
Prov-GigaPath: 数字病理学的革命性突破
数字病理学正处于一个激动人心的发展时期。随着生物医学数字化转型和生成式AI的迅猛发展,精准医疗的进展正在被大大加速。在这个背景下,微软研究院与普罗维登斯健康系统(Providence Health System)和华盛顿大学合作开发了Prov-GigaPath,这是一个基于真实世界数据训练的全幻灯片数字病理学基础模型,为该领域带来了革命性的突破。
数字病理学面临的挑战与机遇
数字病理学是精准医疗的重要前沿。在癌症护理中,全幻灯片成像技术已经成为常规,将显微镜下的肿瘤组织切片转化为高分辨率的数字图像。这些全幻灯片图像(Whole Slide Images, WSI)包含了解密肿瘤微环境的关键信息,对于精准免疫治疗至关重要。例如,通过分析淋巴细胞浸润情况,可以区分"热"肿瘤和"冷"肿瘤,从而指导治疗策略的制定。
然而,数字病理学也面临着独特的计算挑战。一张标准的千兆像素幻灯片在宽度和长度上都可能是典型自然图像的数千倍。传统的视觉Transformer模型难以处理如此巨大的输入,因为自注意力机制的计算复杂度会随输入长度急剧增加。因此,以往的数字病理学研究往往忽视了幻灯片中图像块之间的复杂相互依赖关系,从而错失了建模肿瘤微环境等关键应用所需的整体语境信息。
GigaPath: 创新架构实现全幻灯片建模
为了应对这一挑战,微软研究院团队开发了GigaPath,这是一种新型视觉Transformer,通过利用稀疏自注意力机制实现了全幻灯片建模,同时保持计算的可行性。
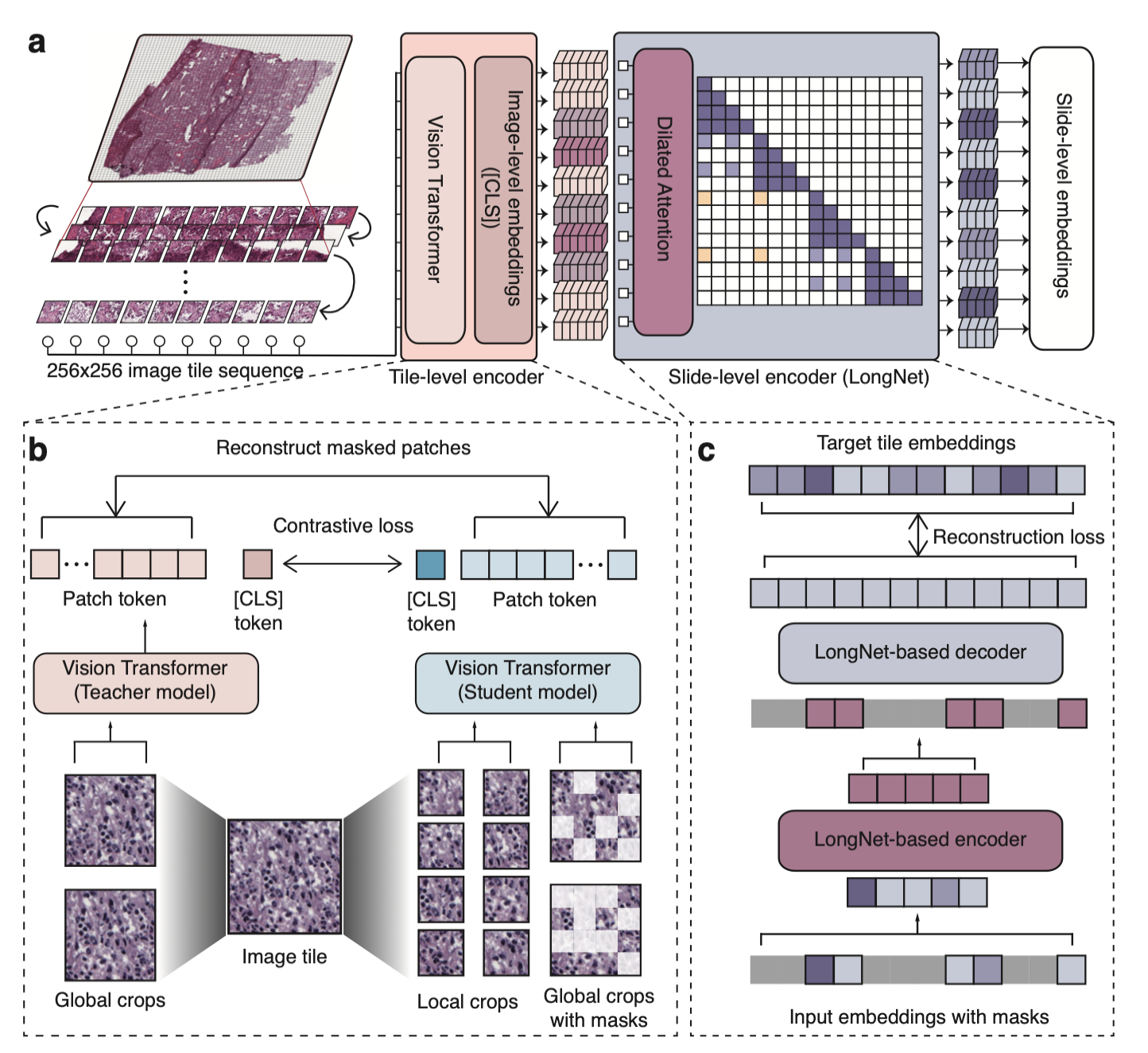
GigaPath模型架构概览
GigaPath采用了两阶段的课程学习方法:
-
图像块级预训练: 使用DINOv2自监督方法,结合对比损失和掩码重构损失来训练教师和学生视觉Transformer。
-
幻灯片级预训练: 采用基于LongNet的掩码自编码器进行预训练。
关键创新在于GigaPath对LongNet中稀疏自注意力机制的改进和适配。为了处理一张全幻灯片中大量图像块序列,GigaPath引入了一系列递增大小的分段,将图像块序列划分为给定大小的段。对于较大的段,引入稀疏注意力,稀疏度与段长成正比,从而抵消了二次增长。最大的段可以覆盖整个幻灯片,尽管采用了稀疏采样的自注意力。这使得模型能够系统地捕捉长程依赖关系,同时保持计算的可行性(与上下文长度呈线性关系)。
Prov-GigaPath: 首个基于大规模真实世界数据的全幻灯片基础模型
