
SuperGradients: 易于使用的顶级计算机视觉模型训练库
SuperGradients是一个功能强大而易于使用的深度学习训练库,专注于计算机视觉任务。它的目标是让研究人员和工程师能够快速训练出高性能的计算机视觉模型,并轻松将其部署到生产环境中。
主要特性
SuperGradients提供了以下主要特性:
-
预训练模型库:包含大量最先进的预训练模型,覆盖图像分类、目标检测、语义分割等多个任务。
-
易于使用的训练API:只需几行代码即可开始训练或微调模型。
-
生产就绪:所有模型都兼容TensorRT、OpenVINO等部署工具,可以轻松部署到生产环境。
-
分布式训练:内置对分布式数据并行(DDP)训练的支持,可以轻松进行多GPU训练。
-
丰富的训练功能:支持知识蒸馏、量化感知训练、后训练量化等高级训练技术。
-
可扩展性:易于添加自定义模型、损失函数、数据增强等。
-
实验管理:集成了W&B、ClearML等流行的实验跟踪工具。
支持的任务
SuperGradients支持多种计算机视觉任务:
- 图像分类
- 目标检测
- 语义分割
- 姿态估计
对于每种任务,SuperGradients都提供了多种SOTA模型架构和预训练权重。
快速上手
使用SuperGradients非常简单,只需几行代码即可开始训练:
from super_gradients import Trainer
from super_gradients.training import models
# 创建trainer对象
trainer = Trainer("my_experiment")
# 加载预训练模型
model = models.get("resnet18", num_classes=10, pretrained_weights="imagenet")
# 开始训练
trainer.train(model=model,
training_params={...},
train_loader=train_loader,
valid_loader=valid_loader)
高级功能
除了基础训练外,SuperGradients还支持许多高级功能:
-
知识蒸馏:使用大模型指导小模型学习,提升小模型性能。
-
量化感知训练:在训练过程中进行量化,以获得更好的量化模型。
-
后训练量化:对已训练好的模型进行量化,减小模型体积。
-
分布式训练:支持多GPU分布式训练,大幅提升训练速度。
-
自定义回调:可以在训练过程中插入自定义逻辑。
-
实验跟踪:集成了W&B、ClearML等工具,方便跟踪和管理实验。
丰富的模型库
SuperGradients实现了大量经典和最新的深度学习模型:
- 分类:ResNet、MobileNet、EfficientNet等
- 检测:YOLO系列、SSD等
- 分割:DeepLabV3、UNet等
- 姿态估计:YOLO-NAS-POSE等
所有模型都提供了预训练权重,可以直接用于推理或微调。
部署就绪
SuperGradients的一大特色是所有模型都是"生产就绪"的。它们可以轻松转换为ONNX格式,并与TensorRT、OpenVINO等推理加速工具兼容。这大大简化了将模型部署到实际应用中的过程。
活跃的开发
SuperGradients是一个活跃维护的开源项目,持续不断地添加新功能和模型。最新版本已经支持了YOLO-NAS和YOLO-NAS-POSE等最新的模型架构。
结语
SuperGradients为计算机视觉任务提供了一个全面而易用的训练框架。无论是研究人员还是工程师,都可以利用SuperGradients快速构建和训练高性能的视觉模型。它将继续发展,为计算机视觉领域带来更多创新。
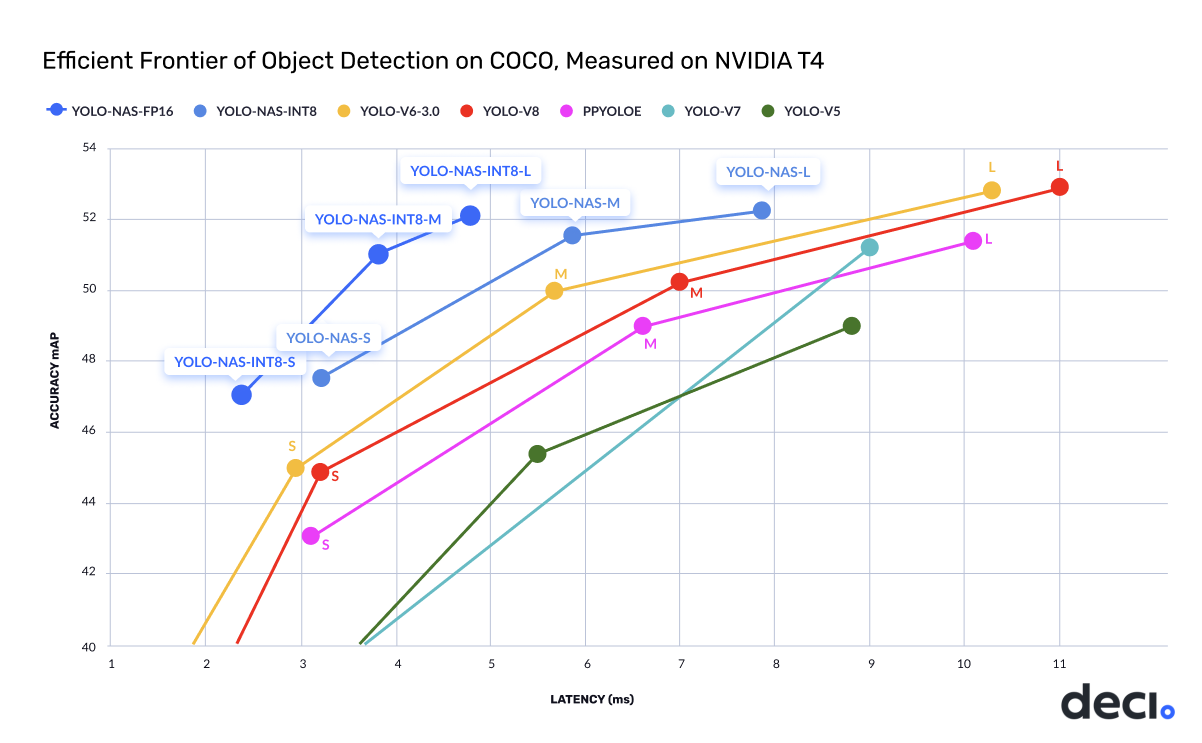
上图展示了YOLO-NAS模型系列在COCO数据集上的性能,相比其他YOLO模型具有显著优势。
SuperGradients正在成为计算机视觉领域一个重要的开源工具,值得所有从事相关工作的人关注和使用。欢迎访问SuperGradients GitHub仓库了解更多信息并参与项目开发。









