
RLeXplore:加速内在驱动的强化学习研究
在强化学习领域,探索是一个核心问题。如何在复杂的环境中有效地探索和学习,一直是研究者们关注的重点。近年来,内在驱动的强化学习方法受到了广泛关注,这类方法通过设计内在奖励来鼓励智能体进行探索。然而,由于不同的实现、优化策略和评估方法等因素的影响,比较不同的内在奖励算法一直是一个挑战。为了解决这个问题,RLeXplore应运而生。
RLeXplore简介
RLeXplore是一个统一的、高度模块化和即插即用的工具包,目前提供了8种代表性内在奖励算法的高质量可靠实现。它的设计目标是为构建、计算和优化内在奖励模块提供统一和标准化的程序。
RLeXplore的工作流程如下图所示:
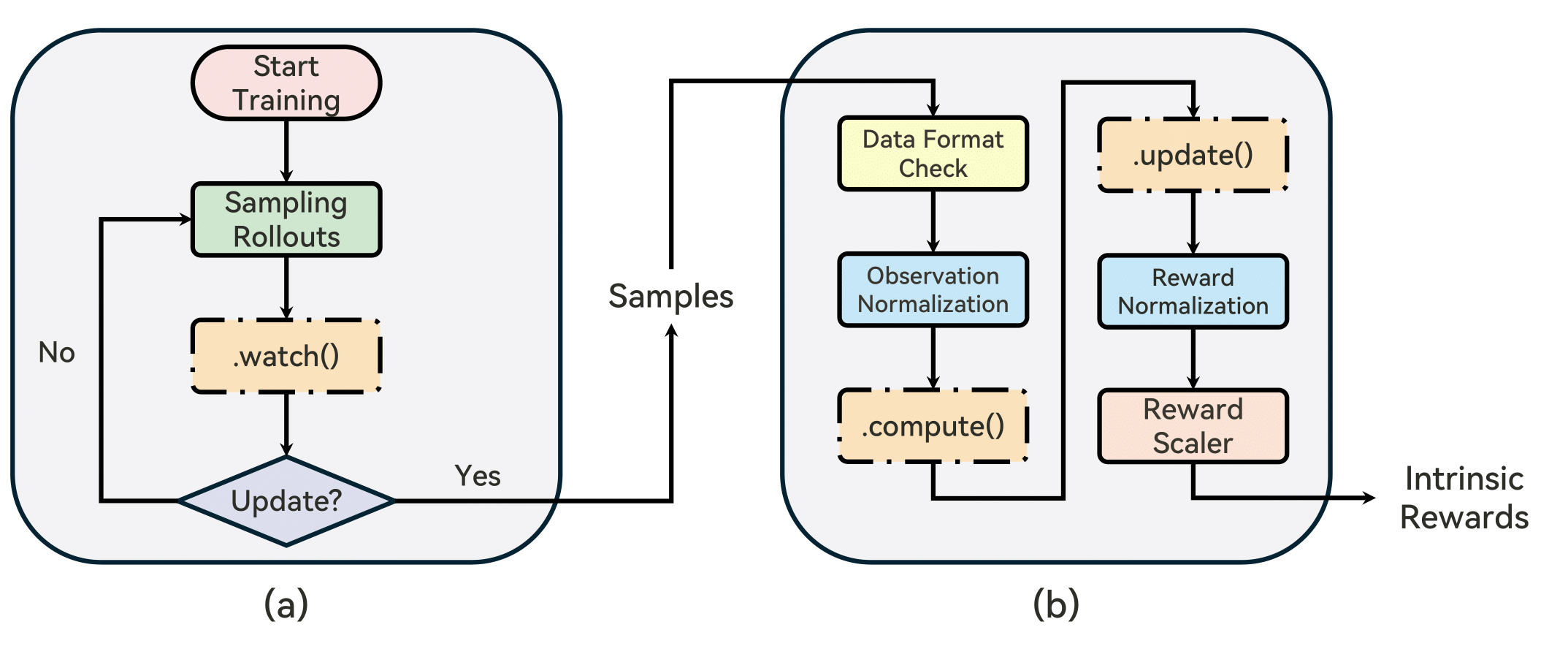
从图中可以看出,RLeXplore提供了一个完整的工作流程,包括环境交互、数据收集、内在奖励计算和策略优化等步骤。这种统一的框架使得研究者可以更容易地比较和分析不同的内在奖励算法。
RLeXplore的主要特点
- 统一性: RLeXplore提供了统一的接口和标准化的程序,使得不同的内在奖励算法可以在相同的环境和条件下进行比较。
- 模块化: 工具包采用高度模块化的设计,使得用户可以轻松地替换或添加新的内在奖励模块。
- 即插即用: RLeXplore可以与多种主流的强化学习库兼容,如Stable Baselines3、CleanRL等,实现即插即用。
- 高质量实现: 工具包提供了8种代表性内在奖励算法的高质量实现,确保了实验结果的可靠性。
- 丰富的教程: RLeXplore提供了详细的教程和示例,帮助用户快速上手和使用。