基于GigaPath架构,研究团队开发了Prov-GigaPath,这是首个在大规模真实世界数据上预训练的全幻灯片病理学基础模型。Prov-GigaPath在来自Providence健康系统的超过17万张全幻灯片中的10亿多个256×256像素的病理图像块上进行了预训练。所有计算都在Providence的私有租户内进行,并得到了Providence机构审查委员会(IRB)的批准。
Prov-GigaPath在标准癌症分类和病理组学任务以及视觉-语言任务上都达到了最先进的性能,展示了全幻灯片建模和大规模真实世界数据预训练的重要性,为推进患者护理和加速临床发现开辟了新的可能性。
Prov-GigaPath在癌症分类和病理组学任务中的出色表现
研究团队构建了一个数字病理学基准测试,包括9个癌症亚型分类任务和17个病理组学任务,使用了来自Providence和TCGA(癌症基因组图谱)的数据。凭借大规模预训练和全幻灯片建模的优势,Prov-GigaPath在26个任务中的25个上达到了最先进的性能,在18个任务中显著优于第二好的模型。
癌症亚型分类
在癌症亚型分类任务中,模型需要基于病理学幻灯片对癌症的细粒度亚型进行分类。例如,对于卵巢癌,模型需要区分六种亚型:透明细胞卵巢癌、子宫内膜样卵巢癌、高级别浆液性卵巢癌、低级别浆液性卵巢癌、黏液性卵巢癌和卵巢癌肉瘤。
Prov-GigaPath在全部9个任务中都达到了最先进的性能,在其中6个任务中显著优于第二好的模型。对于6种癌症类型(乳腺、肾脏、肝脏、脑、卵巢、中枢神经系统),Prov-GigaPath的AUROC(受试者工作特征曲线下面积)达到了90%或更高。这为癌症诊断和预后等精准医疗下游应用奠定了良好基础。
基因突变预测
在病理组学任务中,目标是仅基于幻灯片图像来判断肿瘤是否表现出特定的临床相关基因突变。这可能揭示出组织形态和遗传通路之间微妙的、人类观察难以捕捉的有意义联系。
除了少数几对已知的特定癌症类型和基因突变组合外,仅从幻灯片中能获取多少信号尚不清楚。此外,在一些实验中,研究团队考虑了泛癌症场景,试图在所有癌症类型和多样化的肿瘤形态中识别某个基因突变的普遍信号。
在如此具有挑战性的场景下,Prov-GigaPath再次在18个任务中的17个上达到了最先进的性能,在12个任务中显著优于第二好的模型。例如,在泛癌症5基因分析中,Prov-GigaPath在AUROC上超过最佳对比方法6.5%,在AUPRC(精确率-召回率曲线下面积)上超过18.7%。
研究团队还在TCGA数据上进行了直接比较,以评估Prov-GigaPath的泛化能力,发现Prov-GigaPath同样优于所有对比方法。考虑到对比方法都是在TCGA上预训练的,这一结果更加令人印象深刻。
Prov-GigaPath能够在全幻灯片层面提取与基因相关的泛癌症和亚型特异性形态特征,凸显了其学习的嵌入表示的生物学相关性,为未来围绕复杂肿瘤微环境生物学的研究方向开辟了新的道路。
