
SEEM:无处不在的图像分割革命
在计算机视觉领域,图像分割一直是一个既重要又具有挑战性的任务。近日,由来自Microsoft Research和威斯康星大学麦迪逊分校的研究人员提出了一种名为SEEM(Segment Everything Everywhere All at Once)的创新模型,为图像分割带来了革命性的突破。这个模型能够通过多模态提示实现"无处不在"的分割,展现出强大的通用性、交互性和语义理解能力。
SEEM的核心特点
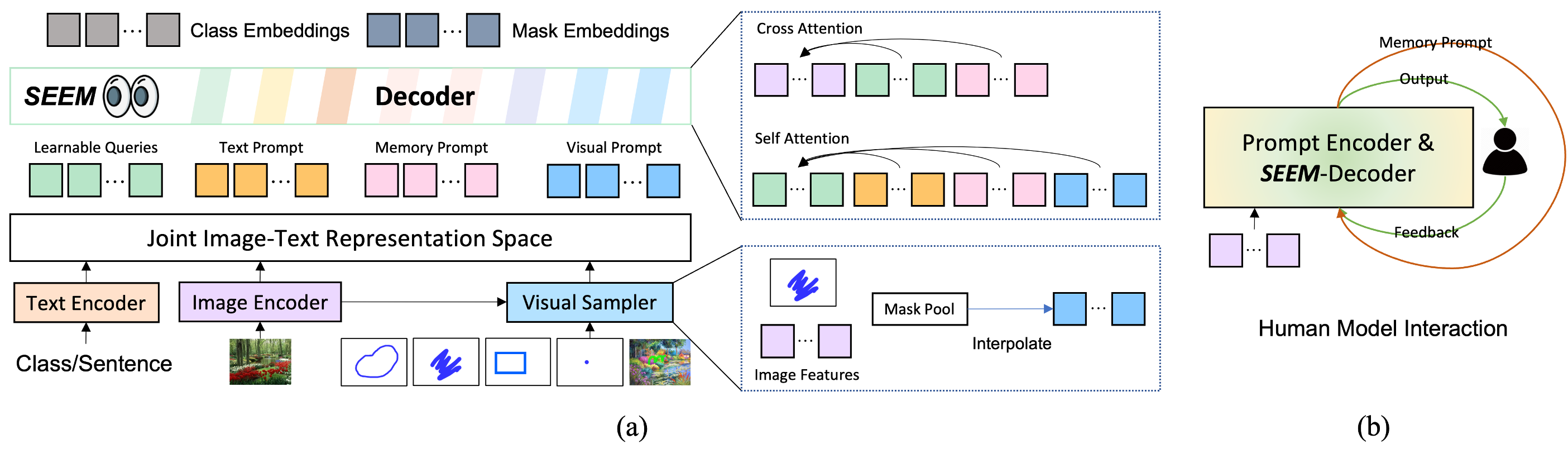
SEEM模型的设计灵感来自于大型语言模型(LLMs)的通用接口,旨在为各种类型的分割任务提供一个统一的交互式多模态接口。它具有四个关键特征:
-
多功能性:SEEM可以处理多种类型的提示,包括点击、框、多边形、涂鸦、文本和参考图像等。这种灵活性使其能够适应不同的用户需求和应用场景。
-
组合性:模型能够处理任何提示的组合,这意味着用户可以通过组合不同类型的提示来实现更精确和复杂的分割任务。
-
交互性:SEEM引入了可学习的记忆提示,能够保存会话历史,从而实现多轮交互。这使得用户可以逐步细化和改进分割结果。
-
语义感知:模型使用文本编码器将文本查询和掩码标签编码到相同的语义空间中,实现开放词汇表分割。这意味着SEEM不仅可以分割图像,还能理解和标记分割对象的语义含义。
SEEM的工作原理
SEEM的核心是一种新颖的解码机制,能够为所有类型的分割任务启用多样化的提示。具体来说:
-
SEEM引入了一种新的视觉提示,统一了不同的空间查询,包括点、框、涂鸦和掩码,甚至可以推广到不同的参考图像。
-
模型学习了文本和视觉提示之间的联合视觉-语义空间,这促进了不同提示类型的动态组合。
-
在解码器中引入了可学习的记忆提示,通过从解码器到图像特征的掩码引导交叉注意力来保留分割历史。
-
使用文本编码器将文本查询和掩码标签编码到相同的语义空间中,实现开放词汇表分割。
这种设计使SEEM能够在单个模型中处理多种分割任务,包括交互式分割、通用分割、指代分割和视频对象分割等。
SEEM的应用示例
SEEM的强大功能可以通过多个应用示例来展示:
- 点击和涂鸦分割:用户可以通过简单的点击或涂鸦操作,生成相应的掩码和类别标签。这在快速选择和标注图像区域时非常有用。