支持的内在奖励算法
RLeXplore目前支持以下几类内在奖励算法:
- 基于计数的方法:
- PseudoCounts
- 随机网络蒸馏(RND)
- E3B
- 基于好奇心的方法:
- 内在好奇心模块(ICM)
- Disagreement
- 奖励影响驱动探索(RIDE)
- 基于记忆的方法:
- NGU (Never Give Up)
- 基于信息理论的方法:
- RE3
这些算法覆盖了内在驱动强化学习的多个重要方向,为研究者提供了丰富的选择。
安装和使用
RLeXplore的安装非常简单,用户可以通过pip直接安装:
conda create -n rllte python=3.8
pip install rllte-core
安装完成后,用户可以通过以下方式导入内在奖励模块:
from rllte.xplore.reward import ICM, RIDE, ...
教程和示例
RLeXplore提供了一系列教程和示例,帮助用户快速上手:
这些教程涵盖了从基础使用到高级应用的多个方面,能够满足不同层次用户的需求。
基准测试结果
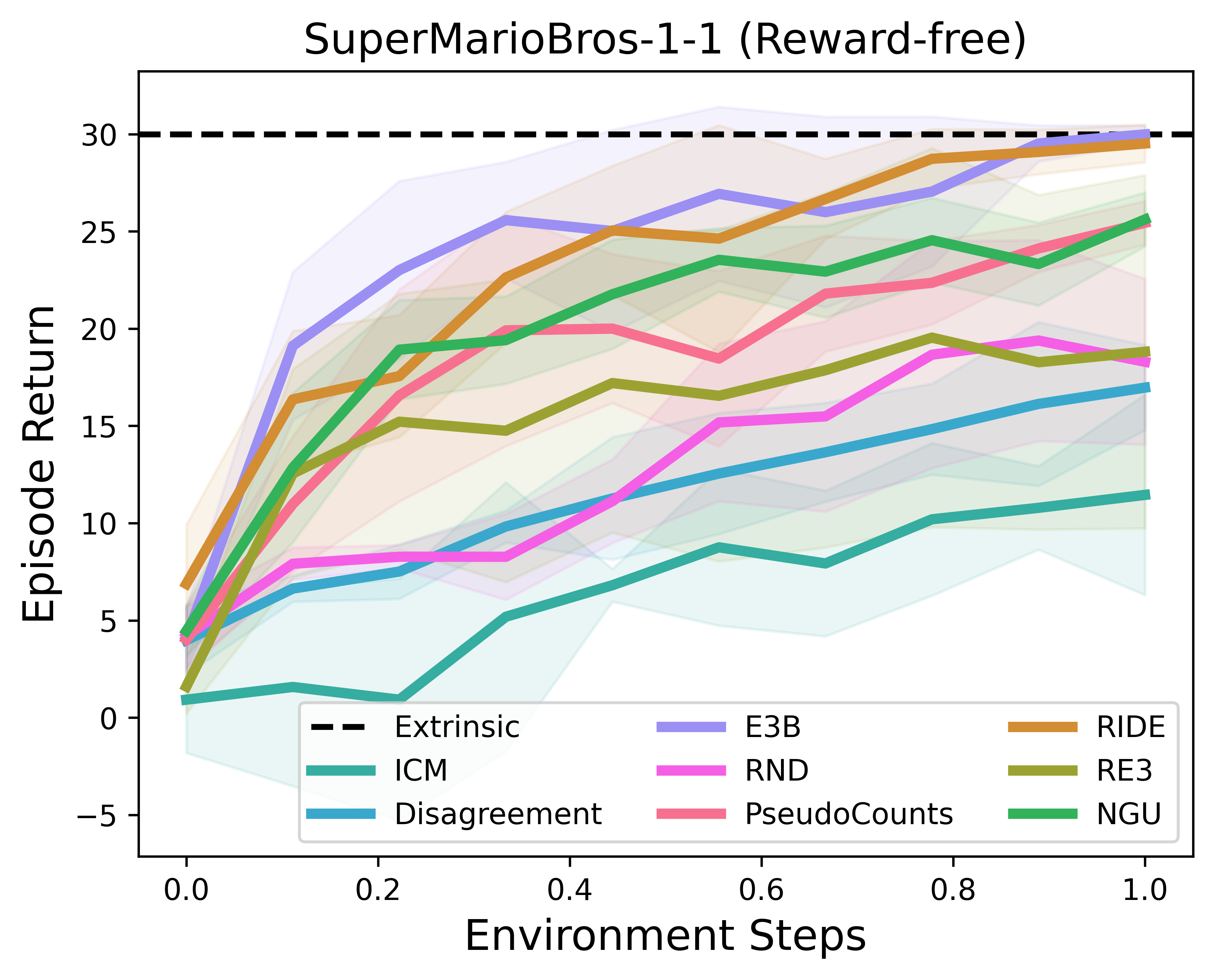
RLeXplore在多个经典环境中进行了基准测试,展示了其性能优势。以下是两个典型的测试结果:
- RLLTE's PPO+RLeXplore在SuperMarioBros环境中的表现:
- CleanRL's PPO+RLeXplore's RND在Montezuma's Revenge环境中的表现:
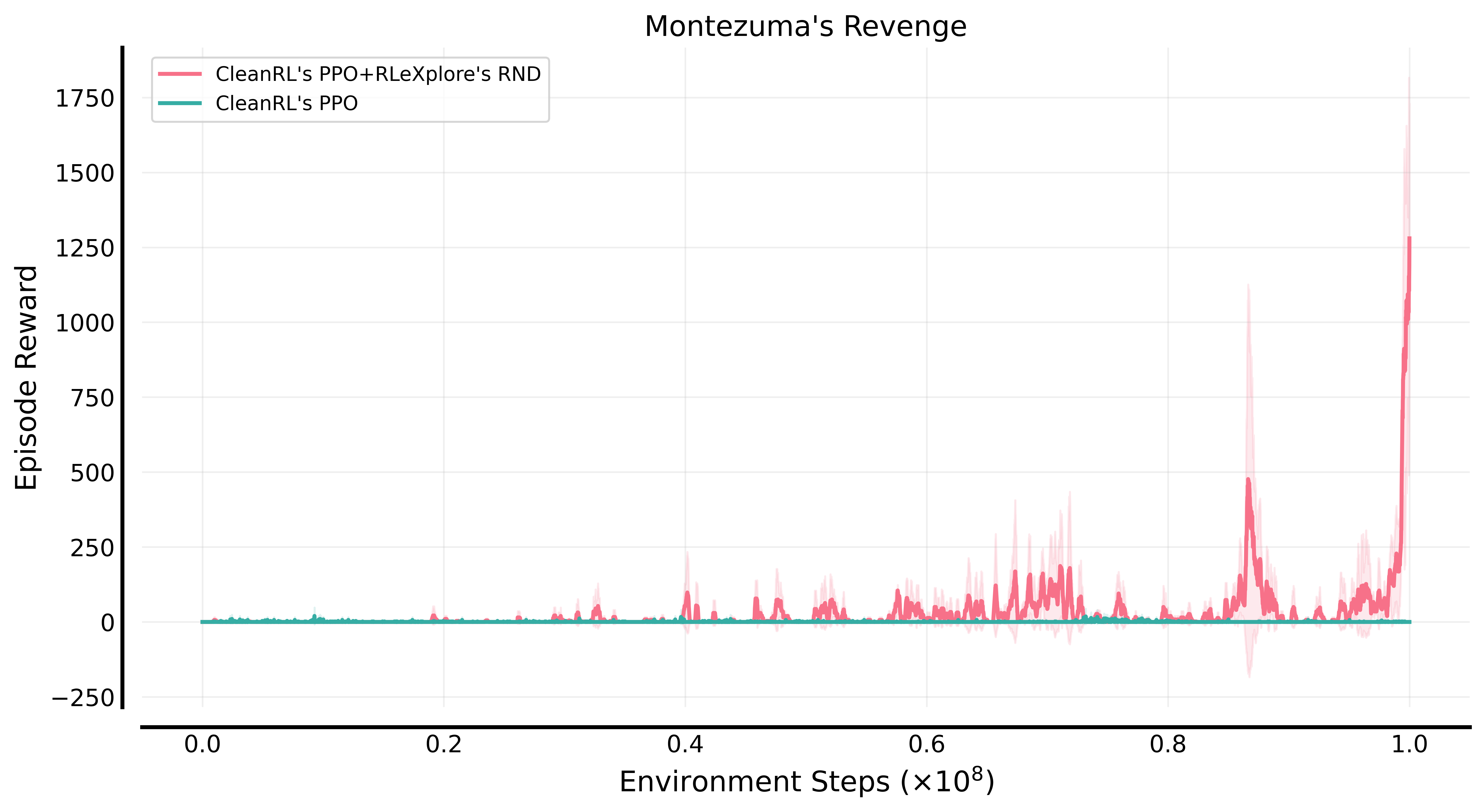
