
扩散模型在强化学习中的应用:前沿与展望
强化学习(Reinforcement Learning, RL)是人工智能领域的重要分支,近年来在游戏、机器人控制等领域取得了显著进展。然而,传统强化学习方法仍面临着样本效率低、长期规划能力不足等挑战。近期,将扩散模型(Diffusion Model)引入强化学习中成为了一个新的研究热点,为解决这些问题提供了新的思路。本文将全面介绍基于扩散模型的强化学习(Diffusion Model in RL)的最新研究进展。
扩散模型在强化学习中的应用原理
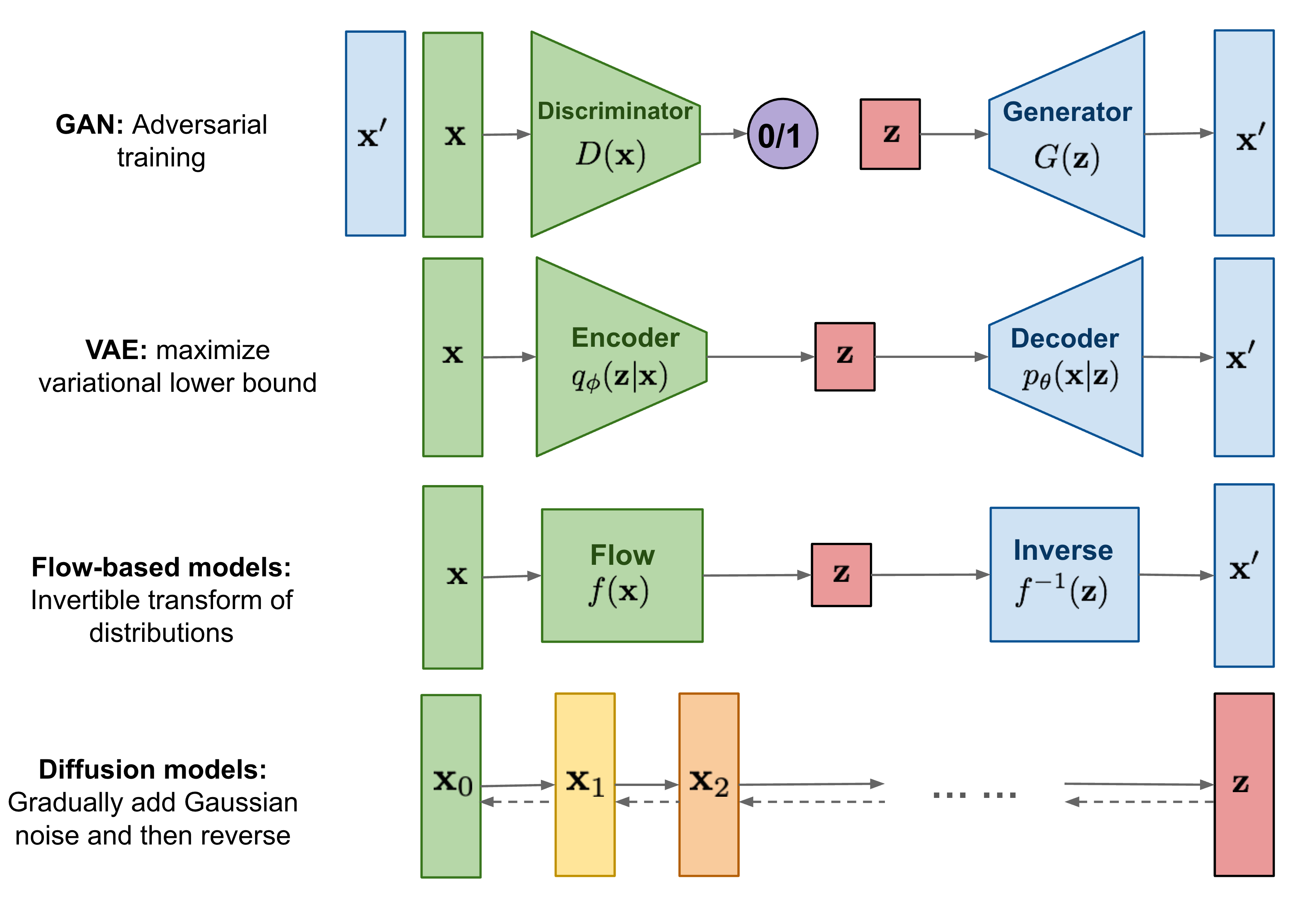
扩散模型最初被提出用于生成高质量图像,其核心思想是通过逐步去噪的方式生成数据。将扩散模型引入强化学习领域的开创性工作是Janner等人发表的"Planning with Diffusion for Flexible Behavior Synthesis"。该工作将轨迹优化问题建模为一个扩散概率模型,通过迭代细化轨迹来实现规划。
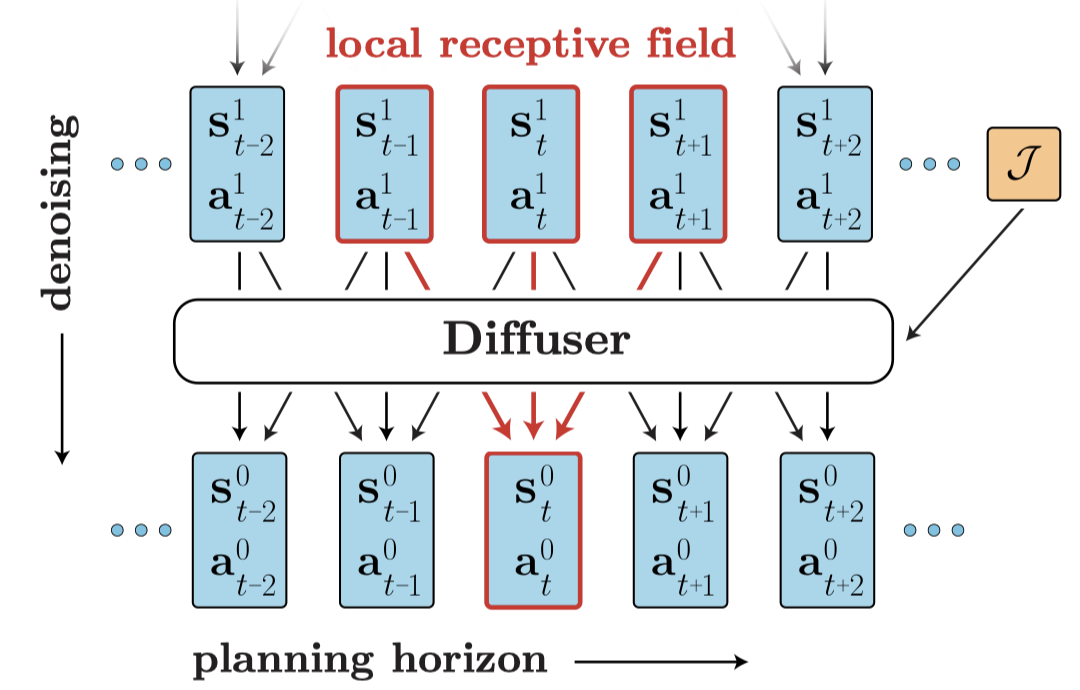
另一种将扩散模型应用于强化学习的方式是将其作为策略优化的工具。Wang等人提出的Diffusion-QL方法将策略建模为一个以状态为条件的扩散模型,从离线策略优化的角度来解决强化学习问题。
基于扩散模型的强化学习方法的主要优势
-
绕过了长期信用分配问题:传统强化学习方法需要通过TD学习等方式解决长期信用分配问题,而基于扩散模型的方法可以直接生成完整轨迹,避免了这个难题。
-
避免了因折扣未来奖励导致的短视行为:传统方法中的折扣因子可能导致智能体过于关注短期奖励,而忽视长期目标。扩散模型可以生成更长期的行为序列,有助于实现更好的长期规划。
-
易于扩展和迁移:扩散模型在计算机视觉和自然语言处理等领域已经取得了巨大成功,将其引入强化学习可以借鉴这些领域的成熟技术,更容易实现大规模和多模态数据的处理。
代表性工作综述
1. 离线强化学习
离线强化学习是近年来强化学习研究的热点方向之一,基于扩散模型的方法在这一领域展现出了巨大潜力。
- Zhendong Wang等人提出的Diffusion-QL方法将策略建模为条件扩散模型,有效提高了离线强化学习的性能。
- Bingyi Kang等人的工作进一步改进了扩散模型在离线强化学习中的计算效率,使其更加实用。
