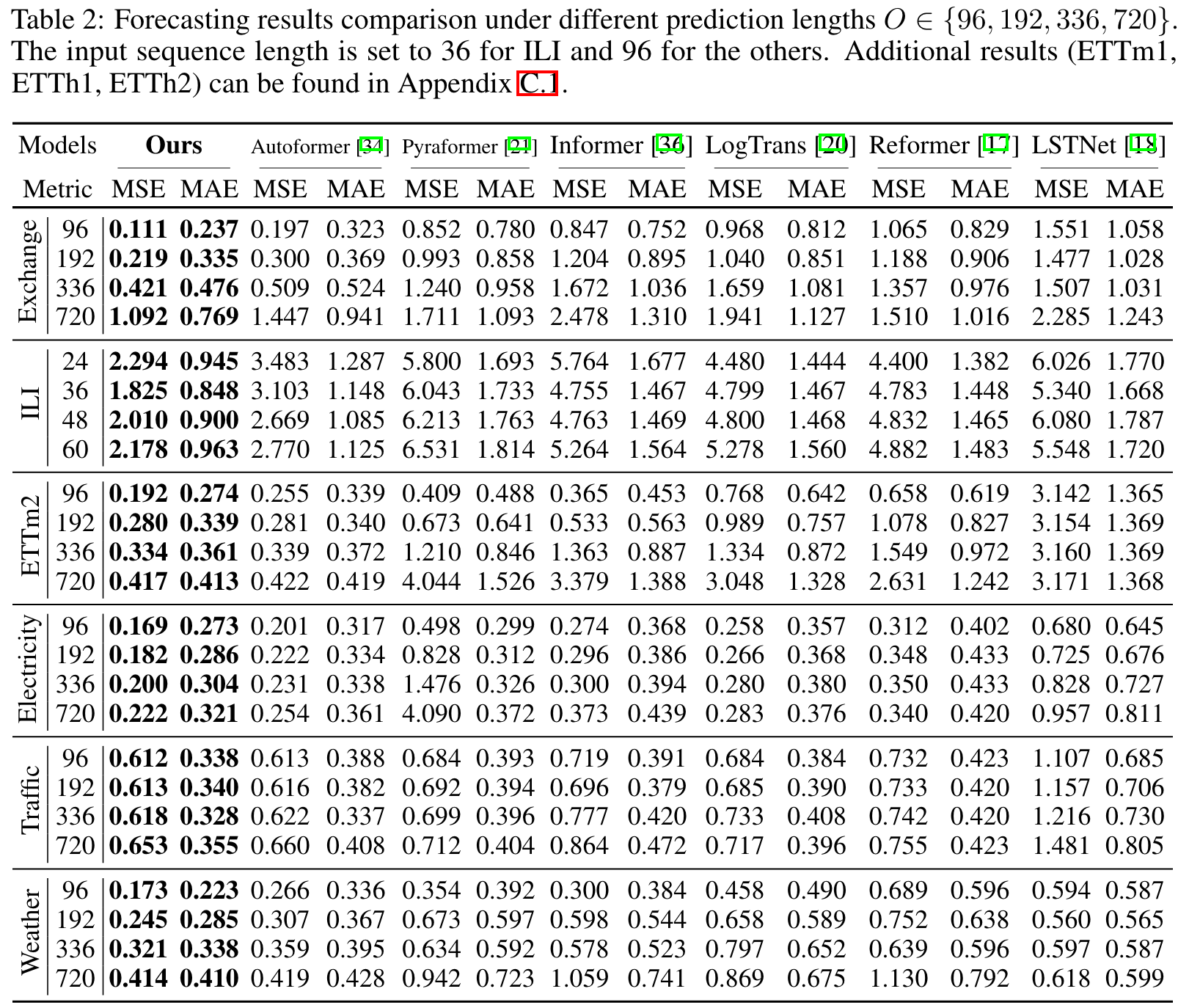
模型性能提升
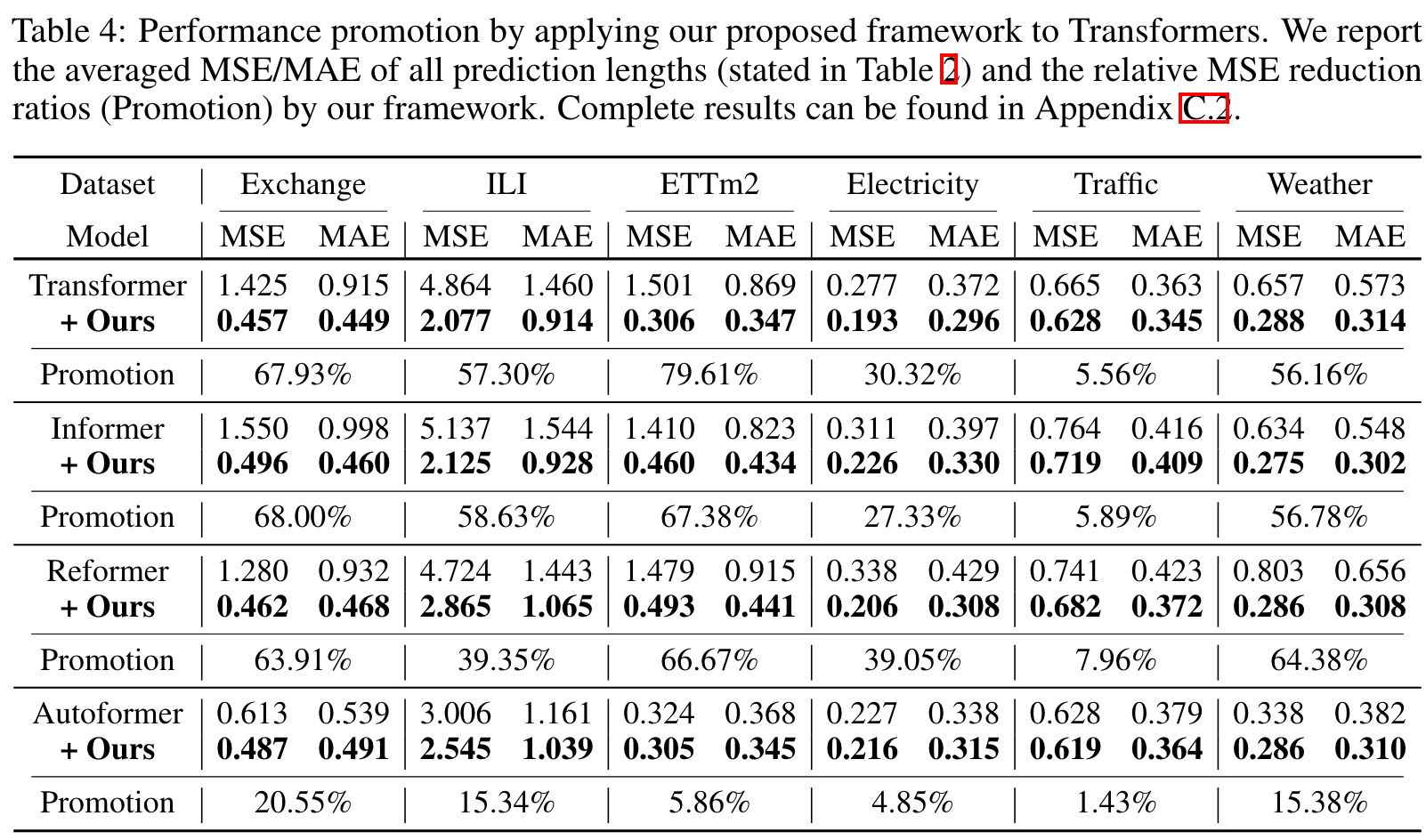
研究团队将非平稳框架应用于六种主流的基于注意力的模型,结果显示该方法能够一致地提高模型的预测能力。具体来说:
- Transformer: 平均提升49.43%
- Informer: 平均提升47.34%
- Reformer: 平均提升46.89%
- Autoformer: 平均提升10.57%
- ETSformer: 平均提升5.17%
- FEDformer: 平均提升4.51%
这些提升使得每个模型都超越了之前的最先进水平。下图直观展示了各模型的性能提升:
结论与未来展望
非平稳Transformers框架通过创新的序列平稳化和去平稳注意力机制,有效解决了时间序列预测中的非平稳性问题。实验结果表明,该框架能够显著提升多种Transformer模型在不同任务和数据集上的性能。
未来,研究团队计划将非平稳Transformers框架应用于更多的模型,包括但不限于:
- iTransformer
- Crossformer
- FEDformer
此外,序列平稳化作为一个独立于架构的模块,已被广泛应用于解决时间序列中的非平稳性问题。感兴趣的读者可以参考time-series-library以了解更多实现细节。
总的来说,非平稳Transformers框架为处理非平稳时间序列预测任务提供了一种有效的解决方案,为该领域的进一步研究和应用开辟了新的方向。随着框架的不断完善和应用范围的扩大,我们有理由相信,它将在金融预测、气象预报、交通流量预测等实际应用中发挥越来越重要的作用。
如果您对这项研究感兴趣,欢迎访问项目GitHub仓库获取更多信息和代码实现。同时,研究团队也欢迎学术界和工业界的同仁们就相关问题进行深入讨论和合作。让我们共同推动时间序列预测技术的发展,为解决现实世界中的复杂预测问题贡献力量。









