
RNNoise简介
RNNoise是由Xiph.Org基金会开发的一个开源音频降噪库,它基于递归神经网络(RNN)技术,能够实现实时、高效的音频降噪。RNNoise的主要特点包括:
- 结合传统信号处理和深度学习技术
- 计算量小,可在普通CPU上实时运行
- 模型文件小,仅需85KB存储空间
- 开源免费,可自由使用和二次开发
RNNoise的核心思想是使用深度学习的方法来解决传统音频降噪中需要大量人工调优的问题,从而实现更好的降噪效果和更高的鲁棒性。
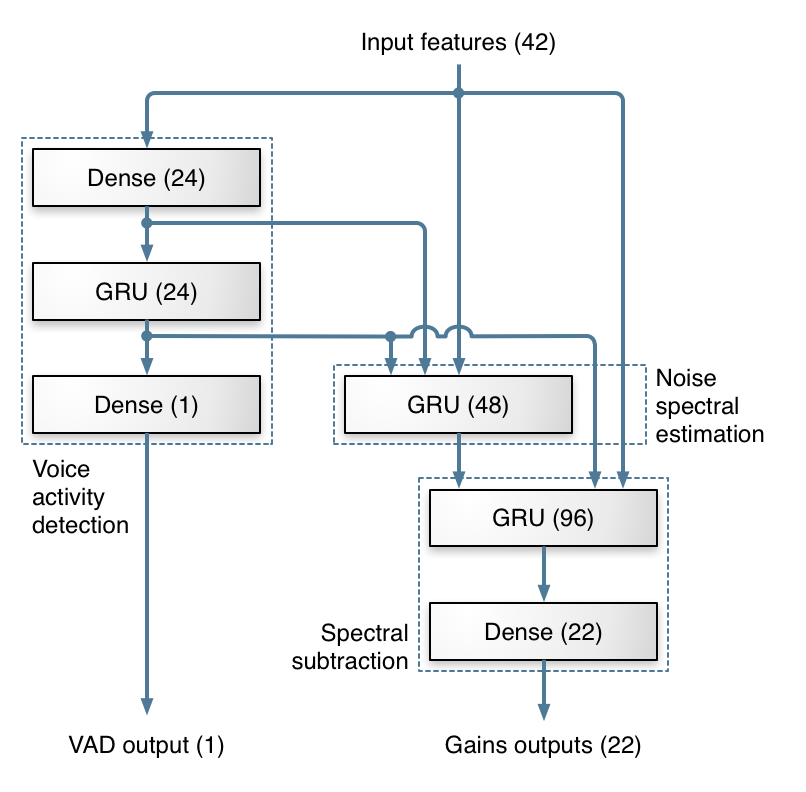
工作原理
混合架构
RNNoise采用了一种混合架构,将传统的信号处理技术与深度学习方法相结合。这种方法保留了信号处理的基本操作,同时利用神经网络来学习复杂的噪声特征和降噪策略。
具体来说,RNNoise的处理流程包括:
- 使用短时傅里叶变换(STFT)将音频信号转换到频域
- 利用神经网络估计每个频带的增益
- 将估计的增益应用到原始频谱上
- 通过逆短时傅里叶变换(ISTFT)将处理后的频谱转换回时域
这种混合方法既保留了传统信号处理的优势,又充分发挥了深度学习的强大能力。
神经网络结构
RNNoise使用的神经网络主要由三层门控循环单元(GRU)组成。GRU是一种特殊的循环神经网络单元,能够有效地学习长期依赖关系。网络的输入特征包括:
- 22个频带的倒谱系数
- 前6个系数的一阶和二阶时间导数
- 基音周期和基音增益
- 非平稳性特征
网络的输出是22个频带的增益值,用于抑制噪声。
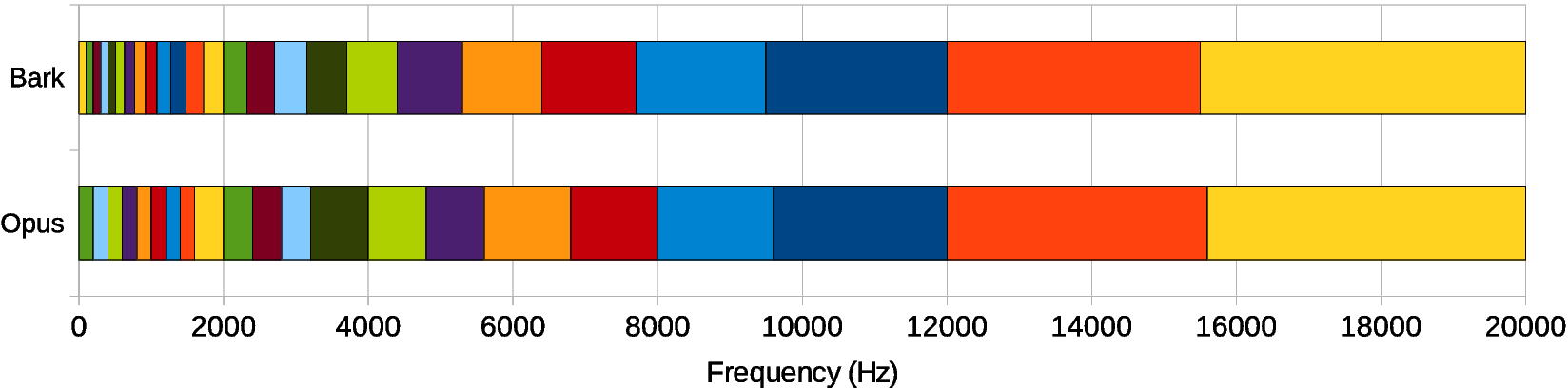
频带划分
RNNoise使用22个频带来表示音频信号,这些频带基于Bark尺度划分,与人耳的感知特性相匹配。使用频带而不是直接处理频谱的好处包括:
- 降低了模型的复杂度
- 避免了"音乐噪声"等典型的降噪伪影
- 使得增益值的约束更加容易
基音滤波
为了进一步提高降噪效果,RNNoise还使用了基音滤波技术。这种方法利用语音的周期性特征,在时域上对信号进行梳状滤波,从而在保留语音谐波的同时抑制谐波之间的噪声。
训练过程
RNNoise的训练数据由干净的语音样本和各种噪声样本人工合成。训练过程包括以下步骤:
- 准备干净的语音数据和噪声数据