这些结果显示,RLeXplore在这些具有挑战性的环境中表现出色,证明了其有效性和实用性。
RLeXplore的意义和影响
RLeXplore的出现对内在驱动的强化学习研究具有重要意义:
- 促进算法比较: 通过提供统一的实现和评估框架,RLeXplore使得不同内在奖励算法的比较更加公平和可靠。
- 加速研究进程: 高质量的算法实现和丰富的教程资源,大大降低了研究者的入门门槛,加速了相关研究的进展。
- 推动标准化: RLeXplore的设计理念和实践为内在驱动强化学习的标准化提供了有益探索。
- 促进社区协作: 作为一个开源项目,RLeXplore为研究者提供了一个共同的平台,促进了知识共享和协作。
未来展望
虽然RLeXplore已经提供了丰富的功能,但仍有很大的发展空间:
- 扩展算法库: 随着研究的深入,可以持续添加新的内在奖励算法,保持工具包的先进性。
- 优化性能: 进一步优化算法实现,提高计算效率,特别是在大规模环境中的表现。
- 增强可视化: 开发更多直观的可视化工具,帮助研究者更好地理解和分析算法行为。
- 跨平台支持: 扩展对更多强化学习平台和框架的支持,增强通用性。
- 应用拓展: 探索RLeXplore在更多实际应用场景中的潜力,如机器人控制、自动驾驶等领域。
结语
RLeXplore作为一个专注于内在驱动强化学习的工具包,为这一重要研究方向提供了强有力的支持。它不仅简化了算法实现和比较的过程,还为研究者提供了一个共同的平台,促进了知识的交流和创新的产生。随着RLeXplore的不断发展和完善,我们有理由相信,它将在推动内在驱动强化学习研究方面发挥越来越重要的作用,为人工智能领域的进步做出重要贡献。
