
PyLabel:计算机视觉数据集准备的瑞士军刀
在计算机视觉领域,高质量的训练数据集是模型性能的关键。然而,准备和处理这些数据集往往是一项繁琐而耗时的工作。PyLabel应运而生,它是一个专为简化这一过程而设计的Python库,为研究人员和开发者提供了一套强大而灵活的工具。
多功能的数据处理利器
PyLabel的核心功能是在不同的边界框标注格式之间进行转换。无论您使用的是COCO、YOLO还是VOC格式,PyLabel都能轻松应对。例如,只需一行代码即可将COCO格式转换为YOLO格式:
importer.ImportCoco(path_to_annotations).export.ExportToYoloV5()
这种简单而强大的功能大大减少了数据准备阶段的工作量,让研究人员可以将更多精力集中在模型开发和优化上。
深入分析数据集
PyLabel不仅仅是一个格式转换工具。它将标注数据存储在pandas DataFrame中,这为数据分析提供了极大的便利。研究人员可以轻松地对数据集进行统计分析,了解类别分布,检查异常值,或者进行其他自定义分析。这种深入洞察数据的能力对于优化数据集质量和模型性能至关重要。
智能的数据集分割
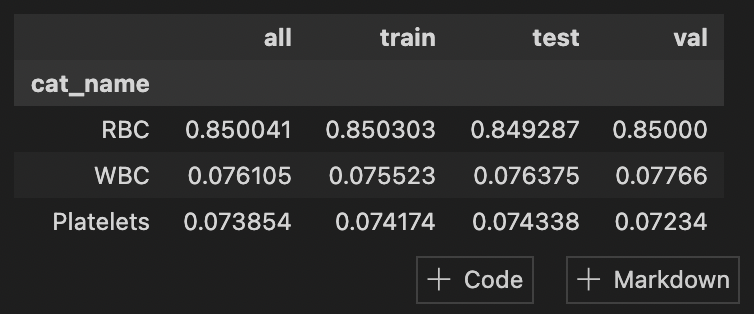
在机器学习项目中,合理地将数据集分割为训练集、测试集和验证集是一个关键步骤。PyLabel提供了智能的数据集分割功能,不仅可以按照指定比例分割数据,还能保证各个子集中类别分布的一致性。这种分层抽样的方法确保了模型在各个阶段都能接触到全面的数据分布,有助于提高模型的泛化能力。
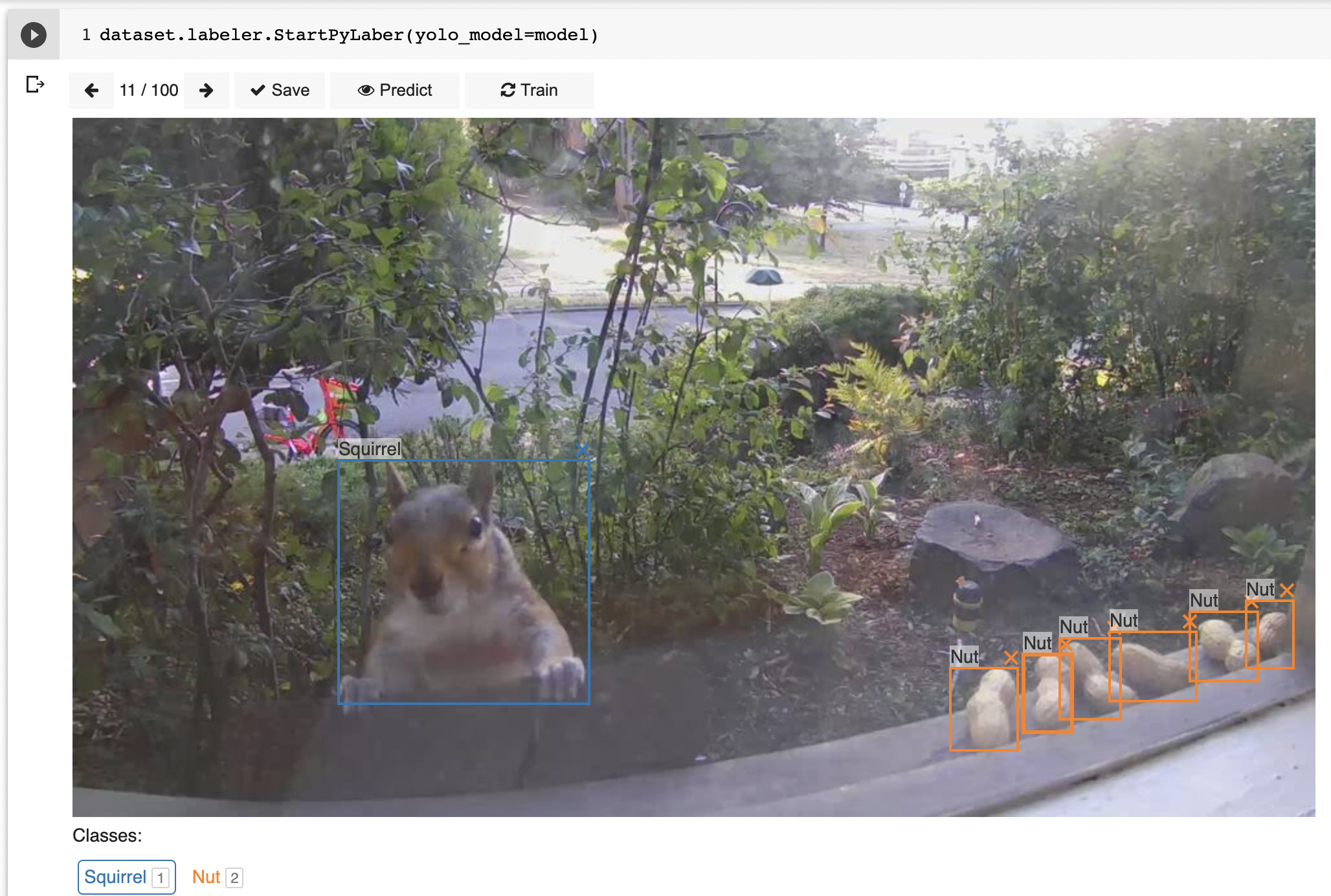
AI辅助的图像标注工具
PyLabel的另一大亮点是其内置的图像标注工具。这个工具运行在Jupyter notebook环境中,支持手动标注和AI辅助自动标注两种模式。AI辅助模式利用预训练模型进行初步标注,大大提高了标注效率。研究人员可以在此基础上进行微调和修正,极大地加速了数据标注过程。
直观的数据可视化
为了帮助研究人员更好地理解和验证数据集,PyLabel提供了强大的可视化功能。用户可以轻松地将边界框叠加到原始图像上,直观地检查标注的准确性。这个功能不仅有助于质量控制,也为展示和解释模型结果提供了便利。
丰富的教程资源
