
pix2pixHD: 高分辨率图像合成与语义操作的条件生成对抗网络
pix2pixHD是由NVIDIA研究团队开发的一种用于高分辨率图像合成和语义操作的条件生成对抗网络(cGAN)模型。该模型在2018年的IEEE计算机视觉与模式识别会议(CVPR)上发表,引起了广泛关注。pix2pixHD在原有pix2pix模型的基础上进行了改进,能够生成高达2048x1024分辨率的逼真图像,在街景生成、人脸编辑等多个图像转换任务中取得了显著的效果。
主要特点
pix2pixHD模型具有以下几个主要特点:
-
高分辨率输出: 能够生成2048x1024分辨率的高质量图像,远超过之前模型的能力。
-
多尺度判别器: 采用多个不同尺度的判别器,有助于生成更加逼真的细节。
-
改进的生成器网络: 使用粗到细的生成器架构,包含全局和局部增强网络。
-
特征匹配损失: 引入特征匹配损失,提高了生成图像的视觉质量。
-
实例级特征嵌入: 支持对单个物体实例进行精细控制。
网络架构
pix2pixHD的网络架构主要包含以下几个部分:
-
生成器网络
- 全局生成器: 负责生成整体结构
- 局部增强器: 进一步提升局部细节
-
多尺度判别器
- 3个不同尺度的判别器
- 分别作用于原始、1/2和1/4分辨率
-
编码器网络
- 用于提取实例级特征

应用效果
pix2pixHD在多个图像转换任务上展现出了优异的性能:
- 标签到街景图像生成
pix2pixHD能够将语义分割标签图转换为高度逼真的街景图像。下图展示了从语义标签到生成街景的效果:

- 人脸编辑与合成
模型还可以用于人脸图像的编辑和合成,支持改变发型、表情等属性:

