SHAP简介
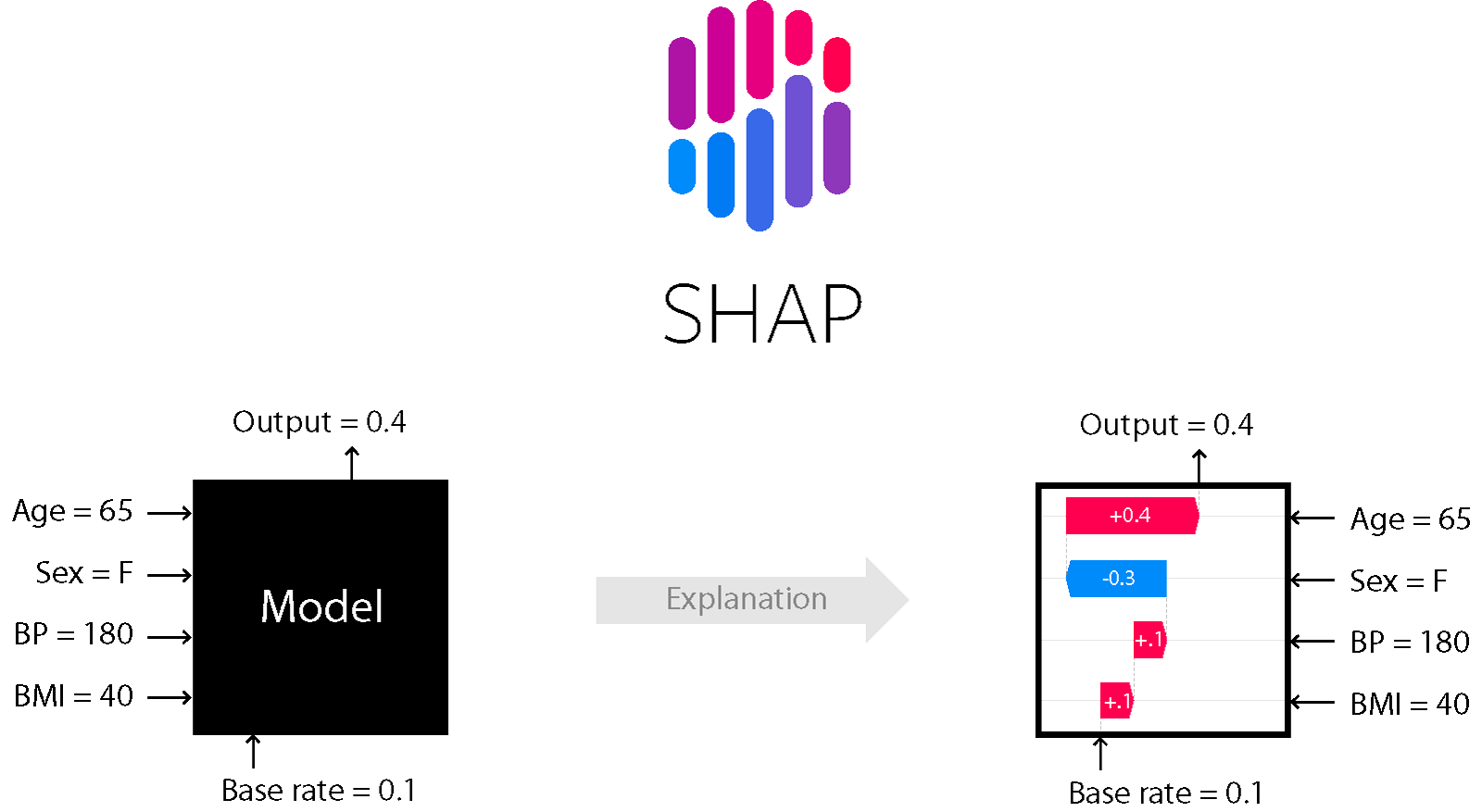
SHAP(SHapley Additive exPlanations)是一种用于解释机器学习模型预测结果的方法,由Scott Lundberg和Su-In Lee于2017年提出。它基于博弈论中的Shapley值概念,为模型的每个特征分配重要性值,从而解释模型的预测过程。
SHAP的核心思想是将模型预测视为一个合作博弈,每个特征都是博弈中的一个参与者。通过计算每个特征对最终预测结果的贡献,SHAP可以量化各个特征的重要性,并提供一致且公平的解释。
SHAP的主要特点
-
模型无关性: SHAP可以应用于任何机器学习模型,包括线性回归、决策树、随机森林、梯度提升模型和神经网络等。
-
局部准确性: SHAP值能够准确反映每个特征对单个预测的贡献。
-
一致性: 当一个特征的实际影响增加时,其SHAP值不会减少。
-
可加性: 所有特征的SHAP值之和等于模型预测值与平均预测值之间的差异。
-
理论基础: SHAP基于坚实的博弈论基础,提供了一种统一的解释框架。
SHAP的工作原理
SHAP通过以下步骤计算特征重要性:
-
对于每个预测,SHAP考虑所有可能的特征子集。
-
对于每个子集,计算有无某个特征时的预测差异。
-
将这些差异加权平均,得到该特征的SHAP值。
-
重复以上步骤,计算所有特征的SHAP值。
SHAP的应用场景
SHAP在多个领域都有广泛应用:
-
金融: 解释信用评分模型,提高决策透明度。
-
医疗: 解释疾病诊断模型,辅助医生决策。
-
营销: 分析客户流失预测模型,制定精准营销策略。
-
推荐系统: 解释推荐算法,提高用户体验。
-
自然语言处理: 解释文本分类或情感分析模型。
SHAP的可视化方法
SHAP提供了多种直观的可视化方法:
1. 摘要图(Summary Plot)
摘要图展示了所有特征的整体重要性分布。

