
SOFT简介
SOFT(Softmax-free Transformer)是由复旦大学和萨里大学的研究人员共同提出的一种新型Transformer模型。它的主要创新点在于去除了传统Transformer中的softmax操作,从而将自注意力机制的计算复杂度从二次方降低到线性。这一改进使得SOFT在保持强大性能的同时,大大提高了计算效率。
SOFT最初于2021年在NeurIPS会议上发表,后来又在2024年IJCV期刊上发表了扩展版本。目前,SOFT已经在图像分类、目标检测和语义分割等多个计算机视觉任务上展现出了卓越的性能。
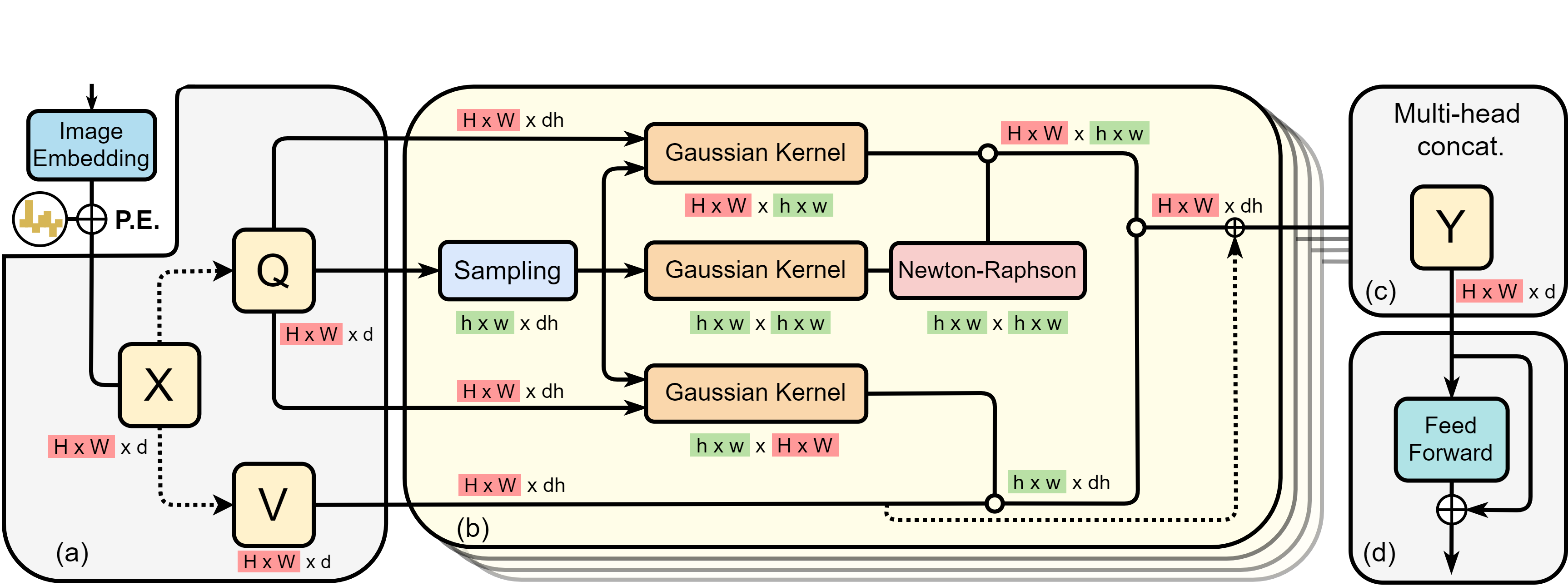
SOFT的主要特点
-
线性复杂度: 通过去除softmax操作,SOFT将自注意力机制的计算复杂度从O(n^2)降低到O(n),其中n是序列长度。这使得SOFT能够更高效地处理长序列输入。
-
强大的泛化能力: SOFT提出了一种归一化的无softmax自注意力机制,进一步增强了模型的泛化能力。
-
多任务适用性: SOFT不仅在图像分类任务上表现出色,还被成功应用于目标检测和语义分割等下游任务。
-
灵活的实现: SOFT提供了PyTorch和CUDA两种实现版本,可以根据具体需求选择使用。
SOFT在图像分类任务上的表现
SOFT在ImageNet-1K数据集上进行了广泛的实验,展示了其在不同模型规模下的优异性能:
- SOFT-Tiny (13M参数): 79.3% Top-1准确率
- SOFT-Small (24M参数): 82.2% Top-1准确率
- SOFT-Medium (45M参数): 82.9% Top-1准确率
- SOFT-Large (64M参数): 83.1% Top-1准确率
- SOFT-Huge (87M参数): 83.3% Top-1准确率
这些结果表明,SOFT在参数量相近的情况下,能够达到或超过其他先进的Transformer模型的性能。
SOFT在目标检测任务中的应用
SOFT还被应用于COCO数据集的目标检测任务中,并与RetinaNet和Mask R-CNN等经典检测框架结合:
- SOFT-Tiny-Norm + RetinaNet: 40.0 box mAP
- SOFT-Tiny-Norm + Mask R-CNN: 41.2 box mAP, 38.2 mask mAP
- SOFT-Large-Norm + RetinaNet: 45.3 box mAP
- SOFT-Large-Norm + Mask R-CNN: 47.0 box mAP, 42.2 mask mAP
这些结果显示,SOFT作为backbone能够有效提升目标检测模型的性能。
SOFT在语义分割任务上的表现
在ADE20K数据集的语义分割任务上,SOFT同样展现出了强大的性能:
- SOFT-Small-Norm + UperNet: 46.2 mIoU
- SOFT-Medium-Norm + UperNet: 48.0 mIoU
这进一步证明了SOFT在各种视觉任务中的通用性和有效性。
SOFT的实现与使用
SOFT的源代码已在GitHub上开源[1],研究人员和开发者可以方便地使用和扩展这一模型。主要步骤包括:
-
环境配置:
pip install timm==0.3.2 pip install torch>=1.7.0 -
数据准备: 按照标准的ImageNet数据集格式组织训练和验证数据。
-
安装SOFT:
git clone https://github.com/fudan-zvg/SOFT.git python -m pip install -e SOFT -
模型训练:
./dist_train.sh ${GPU_NUM} --data ${DATA_PATH} --config ${CONFIG_FILE} -
模型评估:
./dist_train.sh ${GPU_NUM} --data ${DATA_PATH} --config ${CONFIG_FILE} --eval_checkpoint ${CHECKPOINT_FILE} --eval
SOFT提供了多个预训练模型,用户可以直接下载使用,也可以根据自己的需求进行微调。
SOFT的未来发展
作为一种高效且性能强大的Transformer变体,SOFT为深度学习模型在处理大规模数据和复杂任务时提供了新的可能性。未来,SOFT可能会在以下几个方面继续发展:
-
更大规模模型: 随着硬件性能的提升,可以尝试训练更大规模的SOFT模型,探索其性能上限。
-
跨模态应用: 将SOFT扩展到自然语言处理、语音识别等其他领域,研究其在跨模态任务中的表现。
-
模型压缩: 研究如何在保持性能的同时,进一步减小模型大小和计算复杂度,使SOFT更适合在资源受限的环境中部署。
-
结构优化: 探索SOFT架构的其他可能改进,如引入新的注意力机制或优化网络结构。
-
与其他技术结合: 将SOFT与其他先进技术(如神经架构搜索、知识蒸馏等)结合,进一步提升模型性能。
结论
SOFT作为一种创新的Transformer模型,通过去除softmax操作实现了线性复杂度,在保持强大性能的同时大大提高了计算效率。它在图像分类、目标检测和语义分割等多个视觉任务上都取得了优异的结果,展现出了广阔的应用前景。
随着深度学习模型不断向更大规模、更高效率发展,SOFT这类能够有效处理长序列输入的模型将变得越来越重要。我们期待看到SOFT在未来能够在更多领域发挥作用,推动人工智能技术的进一步发展。
[1] SOFT GitHub仓库: https://github.com/fudan-zvg/SOFT


















