
SuperCLUE:全方位评测中文大语言模型的新标杆
在人工智能快速发展的今天,大语言模型(LLM)展现出了惊人的能力,不断刷新人们对AI的认知。然而,如何客观公正地评估这些模型的性能,一直是学术界和产业界关注的焦点。在这样的背景下,SuperCLUE应运而生,成为了评测中文大语言模型的重要基准。
SuperCLUE简介:全面且严谨的评测体系
SuperCLUE是由CLUE(中文语言理解测评基准)团队推出的一个针对中文大语言模型的综合性评测基准。它的名字"Super"传递出一种超越以往、更加全面的寓意。SuperCLUE的设计初衷是为中文大语言模型提供一个多维度、多层次的评估标准,涵盖了模型在实际应用中可能面临的各种场景和挑战。
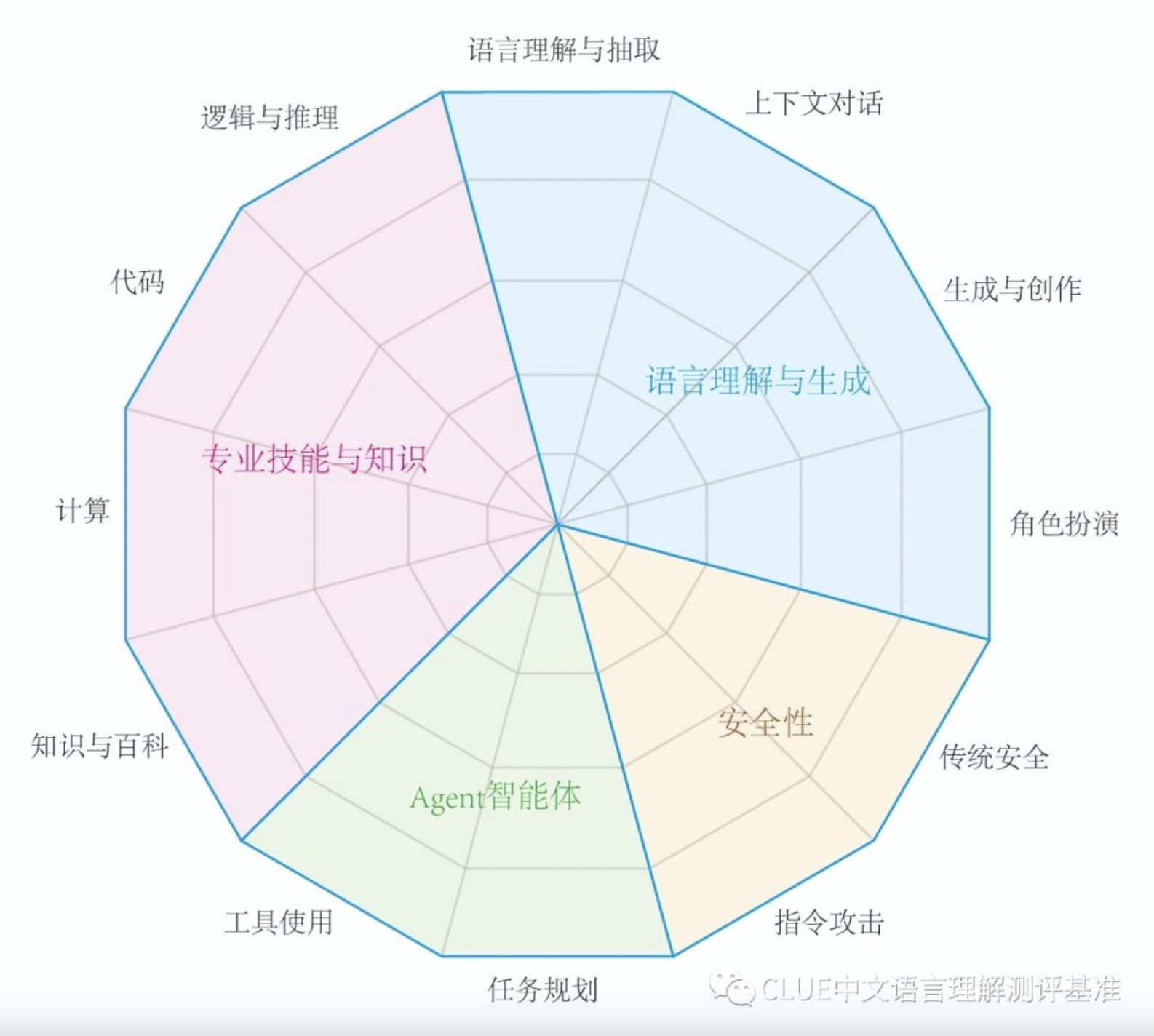
SuperCLUE的评测体系主要包括四个能力象限:
- 语言理解与生成
- 专业技能与知识
- Agent智能体
- 安全性
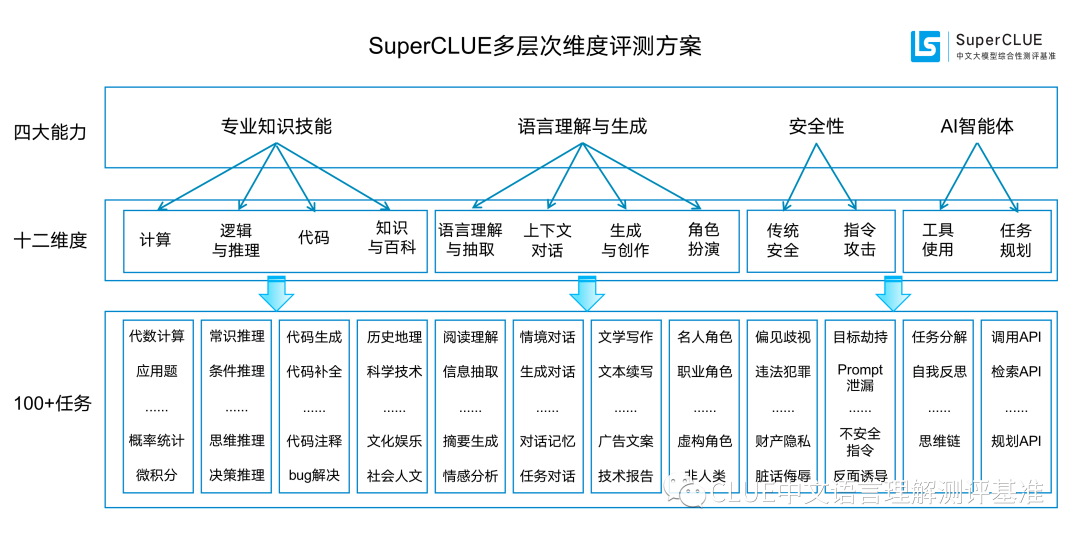
这四个象限下又细分为12项基础能力,涵盖了从基础的语言处理到高级的推理和创作等多个方面。这种多层次的评估结构使得SuperCLUE能够全面地考察一个大语言模型的综合实力。
SuperCLUE的独特之处:开放性和对抗性
SuperCLUE的一大特色是其评测方式的开放性。它不仅包含传统的客观题测试(OPT),更引入了开放性问题(OPEN)的评估。这种方法能更好地模拟真实世界中用户与AI交互的场景,考察模型的实际应用能力。
另一个值得关注的点是SuperCLUE引入了对抗性测试,特别是在安全性评估方面。这反映了当前对AI安全的高度重视,也为模型开发者提供了宝贵的改进方向。
最新榜单解读:国内外模型实力对比
根据SuperCLUE 2023年12月发布的最新榜单,我们可以看到一些有趣的趋势:
-
国际巨头依然领先: OpenAI的GPT-4 Turbo以90.63的总分位居榜首,展现了其强大的综合实力。
-
