
SiLLM: 大型语言模型驱动的同声传译新纪元
在人工智能和自然语言处理领域,同声传译一直是一个具有挑战性的任务。随着大型语言模型(LLM)的快速发展,研究人员开始探索如何将LLM的强大能力应用到同声传译中。近日,一个名为SiLLM的创新框架应运而生,它巧妙地结合了大型语言模型和传统同声传译模型的优势,为同声传译技术带来了新的突破。
SiLLM框架简介
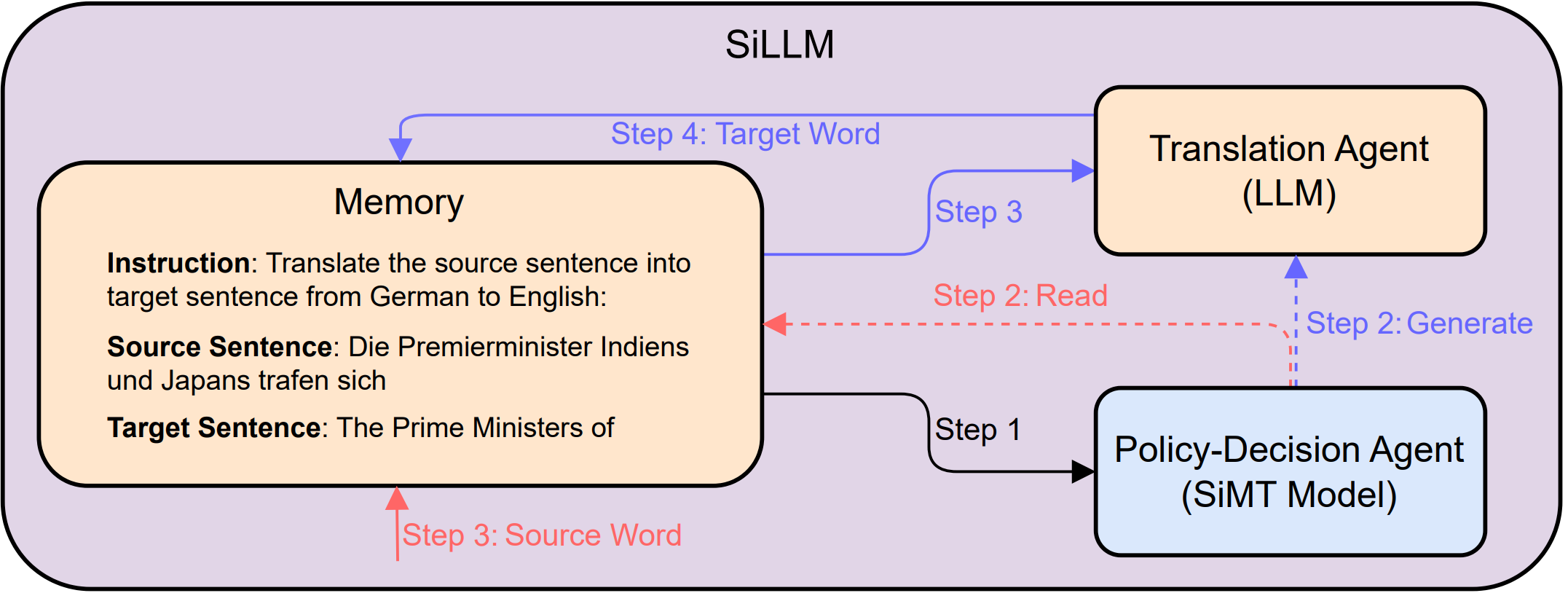
SiLLM(Simultaneous Large Language Model)是一个专为同声传译设计的框架。它的核心思想是将同声传译任务解耦为两个子任务:策略决策和翻译生成。框架采用两个智能体(agent)分别负责这两个子任务,通过协作完成高质量的同声传译。
- 策略决策智能体:由传统的同声传译模型负责,主要决定何时读取源语言输入、何时生成目标语言输出。
- 翻译智能体:利用大型语言模型的强大能力,根据部分源语句生成高质量的翻译。
这种设计充分发挥了两种模型的优势:传统同声传译模型在实时性和策略控制方面表现出色,而大型语言模型则在理解和生成方面具有明显优势。
SiLLM的工作流程
- 输入处理:系统接收源语言的实时输入。
- 策略决策:策略决策智能体根据当前情况决定是继续等待更多输入,还是开始生成翻译。
- 翻译生成:当策略决策智能体给出翻译信号时,翻译智能体(LLM)接收已有的部分源语句,生成对应的目标语言翻译。
- 输出控制:系统根据策略智能体的指示,将翻译结果实时输出。
- 循环迭代:重复上述步骤,直至完成整个源语言输入的翻译。
SiLLM的技术创新
- 任务解耦:将同声传译任务分解为策略决策和翻译生成两个子任务,使得每个子任务都能由最适合的模型来处理。
- 大型语言模型应用:首次将LLM应用于同声传译任务,充分利用其强大的语言理解和生成能力。
- 词级策略适配:提出了一种适用于LLM的词级策略,使得传统同声传译模型的决策可以更好地指导LLM的翻译过程。
- 灵活的训练方法:SiLLM支持使用少量数据对LLM进行微调,使其更好地适应同声传译任务的特点。
SiLLM的实验结果
研究团队在两个数据集上进行了实验,结果表明SiLLM在同声传译任务上取得了显著的性能提升:
- 翻译质量:与传统方法相比,SiLLM生成的翻译更加流畅、准确,更符合目标语言的表达习惯。
- 实时性:SiLLM能够在保证翻译质量的同时,维持较低的延迟,满足同声传译的实时性要求。
- 适应性:通过少量数据的微调,SiLLM可以快速适应不同领域和风格的翻译任务。
SiLLM的潜在应用
- 国际会议:为多语言会议提供高质量的实时翻译服务,促进跨语言交流。
- 媒体直播:为新闻直播、体育赛事等提供实时的多语言字幕或配音。
- 商务谈判:辅助跨国商务活动,减少语言障碍带来的沟通成本。
- 教育领域:支持多语言在线课程,帮助学生克服语言障碍,获取全球优质教育资源。
- 旅游行业:为游客提供实时翻译服务,提升旅行体验。
SiLLM的未来发展方向
- 多模态融合:结合视觉和听觉信息,提升翻译的准确性和上下文理解能力。
- 个性化适配:开发针对不同用户和场景的个性化翻译模型。
- 低资源语言支持:扩展SiLLM的语言覆盖范围,特别是对低资源语言的支持。
- 效率优化:进一步降低模型的计算复杂度,使其能够在移动设备上实时运行。
- 伦理与隐私:加强对翻译过程中的隐私保护,确保敏感信息的安全。
结语
SiLLM的出现标志着同声传译技术进入了一个新的阶段。通过巧妙地结合大型语言模型和传统同声传译模型的优势,SiLLM为提高翻译质量和实时性开辟了新的道路。随着技术的不断发展和完善,我们有理由相信,SiLLM将在推动全球跨语言交流、促进文化理解方面发挥重要作用。未来,随着更多研究的深入和应用场景的拓展,SiLLM有望成为连接不同语言和文化的重要桥梁,为构建一个更加开放、包容的全球化社会做出贡献。