- 文本到掩码:SEEM可以根据用户的文本输入生成掩码,实现多模态人机交互。这对于基于语言描述进行图像分割特别有用。

- 参考图像到掩码:通过在参考图像上简单点击或涂鸦,模型能够在目标图像中分割具有相似语义的对象。这种功能在跨图像对象识别和分割中非常有价值。

-
参考图像到视频掩码:SEEM无需在视频数据上进行训练,就能完美地根据用户指定的查询对视频进行分割。这在视频编辑和分析中有广泛应用。
-
音频到掩码:模型使用Whisper将音频转换为文本提示,然后分割对象。这种多模态能力为语音控制的图像分割开辟了新的可能性。
SEEM与SAM的比较
与目前广受关注的Segment Anything Model (SAM)相比,SEEM在交互和语义层面上覆盖了更广泛的范围:
-
SAM仅支持有限的交互类型(如点和框),而SEEM支持更多样化的提示类型。
-
SAM不输出语义标签,而SEEM能够提供语义感知的预测结果。
-
SEEM具有统一的提示编码器,将所有视觉和语言提示编码到联合表示空间中,支持更通用的用法。
-
SEEM在文本到掩码(基础分割)任务上表现出色,并能输出语义感知的预测结果。

SEEM的技术细节和性能
SEEM在多个数据集上进行了评估,包括COCO、Ref-COCOg、VOC和SBD等。研究人员提供了不同版本的SEEM模型,包括SEEM_v0(支持单个交互对象的训练和推理)和SEEM_v1(支持多个交互对象的训练和推理)。
在COCO数据集上,SEEM_v1使用Focal-L骨干网络取得了56.1的PQ分数、46.3的mAP分数和65.8的mIoU分数。在Ref-COCOg数据集上,同样的模型达到了62.4的cIoU分数、67.8的mIoU分数和76.0的AP50分数。这些结果表明SEEM在各种分割任务上都具有竞争力。
值得注意的是,SEEM仅使用了SAM 1/100的监督数据量,就在交互式分割任务上取得了优于SAM的结果。这突显了SEEM模型设计的效率和有效性。
SEEM的潜在应用
SEEM的多功能性和强大性能为众多应用场景打开了大门:
-
图像编辑和处理:SEEM可以轻松实现精确的对象分割和提取,为图像编辑软件提供更智能的工具。
-
医学图像分析:模型的高精度分割能力可以应用于医学影像,帮助识别和分割复杂的解剖结构或病变区域。
-
自动驾驶:SEEM的实时分割能力可以用于识别道路、行人和其他车辆,提高自动驾驶系统的环境感知能力。
-
增强现实(AR):通过准确分割现实世界的对象,SEEM可以帮助AR应用更好地理解和交互环境。
-
视频内容分析:模型的视频分割能力可用于视频内容的自动标注、分类和检索。
-
机器人视觉:SEEM可以提升机器人的环境感知和物体操作能力,特别是在复杂和动态环境中。
-
地理信息系统(GIS):模型可用于卫星图像和航拍图像的自动分割和分析,助力土地利用分类和城市规划。
未来展望
SEEM的出现标志着图像分割技术迈向了一个新的里程碑。它不仅展示了强大的性能,更重要的是提供了一个灵活、通用的框架,可以适应各种分割任务和应用场景。随着技术的进一步发展,我们可以期待:
-
模型效率的提升:未来的研究可能会关注如何在保持性能的同时减少模型大小和计算需求,使SEEM更适合移动和嵌入式设备。
-
跨模态学习的深化:SEEM已经展示了处理多模态输入的能力,未来可能会进一步加强模型在不同模态间的理解和转换能力。
-
实时性能的优化:对于许多应用来说,实时处理至关重要。提高SEEM的推理速度将是一个重要的研究方向。
-
更广泛的领域适应:虽然SEEM在多个领域都表现出色,但针对特定领域(如医疗、遥感等)的优化和适应仍有很大空间。
-
与大型语言模型的结合:考虑到SEEM的设计灵感来自LLMs,未来可能会看到SEEM与先进的语言模型更紧密的集成,实现更智能的图像理解和交互。
总的来说,SEEM代表了计算机视觉领域的一个重要突破,为图像分割任务带来了前所未有的灵活性和能力。随着技术的不断发展和应用的深入,我们可以期待看到更多基于SEEM的创新应用,推动人工智能和计算机视觉技术向前发展。