Prov-GigaPath在视觉-语言任务中的潜力
研究团队通过整合病理报告,进一步展示了GigaPath在视觉-语言任务中的潜力。以往的病理学视觉-语言预训练工作往往集中在图像块级别的小图像上。相比之下,本研究探索了幻灯片级别的视觉-语言预训练。
通过在幻灯片-报告对上继续预训练,研究团队可以利用报告语义来对齐病理幻灯片表示,这可以用于下游预测任务,而无需监督微调(例如,零样本亚型分类)。具体而言,研究团队使用Prov-GigaPath作为全幻灯片图像编码器,使用PubMedBERT作为文本编码器,并使用幻灯片-报告对进行对比学习。
这比传统的视觉-语言预训练要具有挑战性得多,因为研究团队没有单个图像块和文本片段之间的细粒度对齐信息。尽管如此,Prov-GigaPath在标准视觉-语言任务(如零样本癌症亚型分类和基因突变预测)中仍然大大优于三个最先进的病理学视觉-语言模型,展示了Prov-GigaPath在全幻灯片视觉-语言建模中的潜力。
GigaPath: 迈向精准医疗多模态生成式AI的重要一步
研究团队进行了全面的消融研究,以建立全幻灯片预训练和视觉-语言建模的最佳实践。他们还观察到数字病理学中存在规模定律的早期迹象,即更大规模的预训练通常会改善下游性能,尽管由于计算限制,实验规模仍然有限。
展望未来,还有许多进步的机会:
-
尽管Prov-GigaPath相对于先前的最佳模型达到了最先进的性能,但在许多下游任务中仍有显著的增长空间。
-
虽然研究团队已经对病理学视觉-语言预训练进行了初步探索,但在追求多模态对话助手的潜力方面还有很长的路要走,特别是通过整合诸如LLaVA-Med等先进的多模态框架。
-
最重要的是,研究团队还没有探索GigaPath和全幻灯片预训练在许多关键精准医疗任务中的影响,如建模肿瘤微环境和预测治疗反应。
GigaPath反映了微软在推进精准医疗多模态生成式AI方面的更大承诺,在其他数字病理学研究合作中也取得了令人兴奋的进展,如Cyted、Volastra和Paige,以及其他技术进步,如BiomedCLIP、LLaVA-Rad、BiomedJourney、BiomedParse、MAIRA、Rad-DINO和Virchow。
结语
Prov-GigaPath作为首个基于大规模真实世界数据训练的全幻灯片数字病理学基础模型,为该领域带来了革命性的突破。它不仅在癌症分类、病理组学和视觉-语言任务上展现了卓越性能,更为精准医疗和临床发现开辟了新的可能性。随着技术的不断进步和更多数据的积累,我们有理由相信,基于AI的数字病理学将在未来的医疗实践中发挥越来越重要的作用,为患者带来更精准、更个性化的诊疗方案。