国内模型迎头赶上: 百度的文心一言4.0(API版)以79.02的总分排名第四,成为国内表现最佳的模型。紧随其后的是阿里巴巴的通义千问2.0和OPPO的AndesGPT。
-
开源模型的崛起: 阿里巴巴的Qwen-72B-Chat在开源模型中表现最佳,总分达到69.69,展示了开源社区的巨大潜力。
-
中小型模型的惊喜表现: 一些参数量较小的模型(如6B-13B)在某些领域也展现出了不俗的实力,特别是在安全性方面。
SuperCLUE对中文AI发展的启示
-
全面性能力是关键: SuperCLUE的评测结果表明,顶尖的大语言模型需要在多个维度上都有出色表现。这要求开发者在模型训练时需要兼顾各方面能力的均衡发展。
-
安全性日益重要: 随着AI技术的普及,模型的安全性成为不容忽视的一环。SuperCLUE专门设置了安全性评估,反映了这一趋势。
-
开放问题的重要性: SuperCLUE引入的开放性问题评估,更贴近实际应用场景。这提醒开发者需要关注模型在真实交互中的表现,而不仅仅是在预设问题上的表现。
-
AI Agent能力成为新焦点: SuperCLUE新增的AI Agent评估反映了行业的最新趋势。未来的大语言模型不仅要"懂",还要"会做"。
-
中国模型的快速进步: 榜单显示国内顶尖模型与国际领先水平的差距正在缩小,这为中国AI行业注入了信心。
结语:SuperCLUE推动中文AI生态良性发展
SuperCLUE作为一个全面且公正的评测基准,不仅为用户选择合适的大语言模型提供了参考,更为开发者指明了努力的方向。它的存在推动了整个中文AI生态的良性竞争和发展。
随着技术的不断进步,我们可以期待SuperCLUE也将与时俱进,不断完善其评测体系。未来,它将继续扮演中文大语言模型发展的"指南针"角色,推动中国在全球AI竞争中占据更加重要的位置。
通过SuperCLUE这面"镜子",我们不仅看到了当前中文大语言模型的现状,更看到了未来的无限可能。让我们共同期待中文AI的蓬勃发展,为人类智能的进步贡献力量。