2. 依赖图(Dependence Plot)
依赖图展示了单个特征与SHAP值之间的关系。

3. 力图(Force Plot)
力图展示了单个预测的特征贡献。

4. 决策图(Decision Plot)
决策图展示了特征如何影响从基准值到最终预测的过程。

在Python中使用SHAP
SHAP可以通过Python库轻松使用。以下是一个简单的示例:
import shap
import xgboost as xgb
# 加载数据并训练模型
X, y = shap.datasets.boston()
model = xgb.train({"learning_rate": 0.01}, xgb.DMatrix(X, label=y), 100)
# 解释模型预测
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X)
# 可视化
shap.summary_plot(shap_values, X)
SHAP的优势
-
统一框架: SHAP提供了一种统一的方法来解释不同类型的模型。
-
理论保证: 基于坚实的数学基础,确保解释的一致性和公平性。
-
多样化的可视化: 提供多种直观的可视化方法,便于理解和交流。
-
模型诊断: 帮助识别模型中的潜在问题,如过拟合或特征冗余。
-
提高可解释性: 增强模型的透明度,有助于建立用户信任。
SHAP的局限性
尽管SHAP具有许多优点,但也存在一些局限性:
-
计算复杂度: 对于大型数据集和复杂模型,计算SHAP值可能非常耗时。
-
特征依赖: SHAP假设特征之间是独立的,可能无法完全捕捉特征间的复杂交互。
-
解释的复杂性: 对于高维数据,解释可能变得复杂和难以理解。
-
因果关系: SHAP值反映相关性,而非因果关系,解释时需谨慎。
结论
SHAP为机器学习模型的可解释性提供了一个强大而灵活的工具。通过量化特征重要性并提供直观的可视化,SHAP帮助数据科学家、决策者和最终用户更好地理解模型的行为。随着对AI系统透明度和可解释性要求的不断提高,SHAP在未来将继续发挥重要作用,推动负责任的AI发展。
要深入了解SHAP,可以访问SHAP的官方文档或GitHub仓库。同时,建议结合实际项目实践,探索SHAP在不同场景下的应用,以充分发挥其潜力。