如何参与贡献
RLeXplore是一个开源项目,欢迎社区成员参与贡献。您可以通过以下方式参与:
- 提交问题和建议: 在GitHub仓库的Issues页面提交bug报告或功能建议。
- 贡献代码: 通过Pull Request提交代码改进或新功能实现。
- 改进文档: 帮助完善项目文档,包括教程、API文档等。
- 分享经验: 在社区中分享您使用RLeXplore的经验和见解。
引用RLeXplore
如果您在研究中使用了RLeXplore,请引用以下文献:
@article{yuan_roger2024rlexplore,
title={RLeXplore: Accelerating Research in Intrinsically-Motivated Reinforcement Learning},
author={Yuan, Mingqi and Castanyer, Roger Creus and Li, Bo and Jin, Xin and Berseth, Glen and Zeng, Wenjun},
journal={arXiv preprint arXiv:2405.19548},
year={2024}
}
通过引用,您不仅可以支持RLeXplore项目的发展,还能帮助其他研究者了解和使用这个有价值的工具。
总之,RLeXplore为内在驱动的强化学习研究提供了一个强大而灵活的工具包。无论您是该领域的资深研究者还是刚刚入门的学生,RLeXplore都能为您的研究提供宝贵的支持。让我们共同期待RLeXplore在未来带来更多激动人心的突破和创新! 🚀🤖









