
SqueezeLLM简介
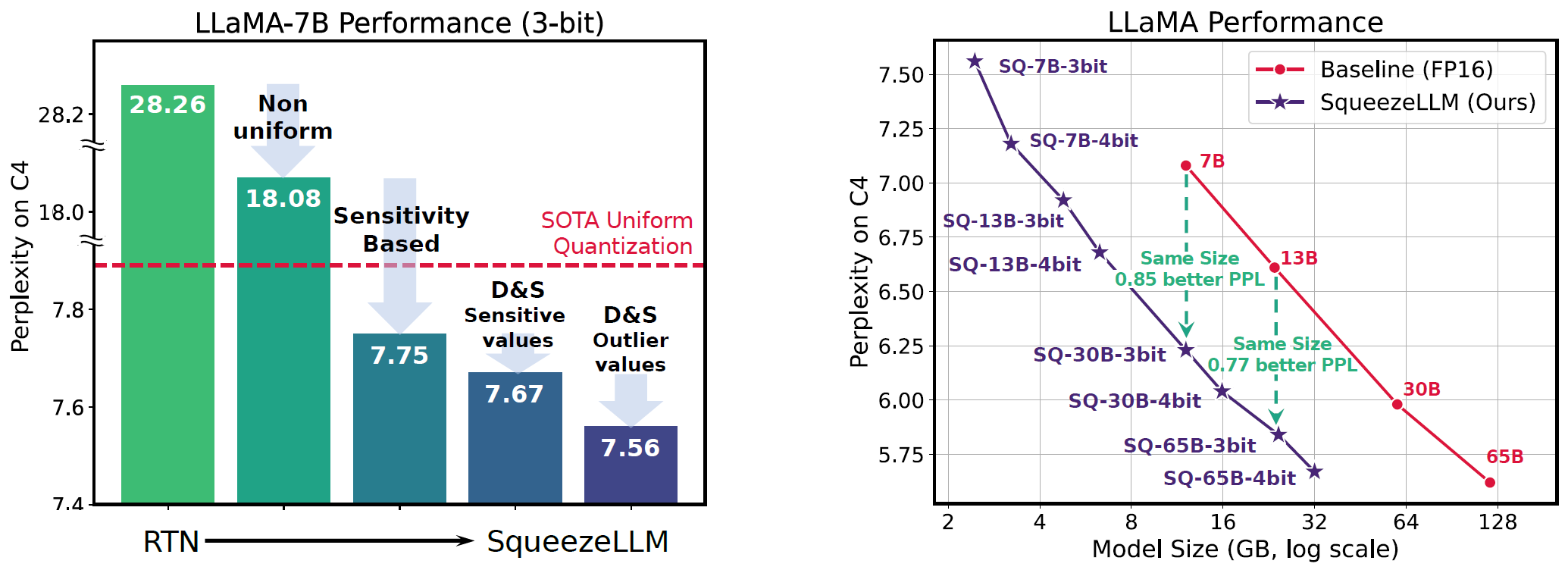
SqueezeLLM是由加州大学伯克利分校研究人员开发的一种新型量化方法,旨在实现大语言模型(LLM)的高效、准确推理。它通过密集-稀疏量化技术,在保持模型性能的同时大幅降低内存占用和推理延迟。
核心技术
SqueezeLLM主要包含以下三个核心技术:
-
敏感权重识别:识别对模型输出影响较大的权重参数。
-
密集-稀疏分解:将敏感权重以稀疏格式存储,其余参数进行深度量化。
-
非均匀量化:采用基于敏感度的非均匀量化方案,提高量化性能。
通过这些技术,SqueezeLLM可以将LLM压缩到3-4位精度,同时保持接近原始模型的性能。
项目资源
- GitHub仓库: SqueezeAILab/SqueezeLLM
- 论文: SqueezeLLM: Dense-and-Sparse Quantization
- 预训练模型: Hugging Face模型仓库
使用指南
安装
git clone https://github.com/SqueezeAILab/SqueezeLLM
cd SqueezeLLM
pip install -e .
cd squeezellm
python setup_cuda.py install
运行示例
以LLaMA 7B模型为例:
CUDA_VISIBLE_DEVICES=0 python llama.py {model_path} c4 --wbits 3 --load sq-llama-7b-w3-s0.pt --eval
支持的模型
SqueezeLLM支持多种流行的LLM模型,包括:
- LLaMA (7B-65B)
- LLaMA-2 (7B-13B)
- Vicuna (7B-13B)
- Mistral (7B)
- XGen (7B)
- OPT (1.3B-30B)
每种模型都提供了3位和4位量化版本,以及不同稀疏度的变体。
性能评估
根据论文报告,SqueezeLLM可以实现:
- 高达4-5倍的模型压缩率
- 最高2.3倍的推理加速
- 在相同内存约束下,比现有方法提高2.1倍的困惑度
更多资源
SqueezeLLM为高效部署大型语言模型提供了一个强大的解决方案。通过本文的资源汇总,希望能帮助读者快速上手这一技术,并在实际应用中充分发挥其优势。