PyLabel项目非常注重用户体验,提供了一系列详细的Jupyter notebook教程,涵盖了从基本的格式转换到高级功能的各个方面。这些教程包括:
- COCO转YOLO格式
- COCO转VOC格式
- VOC转COCO格式
- YOLO转COCO格式
- YOLO转VOC格式
- 导入YOLO YAML文件
- 数据集分割
- AI辅助标注工具演示
这些教程不仅是使用PyLabel的指南,也是学习计算机视觉数据处理最佳实践的宝贵资源。
开源社区的力量
PyLabel是一个开源项目,由Jeremy Fraenkel、Alex Heaton和Derek Topper在UC Berkeley信息学院攻读信息与数据科学硕士学位期间开发。项目积极欢迎社区贡献,鼓励用户反馈问题和建议。这种开放的态度确保了PyLabel能够持续改进,满足研究人员和开发者不断变化的需求。
应用场景广泛
PyLabel的应用场景非常广泛,包括但不限于:
- 学术研究:研究人员可以快速准备和分析实验数据集。
- 工业应用:企业可以利用PyLabel优化其计算机视觉项目的数据流程。
- 竞赛准备:数据科学竞赛参与者可以使用PyLabel快速处理和分析比赛数据集。
- 教育培训:PyLabel可以作为计算机视觉课程的实践工具,帮助学生理解数据处理流程。
未来展望
随着计算机视觉技术的不断发展,数据集的规模和复杂性也在不断增加。PyLabel团队正在积极开发新功能,以应对这些挑战。未来的版本可能会包括:
- 支持更多标注格式
- 集成更先进的AI辅助标注算法
- 增强的数据增强功能
- 更深入的数据分析工具
- 与其他流行的机器学习框架的更好集成
结语
PyLabel为计算机视觉研究人员和开发者提供了一个强大而灵活的工具集,极大地简化了数据集准备和管理的过程。无论您是刚刚入门的学生,还是经验丰富的研究员,PyLabel都能为您的项目带来显著的效率提升。随着项目的不断发展和社区的积极参与,PyLabel必将在计算机视觉领域发挥越来越重要的作用。
如果您正在从事计算机视觉相关工作,不妨尝试使用PyLabel,体验它带来的便利。您可以通过GitHub仓库了解更多信息,或者直接通过pip安装使用:
pip install pylabel
让我们一起期待PyLabel的更多创新,推动计算机视觉技术的进步! 🚀👁️🔬









