
ScreenAgent: 视觉语言模型驱动的计算机控制代理

ScreenAgent是一个创新性的项目,旨在构建一个环境,让视觉语言模型(VLM)代理能够与真实的计算机屏幕进行交互。在这个环境中,AI代理可以观察屏幕截图,并通过输出鼠标和键盘操作来操控图形用户界面(GUI)。这一突破性的研究为构建更通用的AI助手开辟了新的可能性,有望在各种日常数字工作中为人类提供帮助。
项目概述
ScreenAgent项目的核心包括以下几个关键组成部分:
-
交互环境: 创建了一个环境,允许VLM代理与真实计算机屏幕交互。
-
自动控制流程: 设计了一个包含规划、执行和反思阶段的自动控制流程,指导代理持续与环境交互并完成多步骤任务。
-
ScreenAgent数据集: 构建了一个包含完成各种日常计算机任务时的屏幕截图和操作序列的数据集。
-
ScreenAgent模型: 基于收集的数据训练了一个模型,实现了与GPT-4V相当的计算机控制能力,并展示了更精确的UI定位能力。
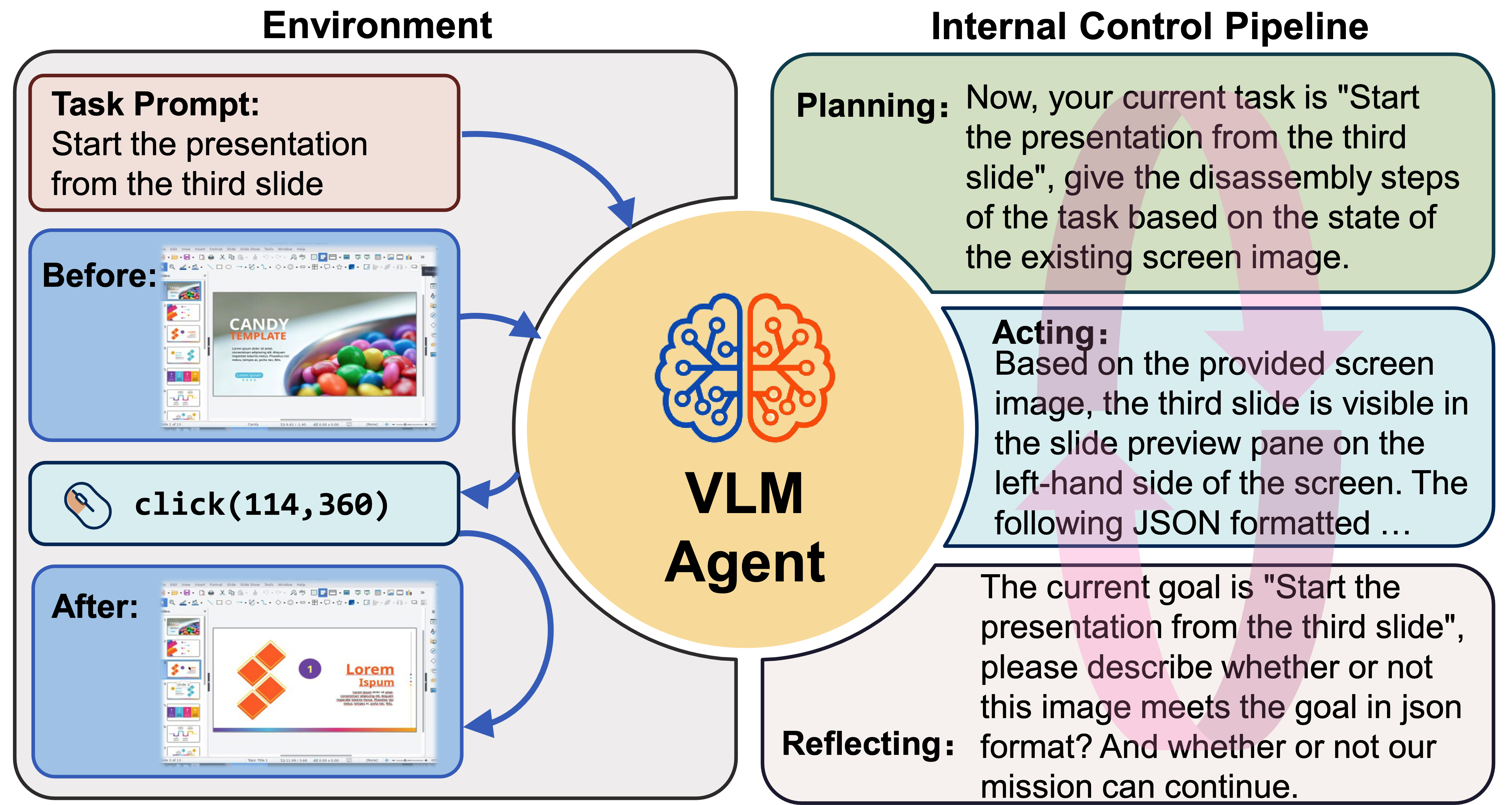
ScreenAgent设计动机
工作原理
ScreenAgent的工作流程遵循"规划-执行-反思"的循环:
- 规划阶段: 代理将用户任务分解为子任务。
- 执行阶段: 代理观察屏幕截图,给出具体的鼠标和键盘操作来执行子任务。
- 反思阶段: 代理观察执行结果,判断当前状态,并决定是继续执行、重试还是调整计划。
这个过程会不断循环,直到任务完成。
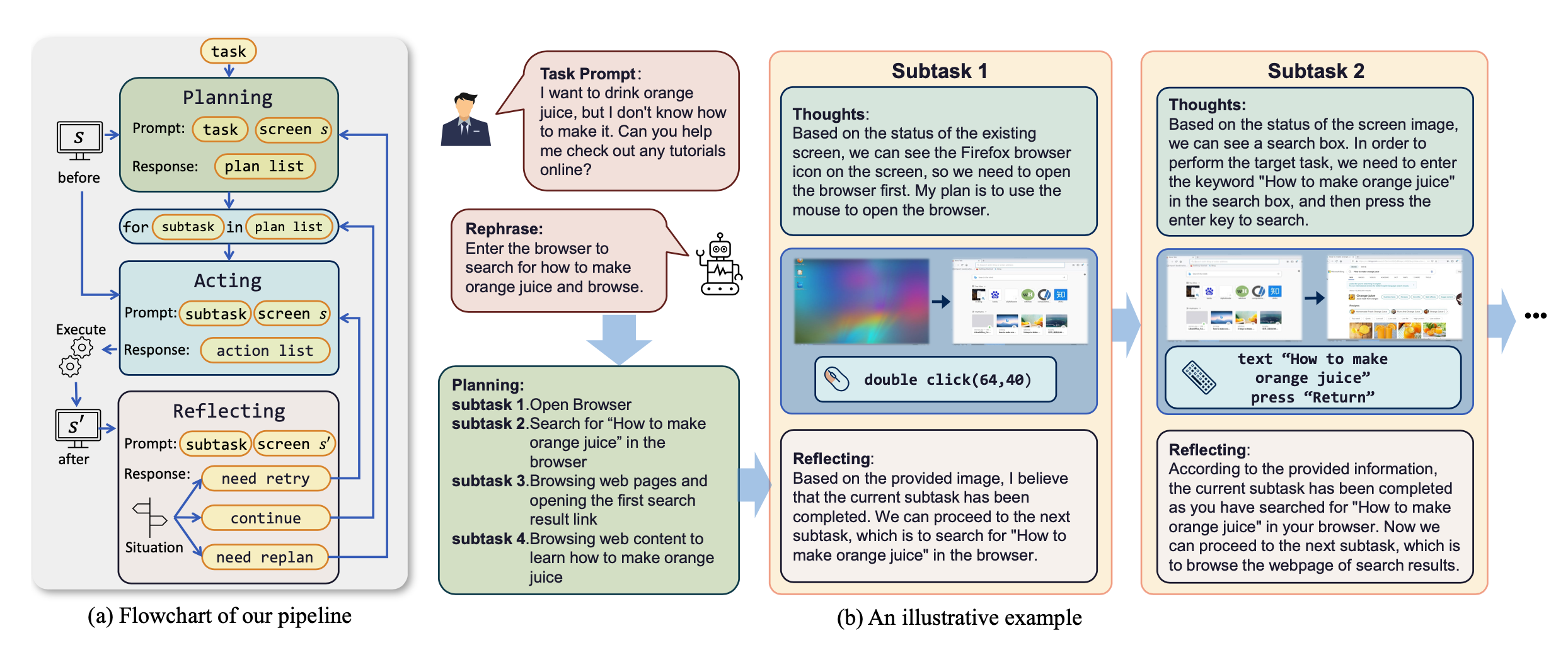
ScreenAgent运行流程
行动空间