- Huayu Chen等人提出的SfBC方法通过高保真的生成行为建模来解决离线强化学习问题,取得了优异的效果。
2. 分层强化学习
分层强化学习旨在通过分层的方式解决长期规划问题,扩散模型为这一方向提供了新的思路。
- Wenhao Li等人提出的HDMI方法将扩散模型应用于分层离线决策制定,有效解决了长期任务规划问题。
- Chang Chen等人的工作进一步简化了基于扩散模型的分层规划方法,提高了其实用性。
3. 机器人控制
扩散模型在机器人控制领域也展现出了巨大潜力,特别是在视觉驱动的机器人操作任务中。
- Cheng Chi等人提出的Diffusion Policy方法将扩散模型应用于视觉-运动控制策略学习,在多个机器人操作任务中取得了优异效果。
- Xiao Ma等人进一步将分层扩散策略应用于多任务机器人操控,提高了长期任务规划能力。
4. 多智能体强化学习
将扩散模型引入多智能体强化学习也是一个新兴的研究方向。
- Zhengbang Zhu等人提出的MADiff方法将扩散模型应用于离线多智能体学习,有效提高了多智能体系统的性能。
未来发展方向
-
提高计算效率:虽然扩散模型在强化学习中展现出了巨大潜力,但其计算成本仍然较高。如何提高扩散模型在强化学习中的计算效率是一个重要的研究方向。
-
结合其他先进技术:将扩散模型与大型语言模型、世界模型等其他先进技术相结合,可能会产生更加强大的强化学习算法。
-
解决实际问题:目前基于扩散模型的强化学习方法主要在仿真环境中进行测试,如何将其应用于解决实际问题(如自动驾驶、机器人控制等)是未来的重要方向。
-
理论分析:对基于扩散模型的强化学习方法进行深入的理论分析,包括收敛性、样本复杂度等方面,将有助于更好地理解和改进这类方法。
-
安全性和鲁棒性:随着强化学习算法在现实世界中的应用日益广泛,如何保证基于扩散模型的强化学习方法的安全性和鲁棒性也是一个值得关注的问题。
结语
基于扩散模型的强化学习方法为解决强化学习中的长期规划、样本效率等问题提供了新的思路,展现出了巨大的潜力。随着研究的深入,我们有理由相信这一方向将为强化学习领域带来更多突破性进展,推动人工智能技术向更高水平发展。
欢迎对这一领域感兴趣的研究者关注awesome-diffusion-model-in-rl项目,该项目持续追踪和更新基于扩散模型的强化学习最新研究进展。让我们共同期待这一激动人心的研究方向的未来发展!












