
ProFusion: 定制化文本到图像生成的新方法
在人工智能和计算机视觉快速发展的今天,文本到图像生成技术已经取得了巨大的进步。然而,如何在保持模型通用性的同时,实现对特定概念或对象的定制化生成,仍然是一个具有挑战性的问题。近日,来自中国科学院自动化研究所的研究团队提出了一种名为ProFusion的新方法,为这一问题提供了一种优雅的解决方案。
ProFusion的核心思想
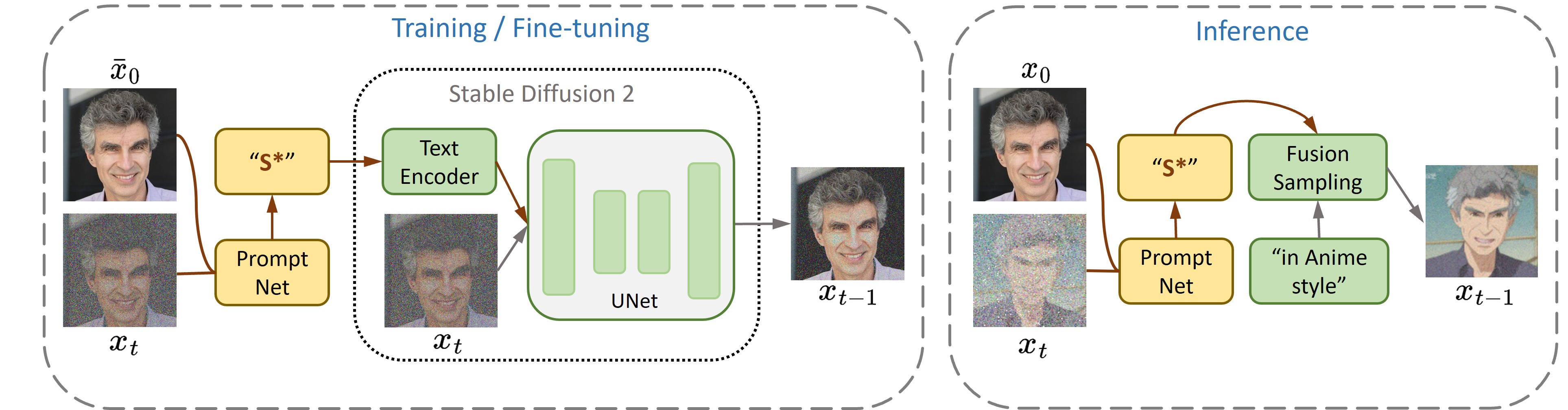
ProFusion的核心思想是通过一个预训练的编码器来增强大规模文本到图像生成模型的定制化能力。具体来说,ProFusion框架包含以下几个关键组件:
-
基础模型: 采用预训练的大规模文本到图像生成模型,如Stable Diffusion 2。
-
PromptNet编码器: 一个专门设计的编码器网络,用于将输入图像编码为文本提示。
-
定制化训练: 使用单张测试图像对模型进行微调,实现对特定概念的定制化。
-
推理生成: 利用微调后的模型,基于文本提示生成定制化的图像。
这种方法的独特之处在于,它无需使用复杂的正则化技术,就能在保持模型通用性的同时,实现对特定概念的高质量定制化生成。
ProFusion的优势
ProFusion相比于传统的定制化方法具有以下几个显著优势:
-
细节保留: 能够很好地保留测试图像中的细节特征,生成的图像更加逼真和准确。
-
高效性: 只需要单张测试图像和较短的微调时间,就能实现定制化生成。
-
灵活性: 可以生成无限多的创意变体,满足多样化的应用需求。
-
通用性: 不仅限于人脸等特定领域,还可以应用于各种概念和对象的定制化生成。
-
资源友好: 在单个GPU(约20GB显存)上即可完成训练和推理。
应用示例
研究团队展示了ProFusion在多个领域的应用效果:
-
人物肖像定制化: 基于单张人物照片,生成各种不同场景、表情和风格的肖像。
-
物品定制化: 将特定物品(如玩具、食物等)放置在不同环境中,或改变其属性。
-
场景定制化: 基于一张场景图片,生成不同天气、季节或时间的变体。
-
风格迁移: 将特定对象的风格应用到其他图像生成中。
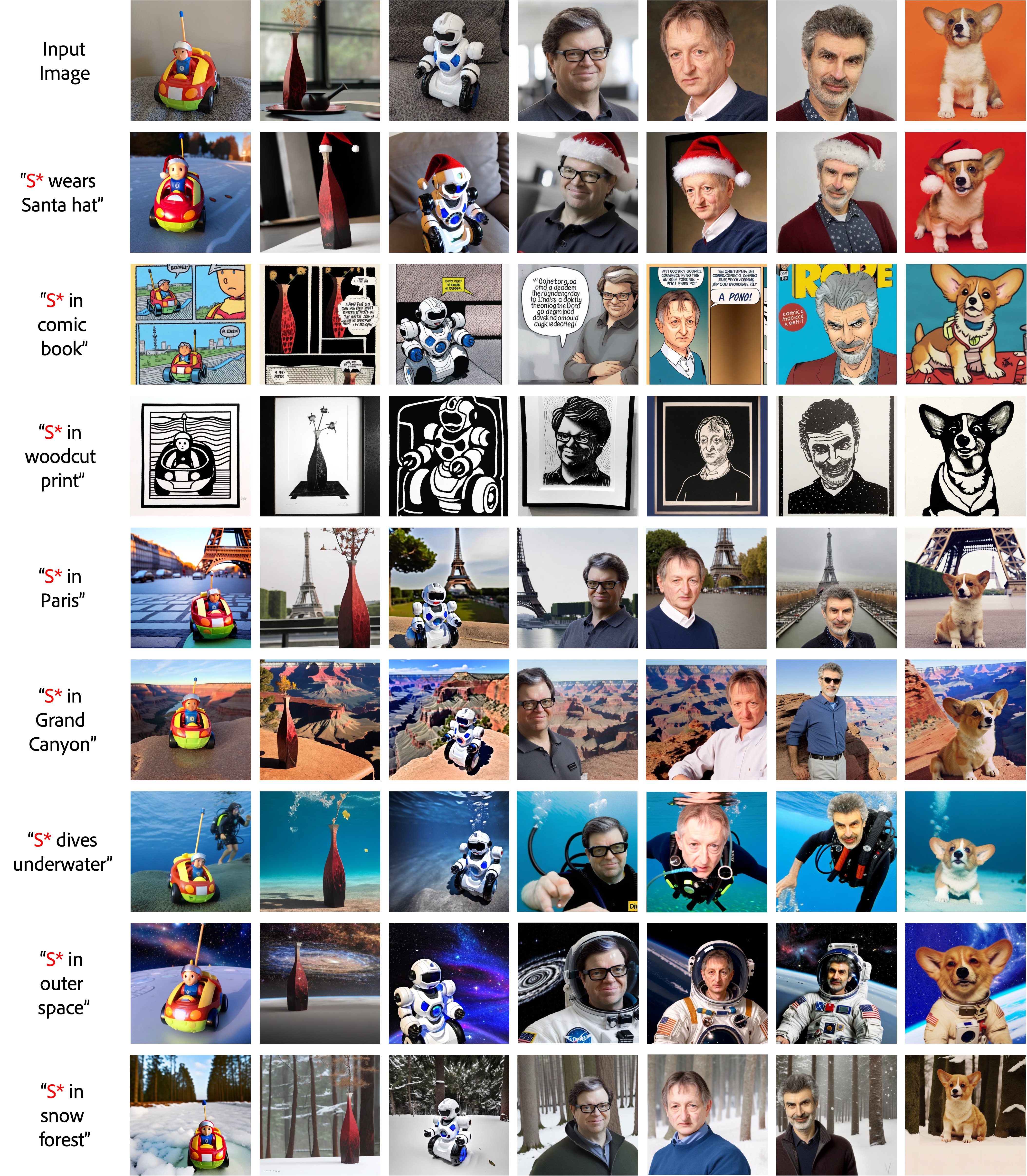
这些应用展示了ProFusion在创意设计、广告制作、电影特效等领域的巨大潜力。
技术细节与实现
