
PoseFix: 通用人体姿态优化网络
人体姿态估计是计算机视觉领域的一个重要任务,对于理解人类行为和动作具有重要意义。近年来,随着深度学习技术的发展,人体姿态估计的准确性得到了大幅提升。然而,即使是最先进的方法也难免会出现一些错误,如何进一步优化姿态估计结果成为了一个重要的研究方向。
在这一背景下,来自首尔国立大学的研究人员提出了PoseFix - 一种模型无关的通用人体姿态优化网络。PoseFix可以作为后处理步骤,从单个JSON文件中改进任何姿态估计方法的结果,而无需了解原始方法的代码或实现细节。这种通用性和易用性使PoseFix成为了姿态估计领域的一个重要工具。
PoseFix的工作原理
PoseFix的核心思想是利用现有姿态估计方法的错误统计信息作为先验知识,来生成合成姿态并训练优化网络。具体来说,PoseFix的工作流程如下:
-
收集现有姿态估计方法在训练集上的结果,分析其错误分布特征。
-
根据错误分布特征生成大量合成的输入姿态。
-
将原始图像和合成姿态作为输入,训练PoseFix网络输出优化后的姿态。
-
在测试阶段,将任意方法的姿态估计结果作为输入,通过PoseFix网络获得优化后的结果。
这种设计使得PoseFix能够学习到通用的姿态优化策略,而不依赖于特定的姿态估计方法。
PoseFix的实现细节
PoseFix的官方实现基于TensorFlow框架,主要包含以下几个部分:
- 数据加载和预处理模块,支持MPII、PoseTrack和COCO等主流数据集。
- 姿态合成模块,根据错误统计生成训练用的合成姿态。
- 基于ResNet的主干网络,提取图像特征。
- 多尺度特征融合模块,整合不同层级的特征。
- 姿态回归头,输出优化后的关键点坐标。
- 训练和评估脚本,支持多GPU训练。
PoseFix的代码结构清晰,易于理解和扩展。研究人员可以方便地在此基础上进行进一步的改进和创新。
PoseFix的性能表现
研究人员在多个公开数据集上评估了PoseFix的性能,结果表明PoseFix能够显著提升各种姿态估计方法的准确率。
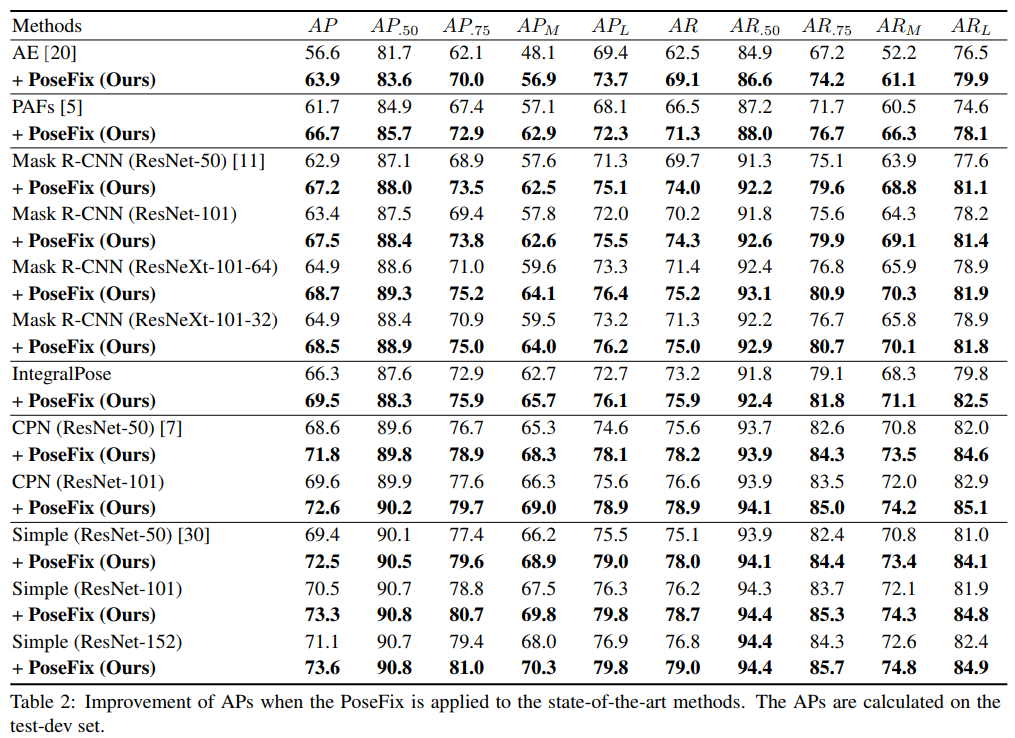
如上图所示,PoseFix在COCO 2017验证集上将多个主流方法的平均精度(AP)提高了1-2个百分点。特别是,PoseFix将当前最先进的HRNet方法的AP从76.3%提升到了77.3%,创造了新的state-of-the-art。
在PoseTrack 2018数据集上,PoseFix同样取得了显著的性能提升:
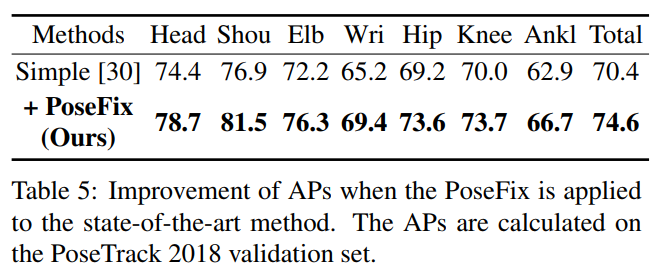
这些结果充分证明了PoseFix作为通用姿态优化工具的有效性和实用价值。
使用PoseFix
PoseFix的使用非常简单,主要包括以下步骤:
-
准备环境:安装TensorFlow、CUDA、cuDNN等依赖。
-
下载数据集和预训练模型。
-
准备姿态估计结果:将任意方法的结果保存为COCO格式的JSON文件。
-
运行测试脚本:
python test.py --gpu 0-1 --test_epoch 140
- 评估优化后的结果。
详细的使用说明可以参考PoseFix的GitHub仓库。
总结与展望
PoseFix作为一种通用的姿态优化方法,具有以下几个显著优点:
-
模型无关:可以优化任意姿态估计方法的结果。
-
易于使用:只需一个JSON文件即可作为输入。
-
性能优异:在多个数据集上显著提升了SOTA方法的准确率。
-
灵活可扩展:代码结构清晰,易于进一步改进。
未来,PoseFix还有很大的发展空间。例如,可以探索更复杂的错误模型来生成更真实的合成姿态,或者引入时序信息来优化视频中的姿态估计结果。总的来说,PoseFix为人体姿态估计领域提供了一个强大而通用的优化工具,有望推动这一领域的进一步发展。
研究人员和开发者可以在PoseFix的GitHub仓库中找到更多技术细节和使用说明。欢迎更多人参与到PoseFix的改进和应用中来,共同推动人体姿态估计技术的进步。









