
SoundStorm-PyTorch简介
SoundStorm-PyTorch是由人工智能研究者Phil Wang在GitHub上开源的项目,旨在实现Google DeepMind提出的高效并行音频生成技术SoundStorm。该项目将SoundStorm的核心思想移植到了PyTorch深度学习框架中,为研究人员和开发者提供了一个易于使用和扩展的SoundStorm实现。
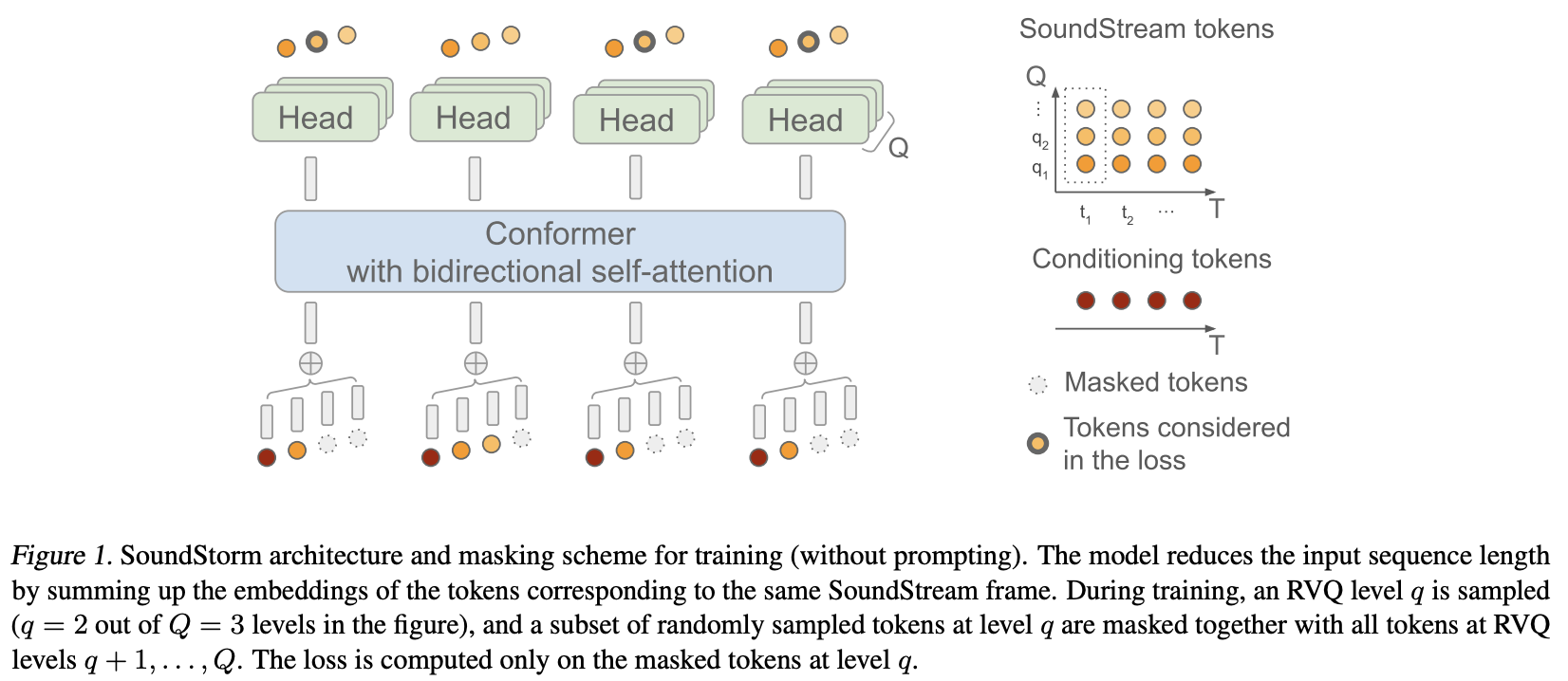
SoundStorm的核心思想是将MaskGiT (Masked Generative Image Transformer)技术应用于SoundStream生成的残差向量量化(RVQ)码,从而实现高效的并行音频生成。相比于传统的自回归生成方法,SoundStorm能够在保持音频质量的同时,大幅提升生成速度和一致性。
技术原理
SoundStorm-PyTorch的实现主要基于以下几个关键技术:
- SoundStream: 一种神经音频编解码器,用于将原始音频压缩为离散的RVQ码。
- MaskGiT: 一种用于图像生成的掩码生成技术,SoundStorm将其应用于音频领域。
- Conformer: 一种结合了卷积神经网络和Transformer的架构,特别适合处理音频数据。
- 并行解码: 通过置信度引导的并行解码策略,大幅提升生成速度。
SoundStorm-PyTorch的工作流程大致如下:
- 使用预训练的SoundStream模型将原始音频编码为RVQ码。
- 将RVQ码输入到基于Conformer的Transformer模型中。
- 使用MaskGiT策略进行训练,学习音频的上下文关系。
- 生成时,通过多步并行解码快速生成高质量音频。
主要特性
SoundStorm-PyTorch具有以下主要特性:
- 高效生成: 相比传统自回归方法,生成速度提升约100倍。
- 音质保证: 生成的音频质量与自回归方法相当。
- 一致性强: 在语音和声学条件上保持更高的一致性。
- 灵活性强: 支持直接训练原始音频,也可以使用预编码的RVQ码。
- 可扩展性: 易于集成文本到语义的转换模块,实现完整的文本到语音系统。
安装和使用
要使用SoundStorm-PyTorch,首先需要通过pip安装该库:
pip install soundstorm-pytorch
以下是一个基本的使用示例:
import torch
from soundstorm_pytorch import SoundStorm, ConformerWrapper
conformer = ConformerWrapper(
codebook_size = 1024,
num_quantizers = 12,
conformer = dict(
dim = 512,
depth = 2
),
)
