
pix2pix简介
pix2pix是由Phillip Isola、Jun-Yan Zhu、Tinghui Zhou和Alexei A. Efros于2017年在CVPR会议上提出的一种图像到图像转换技术。它基于条件生成对抗网络(cGAN)的框架,能够学习输入图像到输出图像的映射关系,实现多种图像处理任务。
pix2pix的核心思想是使用成对的图像数据进行训练,其中一张图像作为输入,另一张图像作为目标输出。通过对抗训练,生成器网络学习将输入图像转换为目标图像,而判别器网络则学习区分真实图像和生成图像。这种方法使得pix2pix能够捕捉到复杂的图像转换规则,生成高质量的结果。
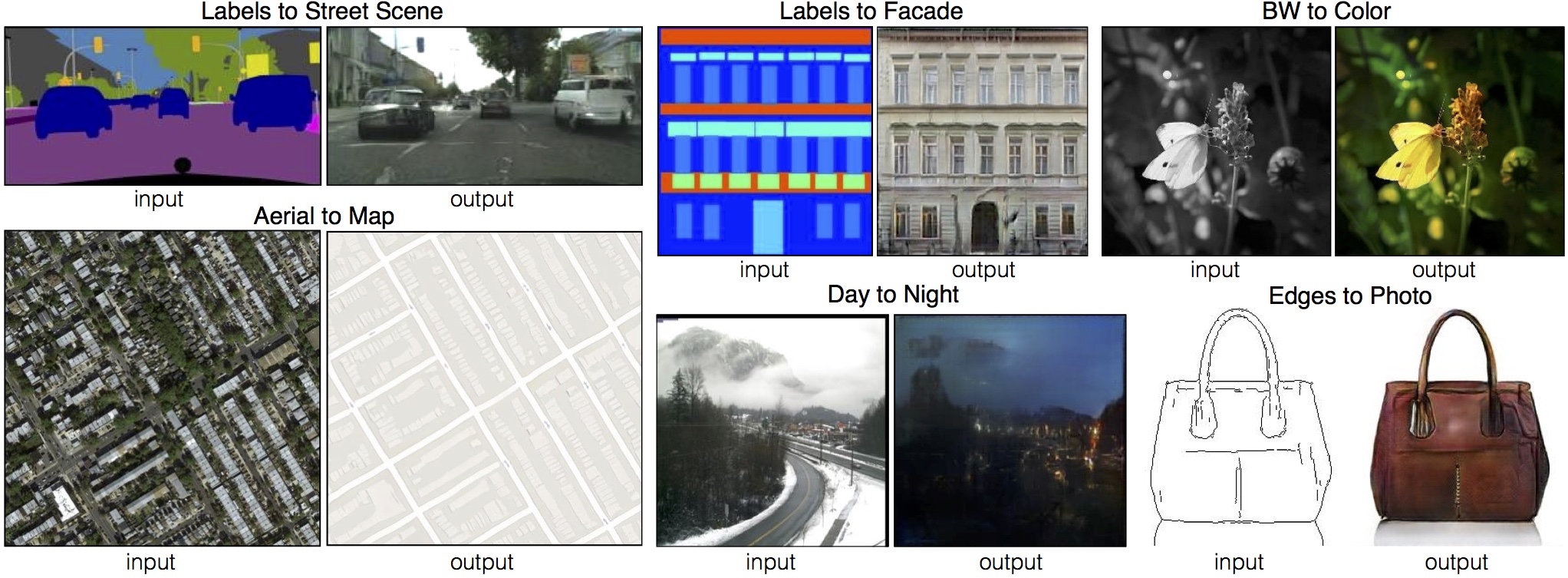
上图展示了pix2pix在多个任务上的应用效果,包括标签图到街景图、航拍图到地图、轮廓图到物体图等。可以看到,pix2pix能够生成逼真的目标图像,保持输入图像的结构信息。
pix2pix的工作原理
pix2pix的网络架构主要包括生成器和判别器两个部分:
-
生成器网络:采用U-Net结构,能够保留输入图像的低层次特征。它接收输入图像,通过多层卷积和反卷积操作生成目标图像。
-
判别器网络:采用PatchGAN结构,对图像块进行真假判别。它接收一对图像(输入图像和生成/真实图像),判断生成图像的真实程度。
训练过程中,生成器和判别器进行对抗学习:
- 生成器试图生成逼真的图像来欺骗判别器
- 判别器努力区分真实图像和生成图像
- 两个网络不断博弈,最终生成器能够产生高质量的转换结果
pix2pix的损失函数包括:
- 对抗损失:促使生成图像接近真实分布
- L1损失:保证生成图像和目标图像的像素级相似性
这种设计使得pix2pix能够学习到复杂的图像转换规则,生成既真实又符合目标的图像。
pix2pix的应用场景
pix2pix在多个图像处理任务中展现出优秀的性能:
-
图像着色 将黑白图像转换为彩色图像,为老照片上色。
-
图像修复 修复破损或缺失的图像区域,如老照片修复。
-
风格迁移 将一种艺术风格应用到普通照片上,如将照片转换为梵高画作风格。
-
图像超分辨率 将低分辨率图像转换为高分辨率图像,提升图像质量。
-
语义分割 将图像中的每个像素分类为特定的语义类别,如将街景图像分割为道路、建筑、行人等类别。
-
草图到真实图像 将简单的线条草图转换为逼真的物体图像,如将手绘鞋子草图转换为真实鞋子照片。
-
昼夜转换 将白天场景转换为夜晚场景,或反之。
-
卫星图像到地图 将卫星航拍图像转换为地图样式的图像。
这些应用展示了pix2pix在图像处理和计算机视觉领域的广泛潜力。
pix2pix的实现和使用
pix2pix最初是使用Torch框架实现的,但目前已有多个深度学习框架的实现版本。其中,PyTorch版本是最活跃的开发版本,能够产生与原始Torch版本相当或更好的结果。
要使用pix2pix,主要步骤如下:
-
准备数据集:收集成对的图像数据,如{输入图像, 目标图像}。
-
训练模型:
python train.py --dataroot ./datasets/facades --name facades_pix2pix --model pix2pix --direction BtoA -
测试模型:
python test.py --dataroot ./datasets/facades --name facades_pix2pix --model pix2pix --direction BtoA
pix2pix还提供了多个预训练模型,可以直接用于推理:
- facades_label2photo: 将建筑标签图转换为真实照片
- map2sat: 将地图转换为卫星图像
- edges2shoes: 将鞋子轮廓图转换为真实鞋子图像
使用这些预训练模型,可以快速体验pix2pix的强大功能。
pix2pix的优势与局限性
pix2pix的主要优势包括:
-
通用性强:可应用于多种图像转换任务,只需更换训练数据。
-
生成质量高:通过对抗训练,能生成逼真的高质量图像。
-
端到端学习:无需手动设计特征,直接从数据中学习转换规则。
-
训练稳定:相比其他GAN模型,pix2pix的训练过程更加稳定。
然而,pix2pix也存在一些局限性:
-
需要成对数据:训练需要大量成对的图像数据,在某些领域可能难以获取。
-
模式崩溃:在某些情况下可能出现模式崩溃,生成的图像缺乏多样性。
-
分辨率限制:对于高分辨率图像的处理能力有限。
-
泛化能力:对于训练集之外的数据,泛化能力可能不足。
研究人员正在不断改进pix2pix,以克服这些局限性。例如,CycleGAN通过循环一致性损失解决了对成对数据的依赖,而pix2pixHD则提高了对高分辨率图像的处理能力。
pix2pix的最新进展
自pix2pix提出以来,研究人员在此基础上开发了多个改进版本:
-
pix2pixHD: 能够生成更高分辨率的图像,最高可达2048x1024像素。
-
vid2vid: 将pix2pix扩展到视频领域,实现视频到视频的转换。
-
SPADE: 改进了生成器网络,能更好地保留语义信息,生成更逼真的图像。
-
MUNIT: 实现了多模态的图像转换,可以生成多种风格的输出图像。
-
GauGAN: 结合了SPADE和pix2pixHD,实现了交互式的图像生成和编辑。
这些进展大大扩展了pix2pix的应用范围和性能,使其在图像生成和编辑领域保持领先地位。
结论
pix2pix作为一种强大的图像到图像转换技术,在计算机视觉和图像处理领域产生了深远的影响。它不仅在学术界引起了广泛关注,也在工业界找到了众多应用场景。随着深度学习和生成对抗网络技术的不断发展,我们可以期待看到更多基于pix2pix的创新应用,为图像处理和计算机视觉领域带来更多可能性。
无论是研究人员还是开发者,都可以尝试使用pix2pix来解决各种图像转换问题。通过探索不同的数据集和应用场景,相信pix2pix还有更多潜力等待我们去挖掘。未来,随着硬件性能的提升和算法的优化,pix2pix有望在更多领域发挥重要作用,推动人工智能技术的进步。
参考资源
- pix2pix项目主页
- pix2pix GitHub仓库
- Image-to-Image Translation with Conditional Adversarial Networks
- pix2pix PyTorch实现
通过这些资源,读者可以深入了解pix2pix的技术细节,并尝试在自己的项目中应用这一强大的图像转换工具。无论是研究还是实际应用,pix2pix都为图像处理领域带来了新的可能性和机遇。