ScreenAgent参考了VNC远程桌面连接协议,设计了代理的行动空间,包括最基本的鼠标和键盘操作。大多数鼠标点击操作需要代理给出准确的屏幕坐标位置。与调用特定API完成任务相比,这种方法更加通用,可以应用于各种桌面操作系统和应用程序。
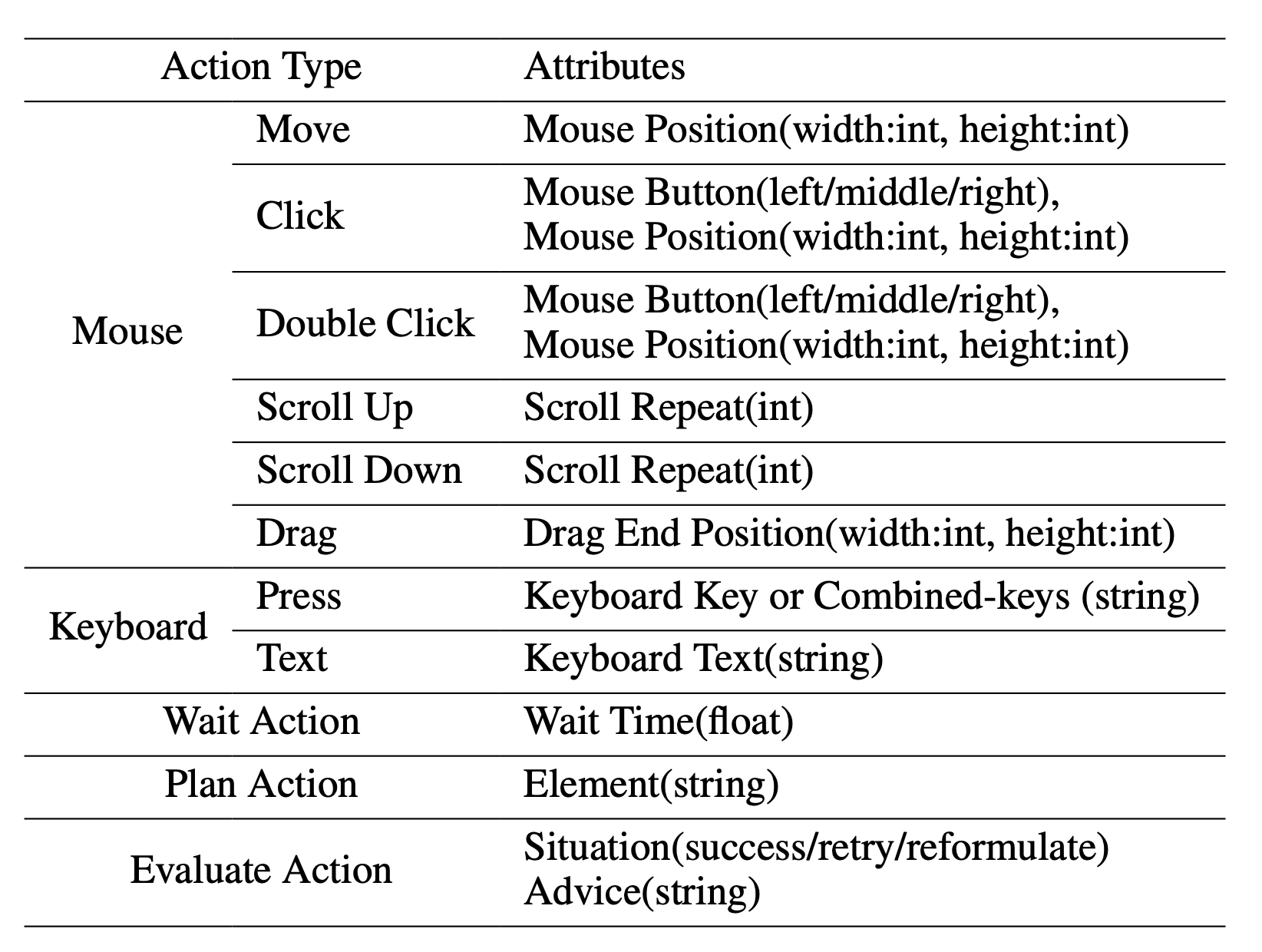
支持的动作类型和动作属性
ScreenAgent数据集
教会AI代理使用计算机并非易事。它需要代理具备多项综合能力,如任务规划、图像理解、视觉定位和工具使用。为此,研究团队手动标注了ScreenAgent数据集。该数据集涵盖了各种日常计算机任务,包括文件操作、网页浏览、游戏娱乐等场景。每个会话都按照上述"规划-执行-反思"的过程构建。
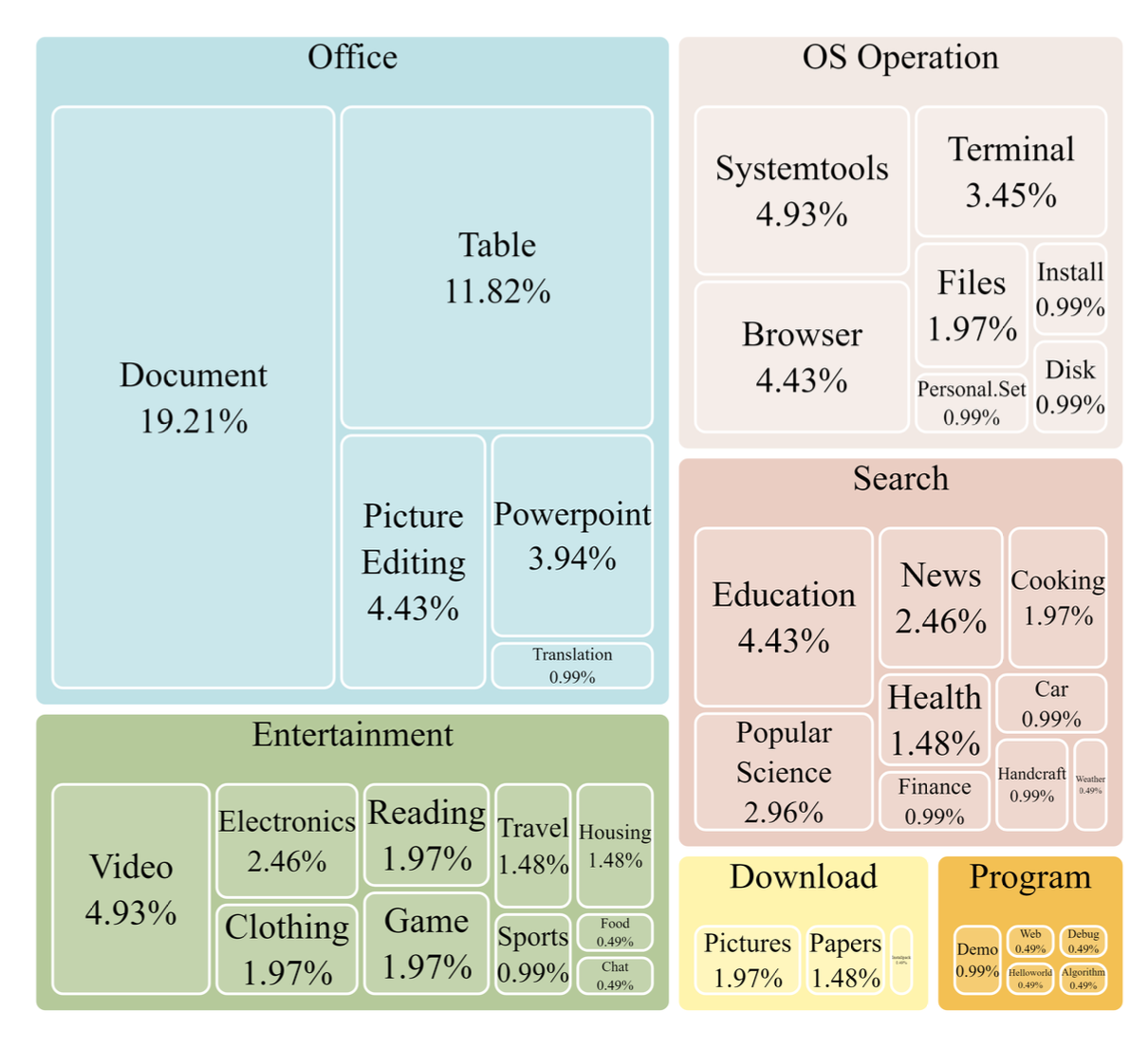
ScreenAgent数据集任务类型分布