model = SoundStorm(
conformer,
steps = 18, # 18 steps, as in original maskgit paper
schedule = 'cosine' # currently the best schedule is cosine
)
# 使用预编码的RVQ码进行训练
codes = torch.randint(0, 1024, (2, 1024, 12)) # (batch, seq, num residual VQ)
loss, _ = model(codes)
loss.backward()
# 生成新的音频
generated = model.generate(1024, batch_size = 2) # (2, 1024)
高级功能
SoundStorm-PyTorch还支持更高级的功能,如直接在原始音频上训练和生成:
import torch
from soundstorm_pytorch import SoundStorm, ConformerWrapper, SoundStream
# 初始化SoundStream和SoundStorm模型
soundstream = SoundStream(
codebook_size = 1024,
rq_num_quantizers = 12,
attn_window_size = 128,
attn_depth = 2
)
model = SoundStorm(
conformer,
soundstream = soundstream
)
# 训练
audio = torch.randn(2, 10080)
loss, _ = model(audio)
loss.backward()
# 生成
generated_audio = model.generate(seconds = 30, batch_size = 2)
未来发展
SoundStorm-PyTorch项目仍在积极开发中,计划中的功能包括:
- 集成完整的SoundStream模块
- 支持可变长度序列的训练和生成
- 添加交叉注意力和自适应层归一化条件
- 开发命令行工具界面
总结
SoundStorm-PyTorch为研究人员和开发者提供了一个强大而灵活的工具,用于探索和实现高效的并行音频生成。通过结合最新的深度学习技术,如MaskGiT和Conformer,该项目为音频生成领域带来了新的可能性。随着项目的不断发展和完善,我们可以期待看到更多基于SoundStorm的创新应用,如高质量的文本到语音系统、音乐生成等。
SoundStorm-PyTorch的开源不仅推动了音频生成技术的发展,也为整个AI社区提供了宝贵的学习和研究资源。无论是对音频处理感兴趣的研究人员,还是希望在实际应用中使用高效音频生成的开发者,都可以从这个项目中获得启发和帮助。