ProFusion的实现主要基于Python和PyTorch深度学习框架。研究团队提供了完整的代码和预训练模型,方便其他研究者复现结果并进行进一步的研究。主要的技术细节包括:
-
基础模型选择: 使用Stable Diffusion 2作为基础的文本到图像生成模型。
-
PromptNet编码器: 采用卷积神经网络结构,将图像编码为文本提示。
-
训练策略: 使用混合精度训练和梯度检查点技术提高训练效率。
-
数据集: 提供了在FFHQ人脸数据集和CC3M大规模图像数据集上预训练的编码器。
-
推理优化: 采用多种技术提高推理速度和质量,如注意力优化等。
未来展望
ProFusion为定制化文本到图像生成开辟了新的研究方向。未来的潜在改进和应用包括:
-
多模态融合: 结合文本、音频等多种模态信息,实现更丰富的定制化生成。
-
动态适应: 开发能够快速适应新概念的在线学习算法。
-
交互式编辑: 结合人机交互技术,实现更精细的图像编辑和生成控制。
-
大规模应用: 探索在更大规模数据集和更复杂场景下的应用。
-
伦理与安全: 研究如何防止技术被滥用,保护隐私和知识产权。
结论
ProFusion代表了定制化文本到图像生成技术的一个重要进展。它不仅在技术上实现了突破,还为创意产业提供了强大的工具。随着这一技术的不断发展和完善,我们可以期待看到更多令人惊叹的应用出现在艺术创作、内容生成、虚拟现实等多个领域。
ProFusion的出现,再次证明了人工智能在视觉创意领域的无限潜力。它不仅是技术的进步,更是人类想象力的延伸。未来,随着类似ProFusion这样的技术不断涌现,人工智能与人类创造力的结合将会带来更多令人兴奋的可能性。
📚 参考资料:
- ProFusion GitHub仓库
- ProFusion论文:Enhancing Detail Preservation for Customized Text-to-Image Generation: A Regularization-Free Approach
🔗 相关链接:
ProFusion为我们展示了人工智能在视觉创意领域的巨大潜力。它不仅是一个技术突破,更是连接人类想象力和计算机视觉能力的桥梁。随着这项技术的不断发展和完善,我们可以期待看到更多令人惊叹的应用出现在艺术创作、内容生成、虚拟现实等多个领域。ProFusion的出现,为未来的视觉AI开辟了一条充满可能性的道路。