项目结构
ScreenAgent项目主要包括以下部分:
ScreenAgent
├── client # 控制器客户端代码
│ ├── prompt # 提示词模板
│ ├── config.yml # 控制器客户端配置文件模板
│ └── tasks.txt # 任务列表
├── data # 包含ScreenAgent数据集和其他视觉定位相关数据集
├── model_workers # VLM推理器
└── train # 模型训练代码
使用指南
要使用ScreenAgent,需要完成以下准备工作:
- 准备被控制的桌面环境
- 准备控制器代码运行环境
- 准备大型模型推理器或API
详细的安装和使用步骤请参考项目的GitHub页面。
运行效果
完成准备工作后,你可以运行控制器:
cd client
python run_controller.py -c config.yml
控制器界面如下图所示。你需要先从左侧双击选择一个任务,然后按下"Start Automation"按钮。控制器将按照规划-执行-反思的流程自动运行。
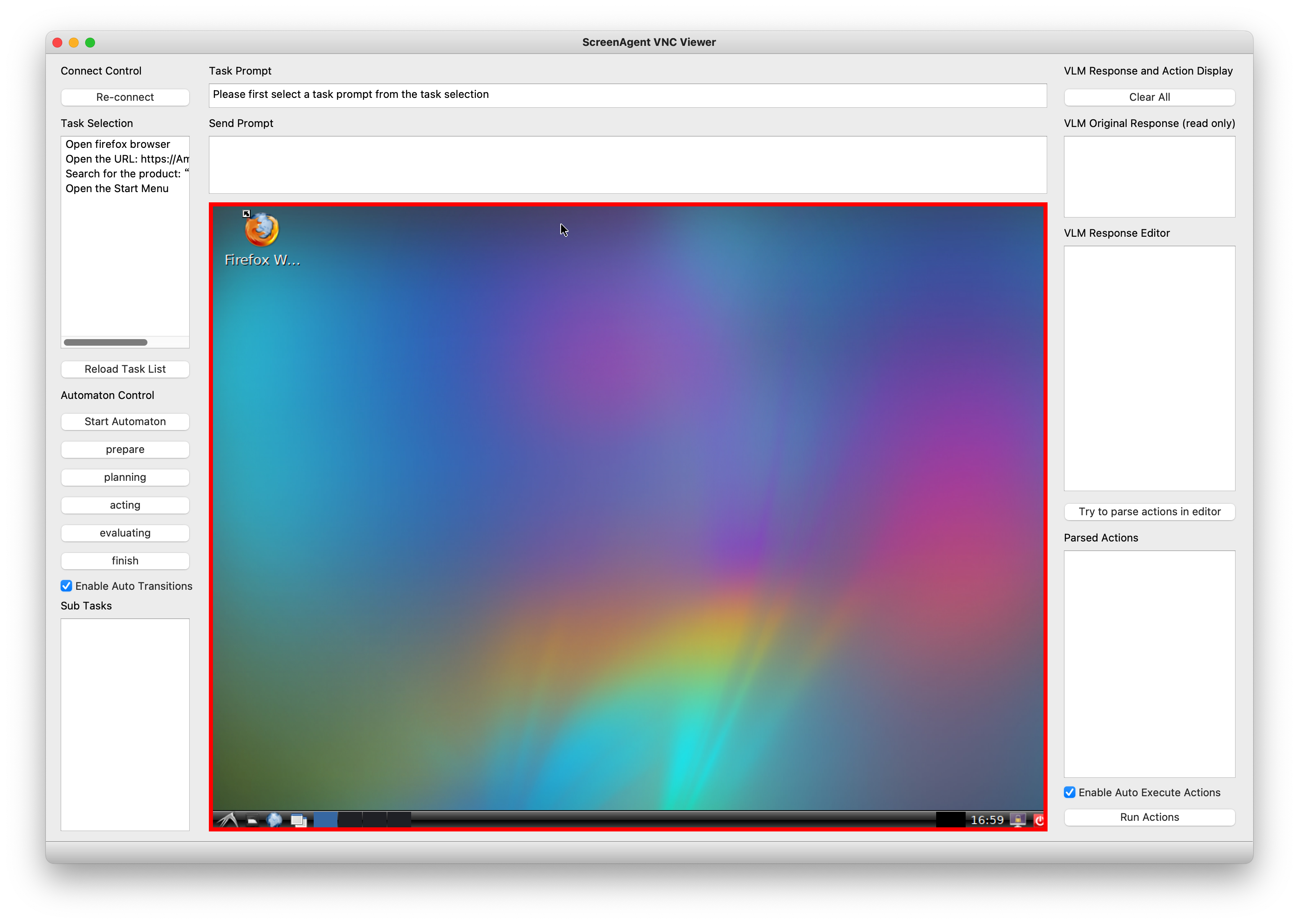
ScreenAgent控制器界面
未来展望
ScreenAgent项目为构建通用型AI代理迈出了重要一步。未来的研究方向包括:
- 提供Hugging Face Transformers权重
- 简化控制器设计,提供无渲染模式
- 集成Gym环境
- 添加技能库以支持更复杂的功能调用
结论
ScreenAgent展示了视觉语言模型在计算机控制领域的巨大潜力。通过创新的环境设计、自动控制流程和专门的数据集,ScreenAgent为构建更加通用和智能的AI助手铺平了道路。这项研究不仅推动了人工智能与人机交互的边界,还为未来更智能、更直观的计算机使用体验提供了可能性。
随着技术的不断发展,我们可以期待看到更多基于ScreenAgent的应用,这些应用将改变我们与计算机交互的方式,提高工作效率,并为各行各业带来革命性的变化。ScreenAgent的成功也为其他研究者提供了宝贵的经验和数据,有望激发更多在这一领域的创新和突破。
ScreenAgent项目代表了人工智能与人机交互领域的一个重要里程碑。它不仅展示了视觉语言模型在实际应用中的潜力,还为构建更智能、更通用的AI助手开辟了新的可能性。随着这项技术的进一步发展和完善,我们可以期待在不久的将来,AI助手能够更自然、更高效地协助我们完成各种复杂的计算机任务,从而彻底改变我们与数字世界的互动方式。









