
text-embeddings-inference入门指南 - 高性能文本嵌入推理解决方案
Text Embeddings Inference (TEI)是Hugging Face推出的一款高性能文本嵌入推理工具包,专门用于部署和服务开源文本嵌入模型。TEI为最流行的模型(如FlagEmbedding、Ember、GTE和E5等)提供高性能的嵌入提取能力,可以显著提升检索增强生成(RAG)系统的性能。
TEI的主要特性
- 无需模型图编译步骤,简化部署流程
- 支持小型Docker镜像和快速启动,实现真正的无服务器能力
- 基于token的动态批处理,优化推理资源利用
- 利用Flash Attention、Candle和cuBLASLt等技术优化Transformer推理
- 使用Safetensors加载权重,加快启动速度
- 支持分布式追踪和Prometheus指标导出,适用于生产环境
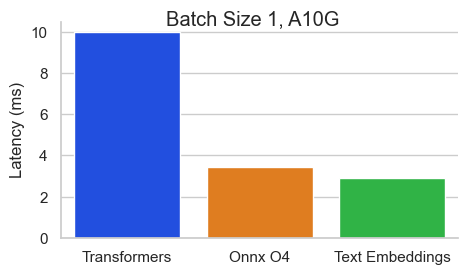
快速上手
- 使用Docker运行TEI:
model=BAAI/bge-large-en-v1.5
volume=$PWD/data
docker run --gpus all -p 8080:80 -v $volume:/data --pull always \
ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $model
- 发送嵌入请求:
curl 127.0.0.1:8080/embed \
-X POST \
-d '{"inputs":"What is Deep Learning?"}' \
-H 'Content-Type: application/json'
支持的模型和硬件
TEI支持多种流行的文本嵌入模型,如BERT、XLM-RoBERTa、Mistral等。详细的模型列表可参考MTEB排行榜。
在硬件方面,TEI支持CPU和主流NVIDIA GPU(Turing、Ampere、Ada Lovelace、Hopper架构)。
更多学习资源
通过使用TEI,您可以轻松地在本地或云端部署高性能的文本嵌入服务,为RAG系统提供低延迟、高吞吐量的嵌入能力,从而显著提升下游任务的性能。无论是用于语义搜索、文档分类还是其他NLP应用,TEI都是一个值得尝试的强大工具。