- 将语音和噪声按不同的信噪比混合,模拟真实场景
- 提取特征并生成训练数据
- 使用Python和Keras库训练神经网络
- 将训练好的模型转换为C语言代码
为了提高模型的泛化能力,训练数据包含了各种类型的噪声和不同的录音环境。
应用场景
RNNoise可以应用于多种需要实时音频降噪的场景,包括但不限于:
- 网络语音通话和视频会议
- 语音识别前的预处理
- 录音设备的实时降噪
- 游戏语音聊天
- 播客和视频制作
由于RNNoise的计算量小,它甚至可以在树莓派等嵌入式设备上运行,为各种便携设备提供实时降噪功能。
性能评估
根据开发者的测试,RNNoise在x86 CPU上可以实现60倍于实时的处理速度,在树莓派3上也能达到7倍于实时的速度。通过适当的向量化优化,还有进一步提升性能的空间。
在降噪效果方面,RNNoise能够有效地抑制各种类型的背景噪声,包括办公室环境噪声、交通噪声、键盘声等。虽然RNNoise主要目标是提高音频质量而非提高语音可懂度,但在某些情况下(如多人会议或低比特率编码)也能间接提高语音的可懂度。
开源社区
作为一个开源项目,RNNoise得到了广泛的关注和支持。许多开发者和公司已经将RNNoise集成到他们的产品中,例如:
- OBS Studio: 流行的直播和录屏软件
- PulseEffects: Linux下的音频效果器
- Discord: 知名的游戏语音通讯软件
社区还开发了various的RNNoise插件和独立应用,使其能够更方便地在不同平台和场景下使用。
未来展望
RNNoise项目仍在持续发展中,未来可能的改进方向包括:
- 开发针对特定场景优化的模型
- 结合其他深度学习技术,如注意力机制
- 探索多通道降噪的可能性
- 提供更多可定制选项,适应不同的应用需求
此外,RNNoise的技术也可能被应用到其他音频处理任务中,如音乐降噪、声音分离等领域。
结语
RNNoise代表了音频降噪技术的一个重要发展方向,它展示了如何将深度学习技术与传统信号处理方法相结合,以解决实际工程问题。作为一个开源项目,RNNoise不仅提供了高效的降噪解决方案,也为研究人员和开发者提供了一个探索和创新的平台。随着技术的不断进步和应用范围的扩大,我们可以期待看到更多基于RNNoise的创新应用出现。