- 交互式图像编辑
pix2pixHD提供了一个交互式编辑界面,用户可以通过修改语义标签来实时控制生成图像的内容:
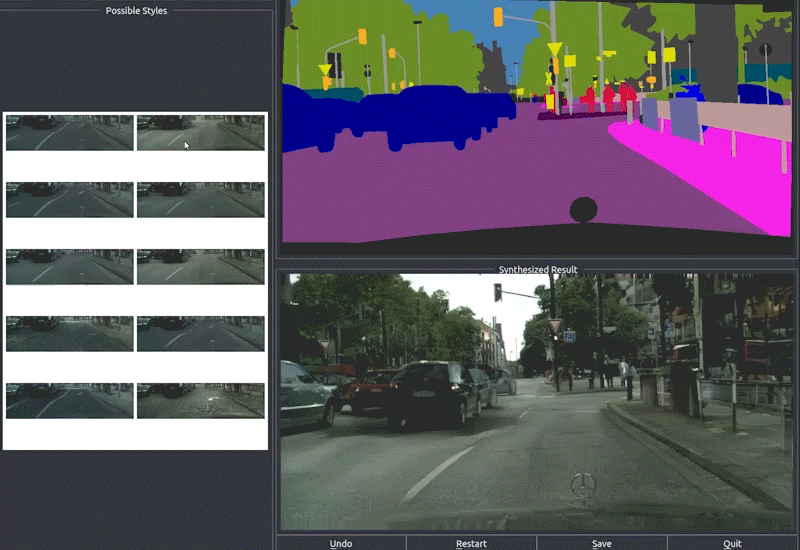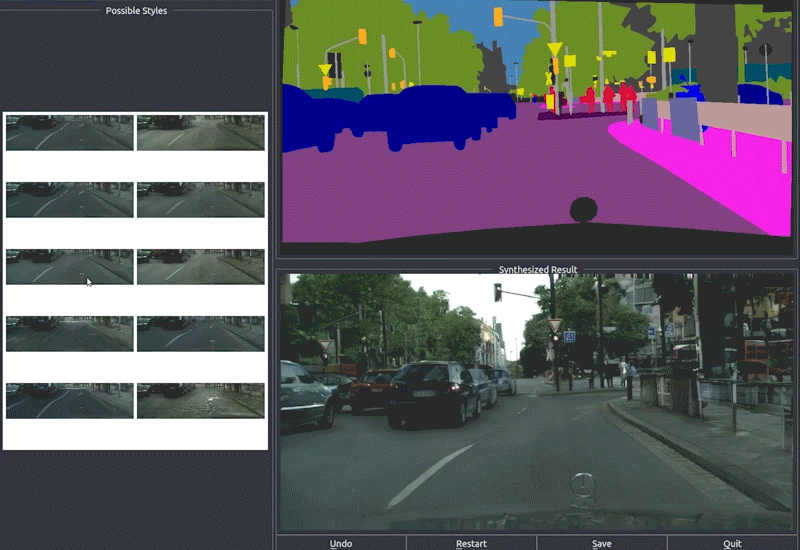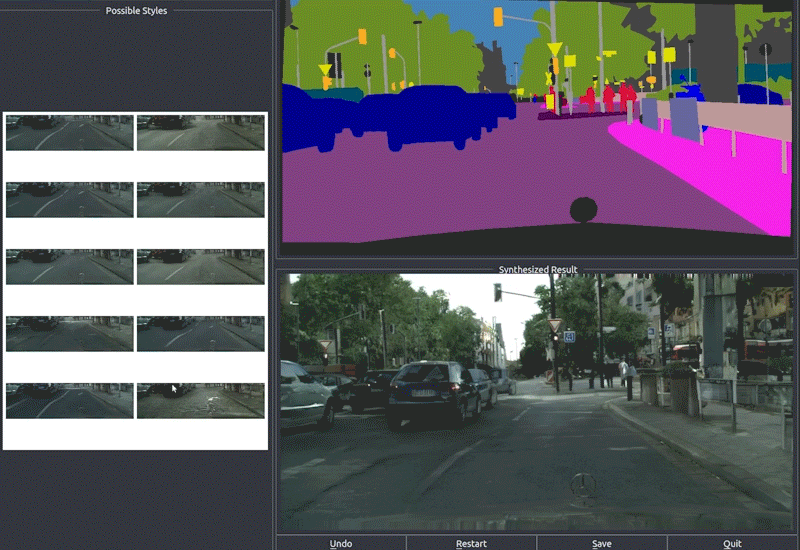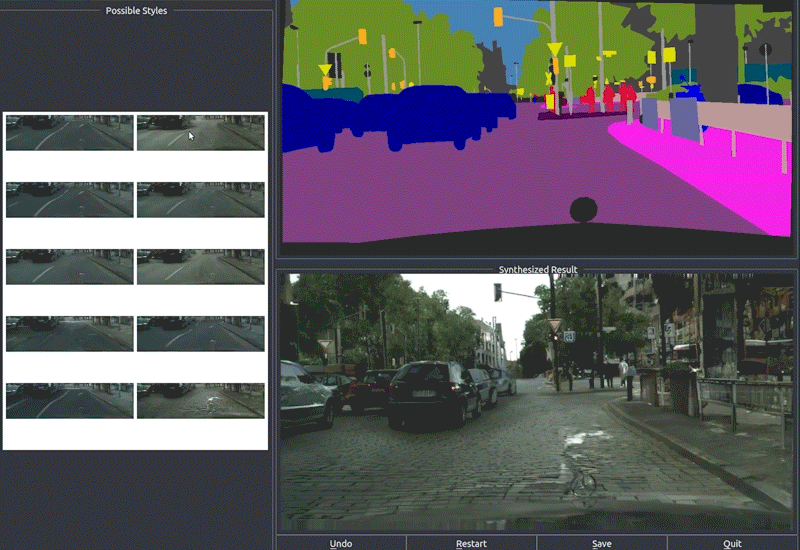
技术细节
- 数据集
pix2pixHD主要使用Cityscapes数据集进行训练和评估。该数据集包含了大量带有精细语义标注的城市街景图像。
- 训练过程
- 首先在较低分辨率(如1024x512)上训练模型
- 然后逐步提高分辨率到2048x1024
- 使用多GPU并行训练以加速
- 损失函数
pix2pixHD的损失函数包括:
- GAN损失: 确保生成图像的真实性
- 特征匹配损失: 提高视觉质量和稳定性
- VGG特征损失: 进一步改善生成效果
- 实现细节
- 基于PyTorch深度学习框架
- 支持多GPU训练
- 提供了预训练模型便于快速测试
使用指南
要使用pix2pixHD,需要满足以下环境要求:
- Linux或macOS操作系统
- Python 2或3
- NVIDIA GPU (至少11GB显存) + CUDA cuDNN
安装步骤:
- 安装PyTorch及相关依赖
- 克隆pix2pixHD代码仓库
- 下载预训练模型(可选)
基本使用流程:
- 准备训练数据(语义标签图和对应的真实图像)
- 修改配置文件设置参数
- 运行训练脚本开始训练
- 使用训练好的模型进行推理生成图像
更多详细的使用说明可以参考项目GitHub页面。
总结与展望
pix2pixHD在高分辨率图像合成领域取得了突破性进展,为计算机视觉和图形学领域带来了新的可能性。该模型不仅可以用于图像转换,还可以应用于图像编辑、虚拟现实内容生成等多个领域。
未来的研究方向可能包括:
- 进一步提高生成图像的分辨率和质量
- 改善模型的训练效率和推理速度
- 探索更多的应用场景,如视频生成等
总的来说,pix2pixHD为高分辨率图像合成和语义操作提供了一个强大的工具,相信会在未来激发出更多创新应用。研究人员和开发者可以基于此模型进行进一步的改进和定制,以满足特定领域的需求。










